Algorand: A Pure PoS Consensus Protocol
剛退伍,整理了一下當兵時利用空閒時間讀的一些區塊鏈相關知識。更完整的文章可以觀看我的Medium - Algorand共識演算法
相信大家對於PoS,股權証明的概念都不陌生,但是究竟一個PoS的Protocol是如運作的?如何公平的選出下個區塊的生產者?如何保證區塊生產者不能bias下次自己再次當選的機率?這些實行的細節都是需要經過更多特別設計的。今天就來簡單介紹一下Algorand這個相對新的共識演算法。

提出Algorand演算法的是一位圖靈獎的得主Silvio Micali,若是以一個投資者的角度來看,這個專案背後的學術實力是絕對不容質疑的。Silvio稱Algorand為 Pure Proof of Stake 。因為在他的設計中,貨幣的持有者不需要把某數量的貨幣抵押出去(會有一段時間不能使用),或是代理(delegate)給其他人來參與PoS共識機制,而是只要自己錢包裡面擁有balance就可以一同參與這個共識機制。這確實比較符合去中心化的理念,畢竟降低了參與共識的門檻。

個人認為Algorand真正創新的突破在於結合VRF(Verifiable Random Function)的Leader以及Committee抽籤( cryptographic sortition)、防止重要節點遭到惡意使用者攻擊的Participant Replacement機制,以下就針對VRF做一些基本介紹,至於Algorand改良的拜占庭演算法BA*,可以到這裡中看更詳盡的解析。
Verifiable Random Function (VRF)
Verifiable Random Function,中文是可驗證隨機函數。簡單的說,VRF能夠由私鑰(SK)以及訊息(X)產生一組可驗證的偽隨機(pseudorandom)亂數Y以及証明⍴。任何人都可以透過Verify()函數來檢驗這個隨機字串是否真的是該公鑰對應私鑰持有者,依照規定使用Evaluate()函數所產生,而不是自己亂掰的:
Evaluate(SK, X) → (Y, ⍴).產生亂數:輸入私鑰SK, 訊息X,輸出 pseudorandom output stringY以及 proof⍴.Verify(VK, X, Y, ⍴) → 0/1.驗證亂數:輸入公鑰VK, 訊息X, 亂數Y,以及 the proof⍴. 若該亂數確實是由該公鑰對應之私鑰使用Evaluate函示所產生,則回傳1 (true)
為什麼我們需要這個VRF呢?一起看下去吧
Cryptographic Sortition
無論是在何種BFT的共識機制中,都是由Leader以及Committee來完成區塊的發布以及共識決議。例如EOS的dPoS BFT是固定21個BP輪流擔任Leader以及投票者、Zilliqa透過PoW加入Committee進行PBFT共識算法。這些比較直觀的拜占庭共識演算法都有一個共同特徵,就是大家都可以看到下一個區塊的Leader是誰,以及負責協議共識的Committee是誰。這造成了一個可能的風險,就是這些區塊生產者以及Committee成員容易成為有心人是攻擊的目標,無論是DDOS也好,賄賂也好,都讓攻擊者有清楚的目標。這也使的要成為一個Leader或是Committee member的安全門檻更高。
Algorand為了解決這種潛在的風險,利用VRF來掩蓋Leader Selection的步驟。可以想像成:一般的BFT在每一輪開始時公平公開選出Leader以及Committee,Algorand則是像在每一輪開始時公布中獎號碼,每個使用者都可以自己拿自己的票根對獎,中獎的人即可成為下一輪的Leader(或是Committee Verifier),但在中獎者自己表明身分前,沒有人知道誰中獎,也就是沒有人能預測下一輪的Leader以及Committee。當然中獎與否並不是口說無憑,中獎者需要出示中獎証明,而這個証明是大家都可以驗證的,這正是我們剛剛說到的VRF。
在每一輪每一個步驟(step)開始前,每一個使用者都可以透過Sortition()函示,由自己的私鑰配合VRF來檢驗自己有沒有資格成為Leader或是委員會的成員(看VRF的evaluate()函示output是否符合某些規定,機率與持有貨幣成正比)。若發現自己是Leader,該使用者就會準備好要發布的區塊,附上自己確實中獎的Proof一起廣播出去。同理,在接下來每一個需要Committee決議投票的步驟中,每一個使用者都先檢驗自己是否成功被抽中進入委員會,是的話就把自己的投票(或是其他要協議的值)隨著Proof一起廣播出去。
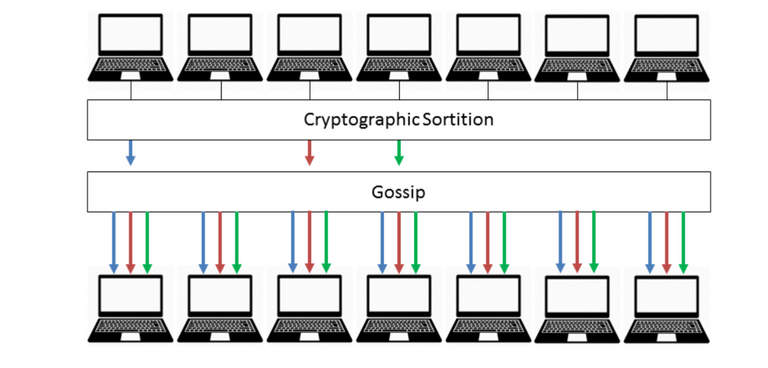
Participant Replacement
上述的設計對安全性有很大的幫助,由於沒有人能預測參與下一輪共識的成員,所以惡意節點無法事前鎖定要攻擊的對象。當一個惡意節點知道某人是這一輪的Leader時,代表這個訊息已經散布到網路之中,該Leader想要廣播的區塊已經讓網路上的其他節點知道,因此已經算是「功臣身退」了,現在才要攻擊它一切都太晚了。同理,在後面所有的共識過程中,在每一個成員廣播出自己決議的同時,投出那一票的瞬間,他們就已經達成了自己此步驟身為委員會成員的義務,再下一個步驟中的又會有新的委員會出現,生生不息的繼續完成每一輪的共識。
這就是所謂的Participant Replacement,每一個共識步驟的決議成員都不同且彼此獨立,使得惡意使用者無法有效率的攻擊這個網路。
細心的你可能會注意到,這種自己在家對獎的模式讓很多人同時成為Leader呢?答案是會的,可能會有多個節點都符合條件成為Leader,但最後大家可以規定簡單的經過hash來排序,決定出Prioroty最高的那個leader,並只幫忙廣播它的區塊。
總結一下,Algorand在每一個區塊leader的產生到共識的每一個決議步驟,都不是事先選擇好,而是當下發現自己有權利參與的節點,在參與共識的同時附上Proof來廣播。這不同於一些BFT模型是節點廣播區塊之後等待某些已知使用者回復簽章,而是Locally收集網路上的各種簽章投票,在幫助gossiping的同時自己運行自己的共識演算法。
小結
Algorand演算法的出現造成了一陣不小的轟動(單然還有BA*也是重點),透過VRF來進行去中心化世界中亂數生產的概念也被越來越區塊鏈應用。這裡僅僅簡單介紹了一下VRF以及他在共識協議中可以帶來的改變,我要先準備打包去日本玩啦,大家再見!
P.S.更完整的文章可以觀看我的Medium - Algorand共識演算法
Congratulations @antonsteemit! You have completed the following achievement on the Steem blockchain and have been rewarded with new badge(s) :
Click here to view your Board
If you no longer want to receive notifications, reply to this comment with the word
STOPTo support your work, I also upvoted your post!
Congratulations,
you just received a 10.70% upvote from @steemhq - Community Bot!
Wanna join and receive free upvotes yourself?

Vote for
steemhq.witnesson Steemit or directly on SteemConnect and join the Community Witness.This service was brought to you by SteemHQ.com