This is the first edition of the @ai-summaries weekly report. Here you will get the latest updates about the AI-summaries project and various statistics and information about the activities of the past week. My goal is to put up a report with updated numbers every Sunday starting today.

What is AI-Summaries?
It is a project was started in January of 2024, and its original mission was to make the content and discussions taking place in various HIVE and LEO-related livestreams available to a wider audience. By providing summaries of the episodes in chunked-up text format, non-english speaking Hivers was suddenly able to translate them to any languages to get an idea of the discussions taking place despite misc. language barriers. It also aimed to cater to the time-constraint many people find themselves in, and simply doesn't have time to listen to hours of podcasts and livestreams each week.
But perhaps the more powerful and underlying part of it, is the addition of the actual data. By posting the summaries to the blockchain, they're by default recorded permanently to the decentralized database which is Hive, for anyone to utilize – including the training of AI agents like LeoAI.
During the course of the last 11 months, hundreds of livestreams has been summarized as their own separate blog posts, in addition to several thousand 3Speak videos from channels like @cttpodcast, @taskmaster4450 and @theycallmedan, where the summaries were posted in the comment's sections of the videos.
And last Sunday (November 17, 2024) the scope of the project was widened significantly:
Introducing the Youtube Summarizer
If data is the new oil, then why give it all away to big tech?
https://inleo.io/threads/view/mightpossibly/re-leothreads-cjhbc6ka?referral=mightpossibly
In short, the idea is to provide an easy to use and effective way to democratize data by putting it on the blockchain. If this is the first you're hearing about the democratization of data and the decentralization of AI, I recommend giving this excellent article by @taskmaster4450le a read, where he also discusses the significance of this tool in that context.
But enough history and background, now that you know a bit about the project's history and the recent developments, let's get on with this week's numbers!
Weekly Stats
Here is an overview of this week's numbers/activity.
Hive/LEO Livestream Summaries
- Summary: Vaultec Interview about VSC on Crypto Lush – November 15, 2024
- Summary: Inleo AMA – November 19, 2024
- Summary: Chain Chatter – November 20, 2024
- Summary: Lion's Den – November 22, 2024
Youtube Summarizer Stats
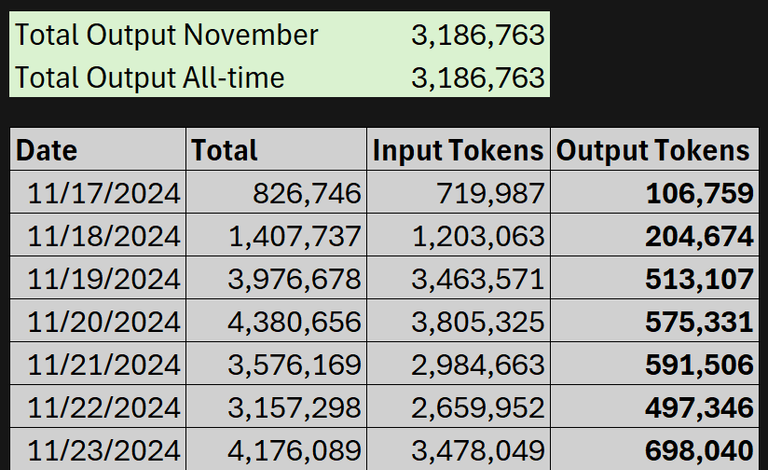
- Total number of yt-videos processed: 4,100
- Total number of comments posted: 20,545
- Total Output Tokens posted to chain: 3,186,763
Learn More
https://inleo.io/threads/view/mightpossibly/re-leothreads-34kfsyw63?referral=mightpossibly
https://inleo.io/threads/view/mightpossibly/re-leothreads-2uy1hgpek?referral=mightpossibly

Want to contribute? The best way to support it is to subscribe to me and to use the Youtube Summarizer every day to contribute to the adding of the data. There is a near infinite source of information on youtube, and now there is an easy way to tap into it to benefit the value of the network as a whole.
Join us, subscribe today!

Posted Using InLeo Alpha
What an awesome tool!!! I wonder now if we could use the summeries to reconstruct the videos in that summerized format, or at least make it an audible file?
I'm glad you think so! I mean sure, you're very welcome to do something like that. I've used elevenlabs' free plan (ai voice generation) for something similar and it's pretty great. There are also full-on script-to-video tools that allow you to generate entire videos based off of a script such as an article, but those are typically pretty expensive. If you have a bit of video editing skills you can get far with just a narration track from a voice generator and stock video
Oh I don't even know where I would start with making such tool.... I use eleven labs and other ai generation tools but I don't know how to build anything like that at all!
Ah. I think we may have spoken past each other there. I thought you were asking whether it was possible and okay to use these summaries to create new videos.
If you were thinking about automating the creation of such videos, this would not be economically viable for me and also out of scope for this project. In addition, my experience is that ai-generated videos like this still require some post editing by people to make somewhat sense - at least for now. But I do like the idea! Would be cool to see someone give it a go, whether automated or manually.
Haha 😅 yes. I can see how that could confused. Well thanks for the green light anyway!
This tool is a great tool for summarizing videos, I have use it on free trial and now I have subscribed to it... This is a great way of feeding Data..
A big thanks for you @mightpossibly
Thank you for your continued support and engagement, Caleb. It really is, isn't it
Its is, is it.... 😂😂😂😂 Lol
Congratulations @mightpossibly! You have completed the following achievement on the Hive blockchain And have been rewarded with New badge(s)
Your next target is to reach 85000 upvotes.
Your next target is to reach 11500 replies.
You can view your badges on your board and compare yourself to others in the Ranking
If you no longer want to receive notifications, reply to this comment with the word
STOPCongratulations @mightpossibly! You received a personal badge!
Wait until the end of Power Up Day to find out the size of your Power-Bee.
May the Hive Power be with you!
You can view your badges on your board and compare yourself to others in the Ranking
Check out our last posts:
Congratulations @mightpossibly! You received a personal badge!
Participate in the next Power Up Day and try to power-up more HIVE to get a bigger Power-Bee.
May the Hive Power be with you!
You can view your badges on your board and compare yourself to others in the Ranking
Check out our last posts:
Congratulations @mightpossibly! You received a personal badge!
Thank you for participating in the Leo challenge.
You can view your badges on your board and compare yourself to others in the Ranking
Check out our last posts:
Ho Ho Ho! @mightpossibly, one of your Hive friends wishes you a Merry Christmas and asked us to give you a new badge!
The HiveBuzz team wish you a Merry Christmas!
May you have good health, abundance and everlasting joy in your life.
To find out who wanted you to receive this special gift, click here!
You can view your badges on your board and compare yourself to others in the Ranking
Check out our last posts:
!summarize
!summarize