Vision foundation models (VFMs) like DinoV2 and masked autoencoders (MAE) have shown excellent performance in tasks such as classification and semantic segmentation through self-supervised learning (SSL). Recently, domain-specific VFMs have emerged, like SatMAE, which processes temporal or multi-spectral satellite images. Efficient adaptation of these large models has led to the adoption of PEFT methods, which update only a fraction of the parameters. Techniques such as LoRA apply low-rank weight updates, while others modify the number of trainable parameters. Domain adaptation strategies address distribution shifts between training and testing data using discrepancy metrics or adversarial training to enhance model performance across domains.
Researchers from Stanford University and CZ Biohub have developed ExPLoRA, an innovative technique to enhance transfer learning for pre-trained vision transformers (ViTs) amid domain shifts. By initializing a ViT with weights from large natural-image datasets like DinoV2 or MAE, ExPLoRA continues unsupervised pre-training in a new domain, selectively unfreezing 1-2 ViT blocks while employing LoRA to tune the remaining layers. This method achieves state-of-the-art performance in satellite imagery classification, improving top-1 accuracy by 8% while utilizing only 6-10% of the parameters compared to previous fully pre-trained models, demonstrating significant efficiency and effectiveness in domain adaptation.
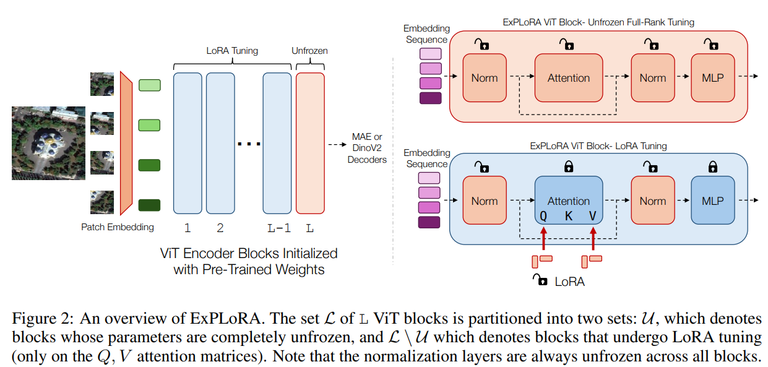
The MAE and DinoV2 are SSL methods for ViTs. MAE uses a masked encoder-decoder structure that requires full fine-tuning for downstream tasks, which can be computationally intensive. In contrast, DinoV2 demonstrates strong zero-shot performance by employing a trainable student-teacher model architecture, enabling adaptation without full fine-tuning. The ExPLoRA method is proposed to address fine-tune inefficiencies, combining pre-trained weights with low-rank adaptations and additional updates to adapt ViTs to new target domains efficiently. This approach reduces storage requirements while maintaining strong feature extraction and generalization capabilities.
The experimental results focus on satellite imagery, highlighting a case study with the fMoW-RGB dataset, achieving a state-of-the-art top 1 accuracy of 79.2%. The ablation study examines performance metrics across various configurations. ExPLoRA models, initialized with MAE and DinoV2 weights, outperform traditional fully pre-trained methods while utilizing only 6% of the ViT encoder parameters. Additional evaluations on multi-spectral images and various satellite datasets demonstrate ExPLoRA’s effectiveness in bridging domain gaps and achieving competitive performance. The results indicate significant improvements in accuracy, showcasing the potential of ExPLoRA for satellite image classification tasks.
In conclusion, ExPLoRA is an innovative pre-training strategy designed to adapt pre-trained ViT models for diverse visual domains, including satellite and medical imagery. ExPLoRA addresses the limitations of costly from-scratch pre-training by enabling efficient knowledge transfer from existing models, achieving superior performance compared to domain-specific foundations. The method combines PEFT techniques like LoRA with minimal unfreezing of model layers, significantly enhancing transfer learning. The experiments reveal state-of-the-art results on satellite imagery, improving linear probing accuracy by up to 7.5% while utilizing less than 10% of the parameters of previous approaches.