yes, thank you I completely forgot about the new "3.0 paradigm" (have not read into any of them yet (except for avalanche) but afaik the critique of Sirer on Hedera was that they are (maybe not timed) but calibrated. I will look into it.
Making timing assumptions means that we can assume that a message from one server to another will have a "maximum" roundtrip.
Asynchronous protocols don't make any timing assumptions in this regard
Ok I get what you mean. Then one has clearly to differentiate timing (which involves clock time) and synchronicity without time. But I realy dont think that any of the protocols works with actual clock time, Because the 3 seconds are not a protocol parameter but a constant? When you use a BEOS node in the orbit it changes.
Now, if we know there is a maximum time, then we can ALWAYS detect if a faulty and thus, we can avoid a lot of the problems and can achieve safety and liveness with a lower percentage (51%)
yeah but there is no known maximum time I would say. Whoms clock you take to measure time?
Going back to DPoS. Yes, every block needs N^2 to be finalized. But if we add more witnesses this will spread out over a longer period of time as well so that will only increase the latency and not be a problem for throughput at all.
good point, now I guess I understand Dans Triangle
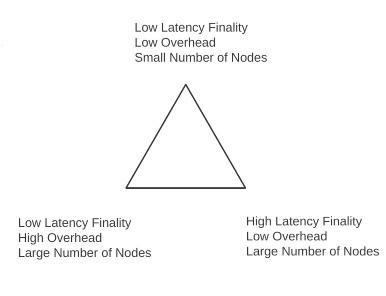
this scenario comes to the cost of finality-latency
Most of the truly asynchronous protocols are only probabilistic. (Similar to avalanche). However this concept is very old already(many papers from the 90s discuss it.
If we have some known max delays we can do this: