
Medical research in the past has attempted to create high levels of trust through peer review conducted by reputable medical journals such as the New England Journal of Medicine. Both methods of generating trust rely on a trusted central authority, either the government or a medical journal. As such, both methods are highly susceptible to fraud via corruption or innocent errors of the centralized authority. This has led to widespread distrust in medical research. Bitcoin operates differently, because it sets up a method of relying on a distributed network based upon a mathematical algorithm, rather than centralized authority susceptible to human error.
Just in USA and EU hundreds of thousands of patients die annually due to doctors’ misdiagnoses. The economic cost connected with complications that encountered in wrong prescription of drugs is more than $100 billion per year.
The main reasons of misdiagnoses are as follows:
The doctors are specialized in certain organs or organism’s system and often can’t see the overall picture;
Lack of experience and doctors’ problems in knowledge often lead to situation, when rare diseases can be not identified;
Lack of time that doctor has for analyzing medical history, the reason is doctor’s high workload (appointments with patients) and also documentation takes significant amounts of time;
The complexity in the definition of the disease according to X-ray, CT, MRI studies, histological examination during nonstandard kind of disease, and also high dependence on subjective experience by an expert.
Based on neural networks, artificial intelligence will allow to make a huge amount of difference in the field of medical diagnosis.
Hi:Health is a global ecosystem analyst based on artificial intelligence. The personal ecosystem for diagnosing a human body in real time.
Applying medical reports of great amount of patients, and also indicators of health-control gadgets, we teach artificial intelligence to ensure early diagnosis of different illnesses and determine previously unidentified cause-and-effect relationship between functioning of body organs and systems of the body and outbreak of diseases. AI will be able to analyze slightest deviations, which human can’t notice, and also to get more accurate survey results (for example, electrocardiogram) resulting from clearing devices of noise. Also with the help of Al it would be possible to monitor effectiveness of treating in real time and correct doctor’s prescriptions.
Hi:Health aims to improve the quality of life and prolong human’s life!
How it works?
Opportunities Options of the platform for a person:
Downloading personal medical data
Secure and anonymous storage of medical data
Rewarding in the form of getting tokens (tokens allow extending the application functionality, purchasing health and life insurance)
Anonymous sales of your data for platform tokens
Analysing data using artificial intelligence for diagnosing diseases at early stages
Purchasing and connecting tested devices (gadgets) for express diagnosing of the organism
Making appointments for undergoing medical examination
Searching and purchasing proven drugs
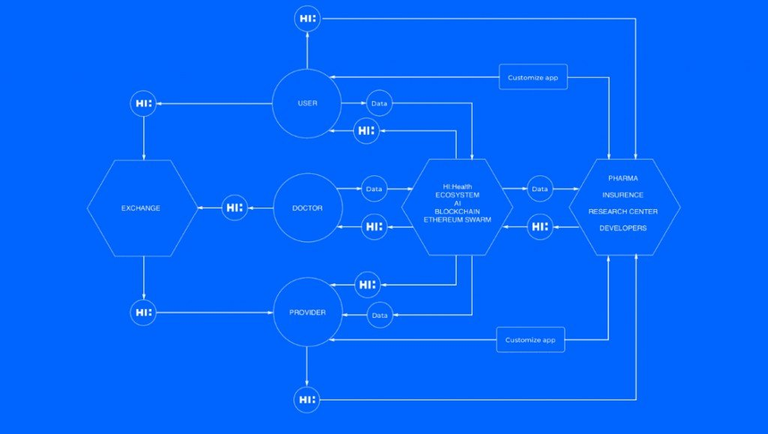
Ecosystem for a doctor
Online consultations of the patients
Sharing of experience with colleagues
Collaborative patients’ treatment
Monitoring the correctness of taking medication by patients
Online controlling the process of patients’ treatment
Identifying the more accurate source of the disease with the help of AI
Access to neural networks on a fee basis.
Ecosystem for Business
Insurance companies receive a more accurate calculation of the probability of occurrence of an insured event. Increase their profits by minimizing the risks of paying insurance premiums. Selling health insurance through applications
Pharmaceutical companies receive statistical reports on the sales of medicines, typical regional (urban) diseases and the effects of medicines on a person. In order to personalize the treatment, the data can be obtained from the DNA database about the predisposition of a person to certain diseases according to his/her geographical residence
Clinics improve the methods of treatment and prevention of human diseases
Research centers and developers can use the benefits of data mining (the detection of titles in databases) in order to obtain patterns. In the current global competition, the knowledge of the discovered patterns can give additional advantage
The ability of artificial intelligence when using algorithms to analyze IR radiation
AI algorithms analyse the data obtained, based on the experience of thousands of doctors around the world and millions of studies, determining the slightest correlation between the changes in gadgets and the results of human tests.Identifies the patterns and sources of a disease
Artificial Intelligence makes recommendations for lifestyle management based on the possibility of disease occurrence
Creates an individual treatment and nutrition plan
Controls the consumption of medications
Tracking the treatment process
What Data Mining is?
Data Mining is a collective name for combination of technologies that detect among the data previously unknown, non-trivial, operationally useful and available interpretations of the knowledge required for making decisions in various spheres of human activity.
Data Mining technologies are a powerful apparatus of modern business analytics and a data research for finding hidden patterns and building forecast models. Data Mining is based not on speculation, but on real data.
Data Mining Tasks
The classification
The easiest and most common Data mining task. In the result of completing the task of classification, one can discover indicators that characterize groups of objects of investigated dataset (classes). According to these indicators the new object can be classified.
The methods for dealing with the task
In order to complete the task of classification one can use some methods including Nearest Neighbor, k-Nearest Neighbor, Bayesian Networks, induction of decision tree, neural networks.
Clustering
Clustering is the logical follow-up to the idea of classification. This task is more complicated; the characteristic feature of clustering is that classes of objects are not predetermined initially. The result of clustering is dividing objects into groups. An example of method for dealing with the task of clustering: “unsupervised learning”, a special kind of neural networks – self-organizing map Kohonena.
Association
Patterns between connected events in a dataset can be identified in the result of completing the task of searching associative rules. Association differs from two previous Data mining tasks with such things: the search of patterns is based not on properties of the analyzed object, but on several events that are occurring simultaneously. The most famous algorithm of completing the task of searching associative rules is Apriori algorithm.
Sequential association
Sequence makes possible to identify temporal patterns between transactions. The task of sequence is rather similar to association, but its aim is to identify patterns not between the events that are occurring simultaneously, but between the events that are temporally connected (i.e. those ones, which occur with certain time lag). In other words, the sequence is characterized by a high probability of a chain of linked in time events. In fact, association is an isolated case of the sequence with a time lag that equals 0. This Data Mining task is also called the task of identifying sequential pattern. The rule of the sequence is that after event X in a certain period of time event Y will occur. For example, after buying an apartment the tenants in 60% of cases during 2 weeks purchase a refrigerator, and during 2 months in 50% of cases a TV set is purchased. The solution of this task is widely used in marketing and management, for example, during Customer Lifecycle Management.
Forecasting
In the result of completing the task of forecasting based on historical data characteristics, missed or future values of the special-purpose numerical indicators are taking into account. For the solution of this kind of tasks, such methods as mathematical statistics, neural networks etc. are widely used.
Identifying deviations or emissions.
The analysis of deviations or emissions. The aim of the task is to discover and analyze the data, which differ more comparing to total set of data, identifying so-called uncharacteristic patterns.
Evaluating
Completing the task of evaluating is limited to predicting continuous values of the indicator.
Analyzing the relationship
The task of identifying dependencies in data set.
Visualization
In the result of this task a graphic visualization of the analyzed data is created. For completing the task of visualization we use graphic methods, which can show existence of patterns in the data.
The example of visualization methods is data presentation in two- and three-dimensional space.
Token
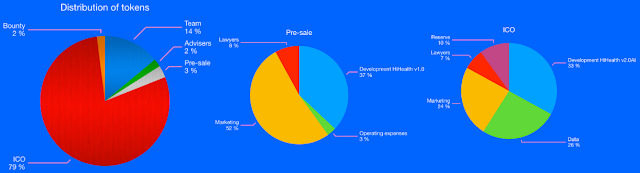
Fundamental element of the future HIH token’s growth is supply constraints, we once produce 1 000 000 000 HIH tokens without additional emissions in the future. Meanwhile demand for tokens will be constantly increasing as the are the means of payment within the ecosystem. Thus, according to basic law of supply and demand, there will be growth in cost of the tokens as demand of them will increasing, and supply will be the same.
Road Map
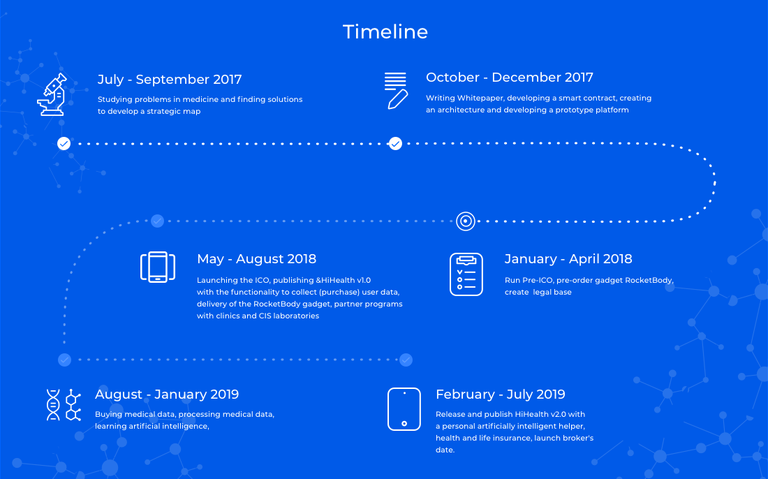
July – September 2017
Studying problems in medicine and finding solutions to develop a strategic map
October-December 2017
Writing Whitepaper, developing a smart contract, creating an architecture and developing a prototype platform, preparing marketing strategy.
January-April 2018
Run Pre-ICO, pre-order gadget RocketBody, create legal base
May-August 2018
Launching the ICO, publishing and HiHealth v1.0 with the functionality to collect (purchase) user data, partner programs with clinics and CIS laboratories
August-January 2019
Buying medical data, processing medical data, teaching artificial intelligence, Buying medical data, processing medical data, teaching neural networks Prediction of possible heart attack by analyzing variety of viewpoints (height, age, EKG/Echo readings, analyses, chronic morbidity) Diagnostics of common complaints or diseases based on blood chemistry and patient symptoms.
February-July 2019
Release and publish HiHealth v2.0 with a personal artificially intelligent helper, launch broker’s date.
August 2019
Health and life insurance
Team


For more information, please visit:
Website: https://hihealth.io/
Whitepaper: https://hihealth.io/assets/_HiHealthWPv0.1ENG.pdf
ANN Thread: https://bitcointalk.org/index.php?topic=3252889.msg33879027#msg33879027
Telegram: https://t.me/HiHealth0
Facebook: https://www.facebook.com/hihealthapp/
Twitter: https://twitter.com/hihealthapp
Author: adam sukses
Bitcointalk Profil: https://bitcointalk.org/index.php?action=profile;u=1958433
ETH: 0x5f3f4Bb6EA24D1B188Ee0457a5B807D5fbf043A0