My understating of data overfitting is that: You have a training set, and you come out with a model, but that model is tuned too much that it only works on a specific dataset like the training set. If you apply the model to other dataset (scenarios), the results are bad.
Data are not perfect. In most cases, the training set contains noise, which needs to be filtered out instead of taken into account in the model.
I have also written this post:
The Machine Learning Case Study – How to Predict Weight over Height/Gender using Linear Regression?
Base on the many samples of Weight/Height relations:
Male Weight = -101.24 + 1.061 * Height
Female Weight = -110.20 + 1.062 * Height
I am 174cm, the weight should be 83.2kg, but I am in fact 80.0kg, so according to this model, I am fit, which is soooo much better than the BMI.
大数据这年头很火. 有着大数据 甚至不需要做什么就能发财. 一般来说, 你有了数据 然后就可以通过一些算法进行学习 得到一些模型. 通过这些模型来进行预测.
但是很有可能你的数据 (Training Set – 训练集) 是含有一些特殊例子, 或者称为噪声, 我们需要过滤掉这些数据 或者在学习的过程中不考虑它们. 否则得到的模型就会是一个过分拟合的现象. 过拟表现就是对于当前训练集, 你的模型十分的拟合, 但是这个模型却不适合于其它的场景.
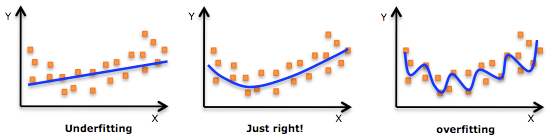
过分拟合 // 图片来自于网络 // Image Credit: Here
推荐数据学习的英文: The Machine Learning Case Study – How to Predict Weight over Height/Gender using Linear Regression?
这个文章学习了大量的 男性/女性 体重对于身高的关系, 得出了两组模型:
男性体重 = -101.24 + 1.061 * 身高
女性体重 = -110.20 + 1.062 * 身高
我身高174cm, 所以体重应该是 83.2kg, 我实际体重是 80.0kg, 所以是不胖滴… 这比 BMI 靠谱多了 . 😂

Thank you for reading my post, feel free to FOLLOW and Upvote @justyy which motivates me to create more quality posts.
非常感谢阅读, 欢迎FOLLOW和Upvote @justyy 能激励我创作更多更好的内容.
近期热贴 Reent Popular Posts
- Just throw away the things you don't need 断舍离
- Microsoft Interview Question – Get the Area of the Triangle 微软面试题:三角形的面积是多少?
- Poloniex is Not A Wallet! How to Transfer SBD from Poloniex to SteemIt? Poloniex 不是个钱包 – 从Poloniex转出SBD到SteemIt的经历
- Team-building Events (Bowling) to celebrate the new release of software 公司组织到剑桥打保龄球
- SteemIt API Tool - Check If Your Followers Have Voted Your Post 撸了一个工具 - 快速检查你的粉丝到底有没有给你点赞!(带 免费API)
- A Quick Tour to British Museum - The British are not returning the china collections to China! 大英博物馆的中国展区就是最好的爱国主义教育基地
- #Travel with me - Windsor Castle (Photography) 再访温莎城堡
Thanks for sharing. I have just completed Andrew Ng' ML course and I am still a beginner in machine learning. There are so much things to learn!
me too a beginner..
Your work is very interesting and meaningful!!! Even though i don't understand the technicality of it.. lol
I love to learn more about AI/AGI development! May i ask, in the case of "Predict Weight over Height/Gender Using Linear Regression", does the machine process given data and "reorganize" it (come up with a certain formula) or does it also give new insights that were previously unknown?
I'm actually wondering that if 2 AGIs are put in the same environment, do they have similar solutions to a specific task, if not, how is it determined which one has better "potential" or "value"? Because for humans, 2 people can have completely different reactions/solutions in the same situation, and it's very complicated to assess it.
Could you please explain this in layman English/Chinese? Thanks a lot! :D
The model can be built upon the dataset. The example here is actually very simple: y=kx+b, where you have lots of x and y pairs of dataset and you need to estimate the best k and b that can fit most (x, y).
HAHA...
160还不胖。那我140是瘦子:)
哈哈。我这是阿Q呢。
Big data brings some fakers 2,needed to be considered seriously.
Everybody is talking about Big Data....
It is not uncommon to purposely try to overfit initially and then work on scaling it back so it generalizes well with unknown data. You want to focus on the best validation score you can get rather than completely eliminating overfitting.
agreed.