First, you need to learn how to ask good questions, and here are some of the resources that will help you to do so:
https://developers.hive.io/apidefinitions/
https://hive.hivesigner.com/
(Kudos to @inertia and @good-karma)
This set of API calls is far from perfect, but for now it has to be enough for general purpose API nodes.
The big, the slow, and the ugly.
Back in the days, we used to run a so-called “full node”, that is a single steemdLOW_MEMORY_NODE=OFF and CLEAR_VOTES=OFF and configured with all the plugins you can get.
It required a lot of RAM, it replayed for ages, and it was a huge pain to keep it running.
Our code is great for running blockchain. It’s not equally efficient when it has to answer complex questions.
Current architecture
The idea is to move the workload requiring complex queries out of our blockchain nodes.
+----------+
| <-----------------+ @ @@@@@@ ,@@@@@%
| Hivemind | | @@@@ (@@@@@* @@@@@@
+-------+ | <-------+ | %@@@@@@ @@@@@@ %@@@@@,
| | +-----^----+ | | @@@@@@@@@@ @@@@@@ @@@@@@
| redis | | | | ,@@@@@@@@@@@@ @@@@@@ @@@@@@
| <--+ | +----v-----+ | @@@@@@@@@@@@@@@& @@@@@@ @@@@@@
+-------+ | +-v-+ | | | @@@@@@@@@@@@@@@@@@ .@@@@@% @@@@@@
| | <-----> AH node | | @@@@@@@@@@@@@@@@@@@@@( .@@@@@%
+-------+ +--> j | | | | @@@@@@@@@@@@@@@@@@@@ @@@@@@
<-------> | | u | +----------+ | *@@@@@@@@@@@@@@@@ @@@@@@ @@@@@@.
<-------> nginx <-----> s | | @@@@@@@@@@@@@@ &@@@@@. @@@@@@
<-------> | | s | +----------+ | #@@@@@@@@@@ @@@@@@ #@@@@@/
+-------+ | i | | | | @@@@@@@@ /@@@@@/ @@@@@@
| <-----> FAT node <---+ @@@@@( @@@@@@ .@@@@@&
+---+ | | @@ @@@@@& @@@@@@
+----------+
Sorry, lack of GIMP skills
Hivemind
For this purpose I use Hivemind (hats off to @roadscape) backed by PostgreSQL.
Hive is a "consensus interpretation" layer for the Hive blockchain, maintaining the state of social features such as post feeds, follows, and communities. Written in Python, it synchronizes an SQL database with chain state, providing developers with a more flexible/extensible alternative to the raw hived API.
FAT node
Also, instead of a single hived node with all the plugins, I chose to run two nodes, one of them is a “fat node” (LOW_MEMORY_NODE=OFF and CLEAR_VOTES=OFF) on a MIRA-enabled instance to feed the Hivemind.
Please note that I have NOT included market_history in my configuration, simply because it doesn’t require a “fat node”, but Hivemind requires it, so make sure that you have it somewhere.
AH node
Account history node is the other node I use in my setup. It serves not only account history, but it’s definitely the heaviest plugin here, hence the name.
I’m not using MIRA here, because I prefer the pre-MIRA implementation of the account history plugin and MIRA had some issues with it. Also, it’s way too slow for replay.
Jussi
Instead of one service, I now have three specialized ones, I need to route incoming calls to them.
So the get_account_history goes to the AH node, while the get_followers goes to Hivemind.
That’s what jussi does, but it also caches things.
Redis
Jussi uses Redis as in-memory data cache. This can very effectively take load off the nodes. Even though most of the entries quickly expire, it’s enough to effectively answer common questions such as “what’s in the head block?”

8 dApps asking for the latest block will result in 1 call to the node and 7 cache hits from Redis.
Nginx
That’s the world facing component - here you can have your SSL termination, rate limiting, load balancing, and all other fancy stuff related to serving your clients.
Resources
Now when you know all the components, let's take a look at what is required to run them all and (in the darkness) bind them.
Small stuff
There are no specific needs here. The more traffic you expect, the more resources you will need, but they can run on any reasonable server on instance:
- Nginx needs what nginx usually needs - a bunch of cores and some RAM.
- Jussi is no different than nginx when it comes to resources.
- Redis needs what redis usually needs - a few GB of RAM to hold the data.
Big stuff
the AH node, which is non-MIRA in my setup, requires plenty of RAM for the
shared_memory.binfile to either hold it on tmpfs or buffer/cache it, especially during replay. A machine with 32GB RAM will work, but I would rather suggest using a 64GB RAM machine these days. Of course, low latency storage such as SSD or NVMe is a must. You need 600GB of it.the FAT node in my setup is running MIRA, so it’s not that memory hungry, but the more RAM you have, the more effective it can be. A machine with 16GB RAM might work, but I would go with 32GB or 64GB for it. Don’t even try without a very fast SSD or NVMe. You need 400GB of it.
Hivemind itself is a simple script, but it needs PostgreSQL as a database backend, and for that you need all the things that PostgreSQL usually needs. It can run on pretty much everything, as long as you have enough space to fit the data, currently 300GB. Of course, faster storage and more RAM will result in much better performance.
From zero to hero
Reference hardware configuration:
Intel(R) Xeon(R) E-2274G CPU @ 4.00GHz
64GB RAM, ECC, 2666MT/s
2x NVMe 960GB (SAMSUNG PM983)
When you are starting from scratch, it’s best to get a recent block_log
I’m providing one at https://gtg.openhive.network/get/blockchain/
How fast you can get it depends on your network and load on my server. The average downloading speed is around 30MB/s, so you should be able to get it in less than 3 hours.
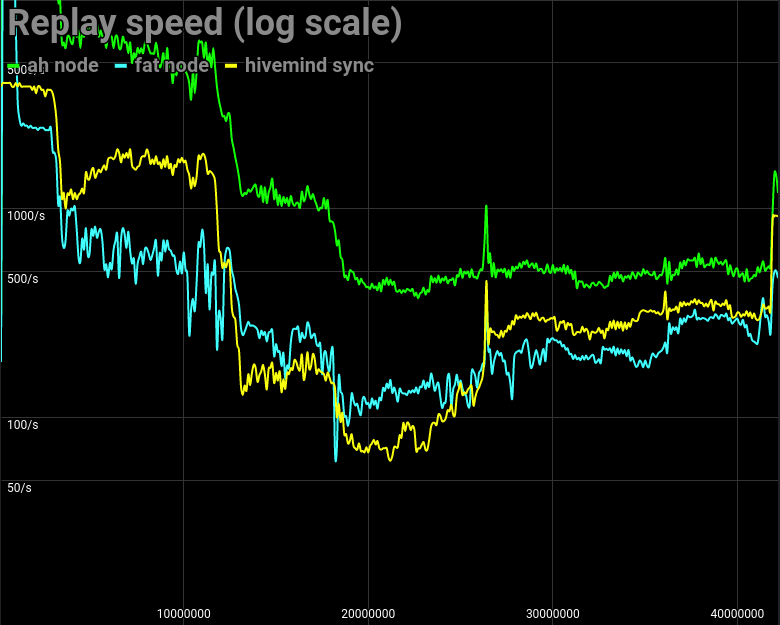
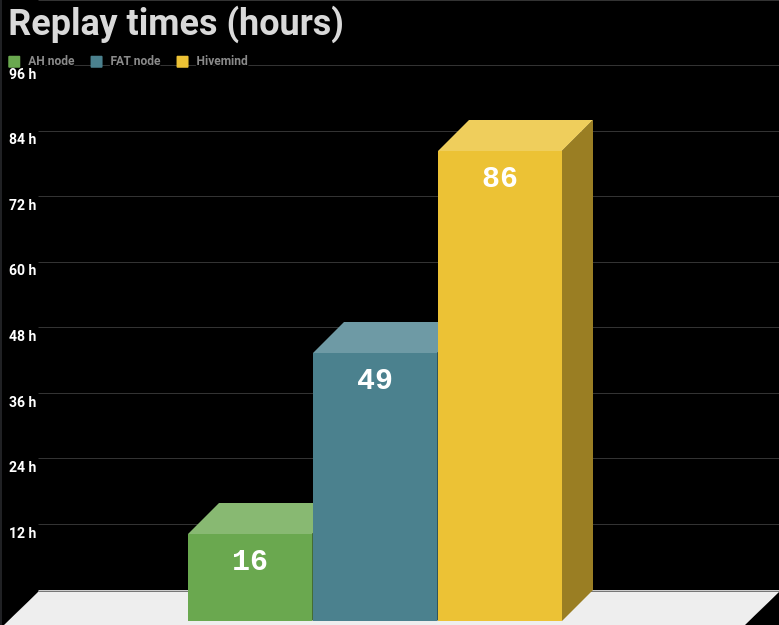
| Node type | Replay Time |
|---|---|
| AH Node | 15 hours 42 minutes |
| Fat Node | 48 hours 53 minutes |
| Hivemind | 85 hours 50 minutes |
Roughly you need 4 days and 9 hours to have it synced to the latest head block.

A lot can be improved at the backend, and we are working on that. To be developer-friendly, we also need to improve the set of available API calls, finally get rid of the deprecated ones such as get_state, and move away from the all in one wrapper condenser_api. But that's a different story for a different occasion.

Is this a good question?
Not great, not terrible ;-)
That was an acceptable answer.
Hello Wizard.
How about private node for basic needs?
I need wallet functionality, create accounts, manage accounts, do transfers, check transfer history.
Is AH Node enough or do I need all connected components: Jussi, Hivemind?
Most likely you don't even need complete AH node for that, you can track only those accounts that matters to you (for transfer history). You don't need jussi or hivemind. Node that tracks only few accounts needs 260GB for
block_log(as every other hived node) and 60GB for state file.Please note that you have to know list of accounts for account_history tracking before you begin replay. There's also a way to track all accounts but explicitly whitelist / blacklist given history operations.
For optimal tuning I'd have to know all your use cases.
I am curious about how it all works.
What are the complex questions which only go into the Hivemeind layer? Follows, post feeds, communities, and what else? Doesn't this partly compromise censorship resistance?
What is the difference between the consensus rules for blockchain nodes and those for Hivemind nodes?
You can think of Hivemind as a database that collects the data from consensus nodes and organize them for a faster access. See my
SteemPressure #8: Power Up Your dApp. RethinkDB? KISS my ASAP. Ideally there would be a consensus node, and all other data effectively processed, stored and served by bunch of specialized microservices.Hivemind fetches the data from Hive nodes and interprets them for API purposes.
That itself doesn't affect censorship resistance. Of course API node can be malicious and/or censoring(*) the content as it happens on Steem with Steemit Inc node, but to get the content you are looking for all it takes is to find other non-malicious node or get your own node running. To check consistency with the consensus... the consensus node is enough.
at the moment I am a little confused with the steem which now steemit is a little different from before maybe this is not a good question but I am. Very worried about steem and steem hive.blog what steem and steem hive.bog are different
after I read some of your posts maybe you, a little know about this I do not know who to ask.
Please take a look at the oldersts posts from @hiveio:
thanks you
Trying to keep up with these updates and will be sharing this link when some members we have here on hive asked.
You sir are pure genius, I would like to say thank you for creating or co creating hive, I love it, I lost all faith in steemit months ago, gave my account with this name on it to my daughter, she gave up on it day 1.
So again, thank you for making a refreshing new site, with new visions.
But the wizard has state files to boot the chain from, does he not?
I use state providers to quickly restore in case of a bigger failure, but it wasn't used here.
Here
block_logwas used, i.e. not state, but content of blocks.To get the state, you need to replay blocks.
You can get blocks from other machine or public source (like in this post), or alternatively you can sync blocks from other peers in Hive network (but that's currently way slower than downloading blocks and replaying them).
Hello
I want to get the content of the blocks and analyze them on the chart. Can I download the block _log and use it for that?
Yes, but basing on your previous question you'll probably fail with understanding it's structure. Running local node and using
get_blockmight be much easier to achieve that. Please read the docs.Yes thats rigth, but here I have a number of restrictions on how to run a node and get a block, so I said it would be a great help if I could download block_log and analyze block information through it.
You don't even need to run a node, just
get_blockfrom remote public API (please remember about distinction between Steem / Hive, those are two separate blockchains). And be prepared for a lot of data, uncompressed JSON will take hundreds of gigabytes.I've used get _block before, it took a long time for each block to take a second, so if block _log gives me the same get _block information, it will help me a lot. And I'm trying to do more research on the difference between Hive and Steem. Thank you.
Excuse me, if I want to get the information via get _block, what features (what kind of server or RAM and cpu) do I need? And what can be done to speed up the response to requests?
I didn't understand 100% because of my lack of English proficiency. However, I read a good article well.
Really great post @gtg ! Keep it up!
Hi. I see you voted up Mr King's Crown. He seems to be trolling Hive whilst milking Steem and he retaliates against anyone trying to reduce his rewards here. He's not exactly an asset to the community. But of course you should vote as you see fit.
Hope you are well.
here's how to ask a good question: Why is the blockchain working like shit?
nice
Gracias por compartir
this is so helpful. we hope to see many helpful tips like these always
You said you have not included market_history in your configuration but it is required by Hivemind. But you are running Hivemind too, so how did you do?
Congratulations @gtg! You have completed the following achievement on the Hive blockchain and have been rewarded with new badge(s) :
You can view your badges on your board and compare to others on the Ranking
If you no longer want to receive notifications, reply to this comment with the word
STOPDo not miss the last post from @hivebuzz:
Vote for us as a witness to get one more badge and upvotes from us with more power!
Well quite informative
Congratulations @gtg! You received a personal badge!
Welcome Comrade!
Thank you for joining our fellow revolutionaries to promote decentralization and censorship-free speech.
Hive is your new home and you bravely chose to definitely turn your back on Steem.
Invite your friends to join our fight by sharing this post.
¡Viva la revolucion!
You can view your badges on your board and compare to others on the Ranking
Do not miss the last post from @hivebuzz:
Vote for us as a witness to get one more badge and upvotes from us with more power!
Hi @gtg, why did you downvote my post. did I make mistake. if I make a mistake. I am sorry. please delete downvote immediately.
Hello. It's nothing personal, it was just a disagreement on rewards. Downvotes are integral part of this system and are essential in a process of finding a consensus for evaluation of posts. For example there are users that are trying to bet on curation rewards, voting regardless of content and others who are countering such votes, and such thing happened in this case.
may I ask you to fix it in my post, upvote it again,
may I ask your discord to communicate
The new Star Wars spin-off series on Disney+, The Mandalorian, has been making huge waves on social media thanks to one tiny star: Baby Yoda.
This message was written by guest bxy_3344235, and is available at crypto.investarena.com
She was supposed to start writing! No excuses.
When it comes to trading I have no idea, definitely not my field of expertise :-)
Nonetheless I'll take a look :-)
We had some bad experience with self acclaimed TA expert who used those charts as a low effort way to self vote himself. However, from what I saw on chats, there are tons of people into that so you might find a good audience. Not a whales though. They usually already know when to buy or sell :-)
That's called optimization. Without Hivemind and MIRA, scalability would be extremely difficult and pricey. And remember, STEEM is running on a similar infrastructure, so it's bloated too, by your definition.