Introduction
The reliable way of achieving consensus in blockchain is critical part for design of any system intended to support transparent and reliable financial ecosystem, unbiased content management and communication systems or trustable and efficient shared data storage - in all cases cheap, fast and secure at the same time.
In the following, we will briefly discuss problems specific to different types of consensus algorithm, indicating problems associated with them. Further, we will introduce Proof-Of-Reputation (POR) idea and follow up with different variations and parameters of the algorithm and discuss possible architectures of its implementation.
Why Consensus Matters
The key of the blockchain is its ability to solve so called “Byzantine General’s Problem” of distributed coordination of multiple agents, with some of the agents being potentially unreliable or even alien. Blockchain solves it without of dedicated “man in the middle” verifying their reliability and loyalty, using some algorithm of achieving “consensus” across the agents in the course of their peer-to-peer communications: https://medium.com/@DebrajG/how-the-byzantine-general-sacked-the-castle-a-look-into-blockchain-370fe637502c.
If probability of all agents in the system to be responsible for new block formation is the same, and there may be up to M unreliable or alien agents in the network, it is required to have at least 2*M + 1 reliable and loyal agents. Practically, during attacks attempting to takeover the network amount on alien nodes in attacking botnet may be high, so the M could be large and so amount of nodes guarding the network should be more than twice larger. To reduce the risk of the takeover, the consensus algorithm increases probability of being in charge of new block formation to more reliable and loyal agents with loyalty implicitly derived from various metrics of the agent account.
Known Types of Consensus in Blockchain
For discussion of different consensus algorithms, we will be referring to excellent overview made by Jeff Hu: https://medium.com/@jj1385jeff850527/beginners-guide-what-s-the-difference-between-proof-of-work-proof-of-stake-proof-of-burn-and-74c42df591ca and we will outline on issues specific to each of them.
Proof-of-Work (PoW) - makes the entire system energy consuming and inefficient in terms of cost and time, so making it cheaper makes interval between transactions longer while making it faster makes each of transactions more expensive. Also, it is still possible to takeover the system by cooperation of several mining pools accumulating substantial computational power and coordinated by particular party.
Proof-of-Stake (PoS) - makes the system vulnerable to takeover by coordinated activity of multiple nodes, for instance transferring substantial amount of stake-able resources to their delegated nodes temporarily making these nodes capable to perform control over transactional history for designated amount of time.
Proof-of-Burn (PoB) and Proof-of-Deposit (PoD) - combine flaws of PoW and PoS as takeover may be performed by either pool of nodes with mining capabilities or pool of nodes capable to coordinated staking with resources of any origin.
Proof-of-Importance (PoI) and Proof-of-Stake-Velocity (PoSV) - while makes use of social aspects, such as density of communications directed toward each of the nodes in the network, both are still vulnerable to takeover attack from simple bot-net made of nodes managed by the same party coordinating the attack.
Proof-of-Capacity (PoC) - being economically more efficient than PoW, still vulnerable for takeover performed by pools accumulating hardware resources by means of allocating financial resources to spend on it, like PoS implicitly.
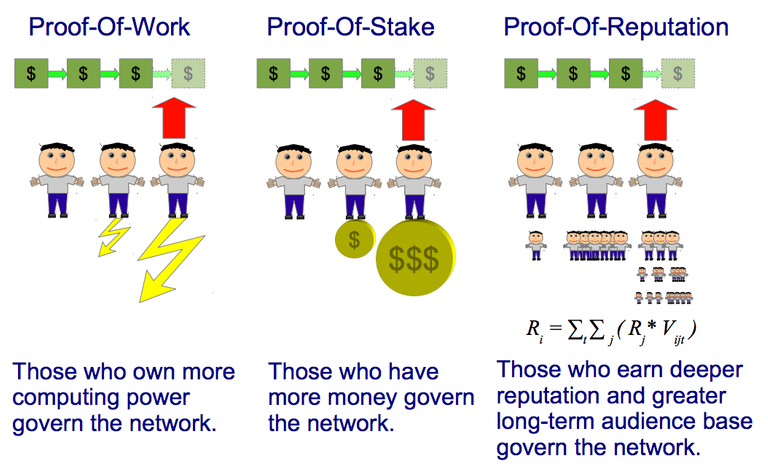
Proof or Reputation as Hierarchical Reputation Consensus
In order to eliminate vulnerabilities specific to the existing consensus algorithm, we introduce Proof-of-Reputation (PoR) which effectively express the key idea of what can be also called as “liquid democracy” algorithm https://en.wikipedia.org/wiki/Delegative_democracy .
The PoR consensus algorithm may have different variations and parameters tuning its performance but the basic idea is simple. Proof-of-Reputation" it is calculated as Rj = SUMit( Ri * Vijt ), where Vijt can be either implicit rating as positive or negative vote or implicit rating as wire transfer amount, either spent or received, for node j being rated, node i supplying the rating and time t to perform the rating. The key property of the algorithm is iterative nature of it, so each implicit or explicit vote is weighted or received.
This recursive nature of this kind of reptation makes it resistant in respect to takeover attacks performed by alien pools or botnets. On one hand, this is similar to Proof-of-Importance in fact, however, PoI can be hacked by botnet which would pump importance of account used as attack origins. In turn, in our PoR design, if you count Rj = SUMit( Ri * Vijt ) in one or more iterations, you can fix that. The more iterations, the longer "chain of trust", the better protection is. If number of iterations is unlimited, the reputation evaluation process of building hierarchical reputation tree at scale of entire network, with the best reputable nodes or users residing at the very top of hierarchy and given them most governing power.
It is well illustrated on the following picture, where in case of PoW and PoS the blockchain is eventually managed by the either most-equipped or the most-funded well coordinated sub-nets. Opposed to that, in the case of our PoR, the blockchain would be managed by the most well connected and mutually communicated association of subnets spanning more than half of entire network - in terms of breadth and depth at the same time.
To put is simple, Proof of Reputation consensus algorithm assures that network is governed by nodes, acquiring the best reputation in entire network, expressed explicitly or implicitly, with account to reputation of the peers supplying the reputation evaluations following the idea of “liquid democracy”. This reputation evaluation may depend on particular time, time interval and context of the evaluation, such as scope of restricted community of users or subnet of nodes or particular subject domains or topics of interest or groups of them.
The illustration above is taken from our presentation on structuring graphs: http://aigents.com/papers/2017/Structuring-Social-Graphs-2017-en.pdf - there are slides 6 and 9 are of particular interest. Moreover, using Aigents platform for reputation study and reputation management may be useful, as discussed in the following video and we will be covering more details further in this article.
To certain extent, the idea of recursive weighted reputation evaluation is somewhat similar to “Google Juice” approach https://www.urbandictionary.com/define.php?term=Google%20Juice applied to evaluation of ranking of web pages in the “Page Rank” algorithm.
Reputation Evaluation Model Ratings and Parameters
The following design of reputation calculation in social network is based on our earlier works on reputation, also called as “social capital” or “karma” - referenced in the following paper: http://aigents.com/papers/2017/Assessment-of-personal-environments-in-social-networks-2017-IEEE.pdf.
Simple computational model of reputation in formula above can be complicated to account multiple kinds of ratings and can be constrained by respective parameters, as discussed further. In the following discussion we will be talking about reputations in terms of nodes, while each node can be thought as a user, user account, software agent or whatever playing role of multi-agent social network such as blockchain system. We will be also referring to artifacts produced by nodes in the course of their activity so they may be indirectly rated by means of rating their artifacts, such as posts and comments in social networks, or messages or tasks in multi-agent systems. The following five kinds of ratings used for reputation calculation are considered on peer-to-peer basis constrained by time, so node i ranks node j at time t by means of explicit or implicit, direct or indirect of financial rating value.
Fij - identifies explicit direct rating corresponding to fact that node i trusts node j. In conventional social networks, including Steemit at, it corresponds to “follower” link between the two users. Only one rating of this kind may exist at time t while there may be different moments in time when this link is created or removed. Normally, it is either 0 or 1 but we can imagine systems with “five stars” ratings or any range of values for this, including possibly negative rating.
Oijt - corresponds to explicit indirect rating indicating the fact that node i explicitly voted for artifact authored by node j. In social networks like Facebook this is typically called “like”, in Steemit it is called “vote” and it is also can be either 0 or 1 but we also can imagine any range of values, like Youtube has possible negative and positive content ratings such as -1, 0 and 1.
Cijt - represents implicit indirect rating corresponding to the fact that node i authored textual content such as post comment in respect to artifact authored by node j, with either positive or negative sentiment extracted from the text, so this can be any positive or negative value on any scale. In oversimplified form, we can assume there could be either 0 or 1, which means all present comments are thought positive, if present.
Dijt - stands for implicit direct rating corresponding to the fact that node i authored text content such as post or comment with mention of node j in context of positive or negative sentiment extracted from the text, like for the case above. In oversimplified form, we can assume that any mention of a node in text, such as user name would count to 1 and 0 otherwise.
Sijt - represents direct financial rating reflecting the fact that there is a financial transaction or fund transfer from node i to node j at time t. Normally, it could be only positive value in given currency however there may case to treat cancellations of transactions or returns under umbrella of smart contracts as negative ratings.
All that, said, the complete formula for reputation may be the following, assuming that time t may vary in range between T1 and T0, where T0 is time for rating evaluation and T1 = T0 - dT, and dT is temporal window to take account for, called “reputation period”.
Rj = SUMi( Ri * Fij ) + SUMit( Ri * (Oijt + Cijt + Dijt + Sijt) )
Besides temporal scoping of ratings in window of DT, there potentially could be other also scoping by any other criteria, such as subsets of ratings matching particular criteria and scoping what we call “reputation base”, such as follows:
- Ratings associated with particular set of topics P, called “reputation domain” (like tags in Steemit)
- Ratings within specified set of nodes S, called “reputation audience” (like users in Steemit)
Further, because of recursive nature of reputation calculation, there could be parameter N indicating maximum depth of the graph traverse when making calculations, which can be called “reputation depth”.
Then, there could be possible implementation of the formula filtering out any mutual rankings to eliminate cheating so that for any kind of rating above, there could be “non-reverse” version, taking only differential balance of mutual ranking transactions conducted in given period of time, so only asymmetric non-mutual ratings are counted.
R’j = SUMi( Ri * Fij ) + SUMi( Ri * SUMt( (Oijt-Ojit + Cijt-Cjit + Dijt-Djit + Sijt-Sjit) ) )
Or, it can be rewritten with differential rankings such O’ijt, C’ijt, D’ijt and S’ijt as follows.
R’j = SUMi( Ri * Fij ) + SUMi( Ri * SUMt( (O’ijt + C’ijt + D’ijt + S’ijt) ) ), O’ijt = Oijt - Ojit, etc.
The formula above may be also complicated to avoid closed reputation loops with L as maximum number of links in the loops to detect and subtract from the volume of ratings.
Each of the ratings and may have its own scaling as well as there may be a need to provide scaling for entire reputation evaluation, so there may be more complicated formula with account to scaling of all of the raw ratings and final reputation.
R’’j = X1(Y1(SUMi( Ri * Z1(Fij))) + Y2(SUMi(Ri * Z2(SUMt((W1(O’ijt) + W2(C’ijt) + W3(D’ijt) + W4(S’ijt)))))))
In the above, X1 is scaling function for entire reputation, Y1 is scaling function for its temporally-irrelevant part and Z1 is scaling the temporally irrelevant rating itself. Moreover, Y2 is scaling temporally bound fraction of reputation Z2 is scaling peer-to-peer fraction of it and W1,W2,W3 and W4 are scaling temporally bound rankings - raw or differential. Each of the functions may be either non modifying original value or implementing scaling factor for linear scaling, or be non-linear, capping the higher values. These functions may operate on basis of what has been called “reputation base” keeping the values in controlled ranges such as 0.0-1.0 or 0-100.
Finally, as the recursive reputation calculation involving multiple kinds of ratings may be computationally expensive, there may be a need to have it performed periodically on hourly, daily, weekly or monthly basis, so there should period T indicating duration of the period.
Obviously, for particular kinds of blockchains different kinds of rankings may be available. For instance, for Steemit or Golos we can use all of them - some examples are given at https://steemit.com/@aigents. For most of blockchains handling financial information only and not supporting textual content or explicit ratings, such as Bitcoin and Ethereum only the financial rating would apply. Respectively, the formula above may be simplified.
On the other hand, in some of blockchain applications more information may be attracted to validate reputation, so along with KYC information (https://en.wikipedia.org/wiki/Know_your_customer), there may be use of reputation information obtained from side-chain and off-chain social networks.
While the current discussion is focused on use reputation for blockchain consensus, there may be different applications in various domains such as assessment of personal environments in social networks and evaluation of reliability of online news like discussed in this paper and the following video
http://aigents.com/papers/2017/Personal-analytics-for-societies-and-businesses-2017-IEEE.pdf.
How it Helps
Let us consider takeover attacks performed by alien pools of attacking nodes with different types of consensus. In case of PoW, PoS, PoI and their combinations, there is always possibility for coordinated pool of nodes to accumulate substantial amount of computing power, stake, or transaction turnover in particular node or pool of nodes and start inserting intrusive transactions into the formed blocks. To do so, the amount of attacking nodes maybe even relatively small, they just have to be coordinated better than others - during the time of attack. It is shown on the left and the middle parts on the picture above.
In case of PoR, we have effectively all nodes in the network directly or indirectly in charge for contribution of reputation to each of the nodes potentially charged for new block formation, over the long historical period of time. It is even not enough to create a botnet pumping the rankings in attempt to boost reputation to particular node or pool of nodes, because reputation of each of the nodes in the botnet could not be high, so their contribution to reputation of attacking nodes would be low - the “reputation audience” might be wide but “reputation depth” would be miserable. At the same time, nodes having even few rankins supplied by highly reputable nodes, would have great “reputation depth” and so much higher reputation in the end. This is essentially automated form of “delegative democracy” (such as used in Steemit), so it can be called “liquid democracy”. . It is shown on the right part on the picture above.
Reputation Maintenance Architectures
For maintaining reputation calculation and storing reputation data different approaches can be used. From perspective of the way the reputation information is stored, there may be three approaches, as follows.
Transient reputation - means there is no persistent storage of the reputation information, it is recalculated in memory whenever the node or agent software calculating the reputation is restarted. This does not require spending on reputation storage but makes warm-up time greater, especially with large amounts of historical data and large DT parameter.
Persistent reputation off-chain - latest reputation data is stored in separate database, external to blockchain so it can be loaded upon system startup and incrementally updated if needed. This enables saving on start-up time but needs implementation of off-chain database, which makes sense only in case of calculating reputation in off-chain systems.
Persistent reputation on-chain - latest reputation data is stored in blockchain, in dedicated elements of block structure or encoded in content fields associated with accounts. This makes start-up time short and simplifies architecture but it makes blockchain larger and more expensive on itself, especially if there is a need to maintain multiple reputations for different reputation perdios, audiences and domains.
From perspective of the reputation algorithm design, there may be four approaches, listed below.
Complete recalculation - this means whenever reputation is required, it is being recalculated from the very beginning of the DT interval. This may assure high precision of reputation calculation however it may be too expensive for DT values spanning over large time intervals.
Periodic recalculation - this means recalculation happens only periodically, once per T period, eg. on hourly, daily, weekly or monthly basis, the values are cached and used during the period. This may assure high precision of reputation calculation and would be cheaper than complete recalculation but reputations might be not that precise closer to the end of the T period and it still may be expensive in case of large DT period.
Periodic update - this means persistent reputation data is updated incrementally, periodically once per T period, eg. on hourly, daily, weekly or monthly basis, the values are cached and used during the period. This may be cheaper than anything else yet lead to less precision of reputation calculation and might be not that precise closer to the end of the T period as well.
Transactional update - that means persistent reputations are updated incrementally on any blockchain transaction. This may not precise as complete recalculation yet it would assure reputations are up to date at any point of time. Still, this might be making blockchain transactions a bit more expensive and take a bit longer.
Finally, three software architectures for reputation calculation can be possible, as discussed below.
Reputation Agencies Off-Chain - that means there could be one or more side-chain applications keeping and processing information outside of blockchain network and database. This might be easier and less expensive to implement but it would be less secure, also it would complicate financial setup of the system in order to pay charge to such agencies for their duties.
Reputation Agencies On-Chain - that means the code executing reputation calculation is part of blockchain and reputations are persistent in blockchain database. At the same time, only one or more, but not all nodes in blockchain may be executing the same code. However, while they do so, they should be financially stimulated to do do by the rest of nodes as performing duties beneficial for entire community. This should be the most safe and least expensive option yet it would require more complex architecture.
Reputation Mining On-Chain - that makes all block-producing nodes in the network running reputation evaluation code as part of block-mining code. This would be the most simple, secure and straightforward approach however this might be the most computationally expensive, involving full redundancy of reputation mining in the way similar to PoW.
Conclusion
We have discussed multiple aspects of what we call Proof-of-Reputation consensus algorithm, based on principle of “liquid democracy” applied to blockchain. In the following work, we will be studying different possible implementations of algorithm using reputation agency services provided by Aigents as sidechain application for Steemit and Golos blockchains and SingularityNET agent ecosystem.
More details on reputation, social capital and “karma” study applied to social networks and blockchains can be found on the following resources.
https://aigents.com/
https://steemit.com/@aigents
https://golos.io/@aigents
https://www.youtube.com/aigents
https://medium.com/@aigents
https://www.facebook.com/aigents
https://plus.google.com/+Aigents
https://vk.com/aigents
Very interesting idea. I look forward to seeing what happens next.
Thank you, at this time, we are looking to have this idea implemented in two blockchains - namely https://singularitynet.io/ and https://travelchain.io/, looking forward to have other applications, including further development of https://aigents.com/ as "Reputation Agency"
The Travelchain ICO looks promising. I notice you plan to use an AI to provide a unique customer experience for users. Do you see that AI as being part of SingularityNET?
This is design is not bound to particular system such as Travelchain and SinglularityNET. For instance, in Travelchain there is a plan to implement multiple reputation agenices off-chain design option. In turn, in SingluarityNET, there is draft design for such system focused on single reputation agency on-chain.
It seems as though each user and service provider in the system will have a reputation which is transferable across platforms. This technology is going to be amazing when it achieves maturity.
Complete recalculation - this means whenever reputation is required, it is being recalculated from the very beginning of the DT interval. This may assure high precision of reputation calculation however it may be too expensive for DT values spanning over large time intervals.
Periodic recalculation - this means recalculation happens only periodically, once per T period, eg. on hourly, daily, weekly or monthly basis, the values are cached and used during the period. This may assure high precision of reputation calculation and would be cheaper than complete recalculation but reputations might be not that precise closer to the end of the T period and it still may be expensive in case of large DT period.
Periodic update - this means persistent reputation data is updated incrementally, periodically once per T period, eg. on hourly, daily, weekly or monthly basis, the values are cached and used during the period. This may be cheaper than anything else yet lead to less precision of reputation calculation and might be not that precise closer to the end of the T period as well.
Transactional update - that means persistent reputations are updated incrementally on any blockchain transaction. This may not precise as complete recalculation yet it would assure reputations are up to date at any point of time. Still, this might be making blockchain transactions a bit more expensive and take a bit longer.
can we perform these action in smart contract on Eth blockchain ?
Potentially, yes. The practical considerations would be similar to "Transactional update" model yet there may be different reputation-based ecosystems maintained within the same blockchain. With this option, it is still a bit unclear how to store the reputation data in Ethereum blockchain, it might get too expensive. But it could be interesting "pilot project", if one would decide to go for it.
If you have practical interest as developer, you can send me your email to akolonin at aigents period com email and I will send you more advanced design documents for review.
Yes I am really happy with you ans. I think reputation data can be store on IPFS or storj kind of platform & only their haskey can be store on eth blockchain . I am not sure.!
I sent email from krunal dot bits at gmail dot com. please do revert . Thanks !
Happy Birthday to you! You joined Steemit exactly one year ago today. So Happy Birthday and I hope you have many more Happy Steemit Birthdays :)
More details on this https://arxiv.org/abs/1806.07342
Wow, thanks for blowing my mind today. I like that to happen about once a day. I'll need to read this again to keep up my pace of learning. Truly, thanks for giving me new insight.