
Good morning Steemit!
I’m happy to see that I’m getting recognition for the things I’m doing on here. I haven’t done huge projects, nor do I have a huge following, but I only care for progress! Thank you for the feedback I’ve gotten. Today I will be discussing a little bit about the new course I finished called Social Engineering and Manipulation, my information technology studies and new tools in Kali- and don’t worry, this time it will be a learning curve for beginners too!
I was supposed to upload 3 days ago on the 9th, but something came up and the 2-page post I was preparing was lost in the void as I forgot Steemit doesn’t store cached/drafted documents. But shit happens- this one will do the trick!
A few days ago I finished a course called Social Engineering & Manipulation. Social Engineering is a form of attack where you use relationships with people and/or information about them to your own good. There is a 4-way step to do this that looks like this:
Footprint the target
(Dumpster diving, scanning websites for information, Finding relations to the target)Selecting the target with the information you’ve gathered
(Find exploits you can use such as friends and family, work relations, etc)Develop a relationship
(Create a bond of trust that you can use for manipulation)Exploit the relationship
(Collect sensitive account information, financial information- factors that you are looking for)
Now often this isn’t always how a Social Engineer attack needs to look like. Often it could be as simple as step 1 where we only try to find as much information as possible. Personally, I think SE is really interesting because psychology and behavior is something I have a passion for.
If you’re interested, you can check out the SE Toolset or other tools such as:
• Cupp (makes a wordlist for you based on the target information)
• Scythe (an account enumerator)
• Creepy (Gathers geolocation related information from online sources)
• Cewl (a password cracking helper)
• Shodan (search engine without filters)
• Recon-ng (a big framework for gathering information)
• Maltego (a program that allows you to see relationships between emails, servers, website, etc)
If you’re scared of being social engineered, there are a few countermeasures you can do. I will add a link [-----here ----] when I have written that for you.
Information Technology studies
I recently enrolled in an IT course for level 2 students. It’s a 1 year, 2-semester long study. So far, I’ve gone through the basics such as Chapter 1 – HTML, CSS & JS and Chapter 2 – Variables, Data Types & Operators. This week I’m going through Chapter 3 – Control Structures & Looping.
The Information Technology subject teaches you essential basics to become a Software Developer, Web developer or other topics surrounding that category.
It’s rather fun as this type of study is independent and online, giving you the freedom to study and learn at your own pace. I already know a big chunk of the benchmarks that I’m supposed to learn from past experiences- I used to develop websites and have fun with programs already at the start of High School, so it’s something that I’m experienced with.
For those who haven’t dug deep in this topic, let me explain:
• Chapter 1 – HTML, CSS & JS
HyperText Markup Language, Cascading Style sheet & JavaScript are a “trio” of how websites are made nowadays. HTML serves the basic structure of the website, such as text, boxes, titles, etc. CSS allows us to design these structures, giving them colors, styles- general layout and formatting. JS is a Programming Language that allows us to interact with the website or control behavior of specific elements within the websites such as uploading a picture!
• Chapter 2 – Variables, Data Types & Operators
Variables, Data Types & Operators are elements within JavaScript that give us the opportunity to do things within the programming language. Variables are “containers” with information. These containers can store anything inside of them. Let’s say you’re moving houses and you put a name on a box, then similar objects inside of it. Variables are the same thing! And we can store 3 specific types of information inside these boxes. These are the Datatypes. Let’s say one box is called shoes, and it contains a pair of high heels, a pair of flats and a pair of jogging shoes. In our Shoe variable, we have stored three types of shoes- or three types of data. In JS these are called Strings, numbers, and Booleans. A string is any “text” that you write, it could be a name, a sentence or general text. A number is, err, well… A number. A Boolean is simple but may be difficult to grasp: It’s either True or False. For example, I can give a statement “Studying is fun” and it can return False, or it can return True. Now I’ll leave that up to you guys to figure out. ( ͡ ° ͜ʖ ͡ ° )
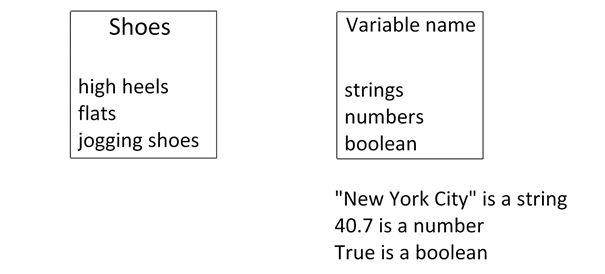
Sometimes we want to add more things into the boxes, so we use an operator called addition ( + ), or we can multiply by using multiplication ( * ). Operators are pretty simple if you succeeded in school… Or at least should be I hope. Anyway. I hope that was an okay explanation!
• Chapter 3 – Control Structures & Looping
Control Structures & Looping is a way to manipulate these variables and information. For example, let’s make a system where every time I procrastinate about working, I need to tell myself to get a grip and just do it. It would look something like this:

Procrastinating is our variable. It contains a Boolean which is either True or False. So, each time I procrastinate, the function automatically tells myself to get a grip. If you want to dig deeper into JS and functions, then you should read more online. Because honestly, I learned this today as I wrote it. I’m a potato when it comes to JS. But at least I try to teach the best I can :^)
But in all summary, control structures and looping is a way to run something such as “if this happens, then do this” or “do this as long as this is true” and such. Simplistic said.
Kali Tools
BAM! Let’s just get right into it.
Today we’re going to go through SE Toolkit, Cupp, Cewl, and Scythe since it’s a part of our Social Engineering chapter today.
Today I was continuing on my Social Engineering and Manipulation course. I tested out the SET (Social Engineering Toolkit) and did a simple test with the web attack option. I tried to make a credential harvester and made a clone of google.com. I was following a course from Cybrary, but the two programs on my computer and on the course seemed different. I wasn't able to understand quite what I was supposed to do as the copy of the website didn't successfully clone into my /var/www.
As I understood it, there should have been files called harvester in here that would be a cloned google and some credential documents. but I can't find any. Let me see if I can look up the IP and the port I set it up with. . .
Still nothing. I probably did something wrong in the process.
Anyway. I understand how the Toolkit works such as how it can be used to manipulate people, such as cloning websites and gathering credentials from people with it. I really suggest you to go take a look for yourself and learn about it if you’re interested in it.
Next thing I'm working with today is Cupp. This is another information-gathering tool for usernames and password attacks. It offers huge wordlists and different features I'll go through.

This is the interactive mode where you can add questions for user password profiling. Here you would put information that you would have found when doing footprinting or other ways of gathering a social perspective. I made some test information I put into the program. As you can see beneath all the input, it made a dictionary and organized it all together.

These dictionaries are really good for gaining a broad perspective of what a password or a username could be. You could use this in instances where wordlists or general dictionaries are needed for pentesting or other brute-force attacks. In addition, it's fast and simple, giving it a very efficient profile.
Next up is Cewl. Cewl is a tool used to subtract words from sites and saving them in a wordlist. It’s a really good tool for finding keywords to a target or other means. Cewl also lets you customize your search by setting minimum word lengths, including meta data, authentication information, proxy support and more. If you wanted to use a customized wordlist in Cupp, Cewl would be good to go for a custom target.

Here I run Cewl and give the URL that I target, then using -w to save it to a specific file. This type of scan is very basic and doesn’t require a lot of skills. The output is only going to be a wordlist full of words from Wikipedia on Dogs, and it would take a lot of time for me to run this scan so I’ll leave the output up to your imagination. :^) Here are more options for those who are interested;
Now Scythe is an account enumerator. It is designed to find ranges of email addresses, user names, and accounts across a range of sites such as social media, blogging platforms, etc. You can find this tool in GitHub by Chris John Riley https://github.com/ChrisJohnRiley/Scythe
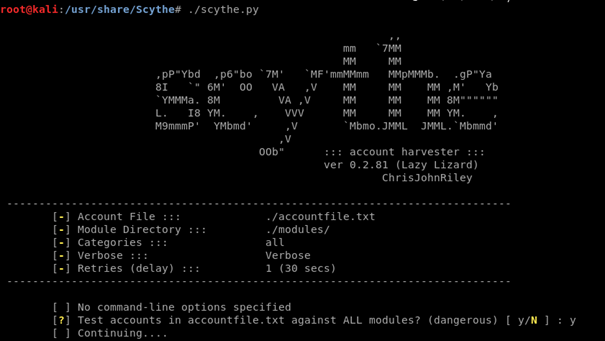

Inside the /Scythe/ folder that Scythe.py exists in, there’s a list called accountfile.txt where the usernames that the program is looking for are. If you wish to change these, then you need to open it in an editor and change the credentials. As you see above, we’ve found some accounts on Hush mail called testuser, which was just a test scan so you guys could see.
All I did was ./scythe.py then I answered yes to testing all modules and let the fun begin.
👍
~Smartsteem Curation Team
Congratulations @genezyz! You have completed the following achievement on the Steem blockchain and have been rewarded with new badge(s) :
You can view your badges on your Steem Board and compare to others on the Steem Ranking
If you no longer want to receive notifications, reply to this comment with the word
STOPVote for @Steemitboard as a witness to get one more award and increased upvotes!