🚀 OpenAI’s o3 Breakthrough: A Game-Changer for AGI and Benchmarks 🚀

The announcement of OpenAI’s o3 performance on the ARC-AGI benchmark is a pivotal moment in AI development, showcasing unparalleled adaptability and reasoning capabilities. This breakthrough represents a giant leap forward in the field of artificial general intelligence (AGI) and highlights the importance of robust benchmarks in guiding AI research.
Here’s a breakdown of what makes this milestone so impactful, the progress leading up to it, and why benchmarks like ARC-AGI are critical for understanding AI’s limits and potential.
READ MORE ABOUT o3 results
https://arcprize.org/blog/oai-o3-pub-breakthrough
Watch info on day 12 about o3
https://openai.com/12-days/
🌟 Understanding ARC-AGI and Its Challenges
What Is ARC-AGI?
ARC-AGI (Abstraction and Reasoning Corpus for Artificial General Intelligence) is a benchmark designed to measure AI’s ability to generalize and solve novel tasks. Unlike conventional benchmarks, ARC-AGI emphasizes:
- Novelty: Each task is unique, preventing reliance on pre-learned patterns.
- Abstract Reasoning: Tasks resemble puzzles requiring logical deduction and creativity.
- Core Knowledge: Tasks depend on fundamental concepts like object relationships, basic arithmetic, and topology—knowledge typically acquired by children by age four.
Examples of Tasks
- Deduce the transformation rules for a grid of colored blocks, such as “move all blue squares to the edges while preserving the pattern.”
- Identify missing pieces in a geometric sequence without explicit instructions.
For humans, these tasks are intuitive and solvable with ease. Studies show humans score 97-99% on ARC-AGI tasks. In contrast, traditional AI systems struggle, scoring close to 0% without innovations in reasoning and adaptability.
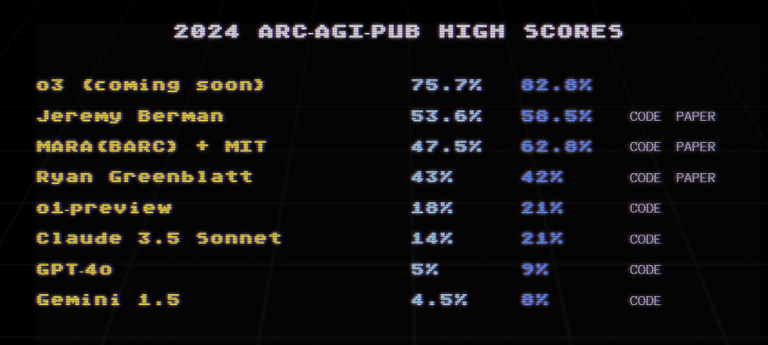
📈 A Brief History of ARC-AGI Progress
ARC-AGI has proven to be a tough challenge for AI systems, resisting progress from brute-force and deep-learning models:
- 2019 (Release): The ARC benchmark is introduced, emphasizing task novelty and abstraction.
- 2020 (First Kaggle Competition): Top score: 20%, achieved using brute-force program search.
- 2023 (Pre-o3 Models): Large language models (LLMs) like GPT-3 and GPT-4o scored 0-5%, exposing their limitations in task adaptability.
- 2024 (ARC Prize): OpenAI’s o3 achieves 75.7% on the Semi-Private Evaluation and 87.5% with high compute—a monumental leap.
How Other Models Have Performed
- DeepMind’s AlphaCode: 10-15% using transductive models.
- Anthropic Claude 3.5 Sonnet: 14% on Semi-Private Evaluation.
- Google Gemini 1.5: 4.5-8% across evaluation sets.
- Brute Force Approaches: Early models from 2019-2020 relied heavily on brute-force program search, achieving up to 20%. These approaches used predefined domain-specific languages (DSLs) to exhaustively explore possible solutions but struggled with combinatorial explosion and lacked adaptability.
- Test-Time Training (TTT): Models like MindsAI’s TTT approach reached 55.5% in 2024 by fine-tuning on demonstration pairs during testing, showcasing a blend of memorization and adaptive learning.
- Program Synthesis Models: Ryan Greenblatt’s approach (2024) used GPT-4o to generate, evaluate, and debug thousands of Python programs per task, reaching 42% on public evaluations.
What Is Brute Force?
Brute force in AI refers to exhaustively searching through all possible solutions within a predefined framework. Early ARC-AGI solutions relied on brute-force methods:
- How It Works: Define a set of rules or operations (e.g., a DSL) and systematically test all combinations to find one that fits the task.
- Strengths: Guaranteed to find a solution if one exists within the search space.
- Weaknesses: Extremely computationally expensive and inefficient for complex tasks with large search spaces. Brute force is effective for narrow tasks but fails to scale to general problem-solving.
More recent approaches, like o3, have moved away from brute force by leveraging program synthesis and test-time adaptation, allowing the model to dynamically generate and refine solutions based on the task.
🔬 What Makes o3 a Breakthrough?
Program Synthesis and Adaptability
- Core Mechanism: o3 generates and executes programs to solve tasks, unlike traditional LLMs that rely on memorized patterns.
- Chain of Thought (CoT): Uses advanced search methods, akin to Monte Carlo tree search, to identify the steps required for solutions.
Architectural Leap
- o3 introduces new reasoning mechanisms beyond the “memorize, fetch, and apply” paradigm of traditional LLMs.
- It combines deep learning with dynamic test-time adaptation, allowing it to recombine knowledge in real-time.
💡 Why Benchmarks Like ARC-AGI Matter
- Tracking Generalization: Unlike saturated benchmarks, ARC-AGI evaluates an AI’s ability to generalize to unseen tasks.
- Encouraging Innovation: Its challenges inspire new architectures and solutions, pushing the boundaries of AI research.
- Highlighting Gaps: o3’s success shows progress, but its failures on simpler tasks indicate AGI is still far off.
💰 The Cost of Progress: Economic and Practical Implications
- High Costs: o3’s high-efficiency mode costs $17-20 per task, compared to $5 for humans. High-compute configurations are even more expensive.
- Scaling Challenges: While high compute improves scores, it’s not sustainable for production or practical use cases.
- Future Viability: Continued improvements in cost-performance will be crucial for making advanced AI economically viable.
🔮 What’s Next for ARC-AGI and AGI Research?
ARC-AGI-2 (2025 Launch):
- A new dataset will introduce harder, more diverse tasks to prevent overfitting and push AI systems further.
- Early tests suggest o3 could score below 30% on ARC-AGI-2, reaffirming the benchmark’s importance.
Collaboration and Open Research:
- ARC Prize emphasizes open-source solutions, fostering collaboration and transparency.
- The community is encouraged to analyze o3’s unsolved tasks and identify areas for improvement.
Beyond o3:
- Future models will need to integrate program synthesis, test-time training, and efficient compute strategies to achieve AGI.
- The field will increasingly prioritize efficiency metrics alongside performance to ensure practical advancements.
Conclusion: Why This Matters
OpenAI’s o3 performance on ARC-AGI represents a landmark achievement in AI’s evolution. By tackling tasks that demand true reasoning and adaptability, o3 demonstrates the potential of innovative architectures and rigorous benchmarks to drive progress. However, the road to AGI is still long, and challenges like cost, efficiency, and robustness remain.
As ARC-AGI evolves, it will continue to serve as a critical compass for measuring and advancing AI capabilities. The lessons from o3 and ARC-AGI remind us that while milestones like this are worth celebrating, they are also stepping stones to even greater discoveries.
Published with PeakVault
