「Python的程序中使用集合計算簡化問題處理」,搞得我有點心癢,於是便上網做了些簡單的研究。現在是時候讓我回敬一篇技術文章了,哈哈。都怪 @oflyhigh 昨天發了一篇很有趣的技術文章 -
事先聲明,我在編程方面可不是專家,有錯的話請不要打臉,手下留情。
主題:如何能簡單有效地找出兩個集合之間的差
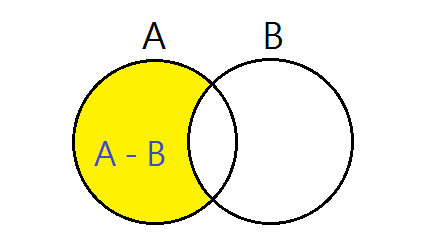
我們先定義兩個集合分別為A和B,而它們的大小分別為 len(A) 和 len(B) 。現在我們希望求的就是 A - B。
o大哥首先提出了一個自家的方式(方法一),用文字寫出來就是:
對於在集合A中的每個元素,如果它不屬於集合B,那麼便把它加到一個新的集合。
(for every element in set A, add to a new set if it is not in set B.)
o大哥其後提出的方法就是用Python的內置功能去求出差集(方法二)。
當然方法二就簡潔得多啦,但簡潔不代表快,到底方法一還是方法二會快一些呢?
雜湊表 Hash table
經過一些資料搜集,我發現Python是用Hash Table的方式把Set實現。甚麼是Hash Table呢?
首先Hash就是把起始資料透過一個函數去變成另一個數值。現在用一下o大哥昨天的例子,假設我們有一個集合:{'oflyhigh', 'ace108', 'laodr'}。經過某個雜湊函數的處理後,假設它變成了{1, 4, 2}。
好啦,現在是時候找出 @deanliu 有沒有投票了!我們先把 'deanliu' 掉進雜湊函數,假設得出 3。於是我們立即前往第3格櫃子,一拉開,哦,櫃子是空的,沒有 @deanliu !於是我們用了一步便知道他不在集合當中了。又例如要看看 @ace108 有沒有投票的話,我們先把 'ace108 ' 掉進 雜湊函數,得出4,立即前往第4格櫃子,拉開,找到 @ace108 了!
當然,如果雜湊函數寫得不好,有機會'oflyhigh', 'ace108', 'laodr'三個人都被掉進同一格櫃子,那麼要找出某人是否有投票的話,拉開了櫃子還要仔細尋找,就慢很多了。
方法一和方法二的大比拼
方法一
回顧一下
對於在集合A中的每個元素,如果它不屬於集合B,那麼便把它加到一個新的集合。
(for every element in set A, add to a new set if it is not in set B.)
針對如果它不屬於集合B,那麼便把它加到一個新的集合。這個句子,一般來說我們只好在集合B逐項尋找,所以用上的平均時間與 len(B) 有關。由於需要對於在集合A中的每個元素都做一次,所以用上的時間需要乘以 len(A)。
準確一點來說,方法一的平均時間複雜度 = O(len(A)len(B))。
方法二
仔細看一看Python的documentation,發現其實它外層的算法跟方法一其實一樣!但是對於如果它不屬於集合B,那麼便把它加到一個新的集合。這個句子,由於Python是用了雜湊表的技術,不論集合B的大小,它一步就做到了!然後由於對於在集合A中的每個元素這個句子,於是跟方法一一樣,用上的時間需要乘以 len(A)。
準確一點來說,方法二的平均時間複雜度 = O(len(A))。
其實時間差異就全在於它不屬於集合B的判斷方法。顯而易見,方法二要比方法一快很多吧!
結論
結論非常簡單,就是Python的內置方法比我們簡單構想出來的方法快得多(這也很合理啊,寫Python的人是專業編程師啊)。不過當集合不是太大,其實兩個方法的時間差別不大,肉眼根本就辨別不了,例如要抓出誰人沒點讚,集合頂多是幾百人,兩個方法時間上相差無幾啦。而且要抓出誰人沒點讚也不是甚麼爭分奪秒的事情吧? XD
怎樣也好,也要多謝 @oflyhigh 帶來了這樣有趣的文章,讓我腦筋有動起來的機會啦 :)
參考
Some good news - you won the Minnows Accelerator Project - Six of the Best MAP1! Go take a look!
感谢分享
不过我的方式一,也不是在B中逐项查找
而是 if a[i] in b:
类似这样的判断,这个是否使用的是hash表?
以及我们遍历a的过程,在a-b做差集是否还是一样需要?(好像你说也需要)那就改成是否有优化?
其实我最喜欢的是简单粗暴的结果
比如随机生成俩超大集合
然后用1和2去计算,并打印出耗时,😄
在python上所有set的object都是用hash表來達成的。
關於a[i] in b,如果b是set,那就一步做完 ( O(1) );如果b是list,那就要逐個查看 ( O(n) )
Reference: https://wiki.python.org/moin/TimeComplexity
所以簡單來說,我猜你當初是打算用list的(?) ,那麼即使用上 'in',也等同於逐個查看,所以也是慢很多啦
我猜python的set difference就是這樣的:
for every element in a:
if a[i] is not in b then copy a[i] to c
粗暴的方法也好啊,但是我不太懂python,懶得學,所以就要交給你啦 XD
谢谢解答
SteemIt API Tool - Check If Your Followers Have Voted Your Post 撸了一个工具 - 快速检查你的粉丝到底有没有给你点赞!(带 免费API,不谢)https://steemit.com/steemit/@justyy/steemit-api-tool-check-if-your-followers-have-voted-your-post-api
好一個小工具!
不用查啦,我给你点了各种赞!
我发现通过这个方法寻找了还没点赞的朋友后可以写个程序自动COMMENT朋友的帖子叫他们点赞。
也可以啊,這樣誰都逃不出你的五指山了 XD
是个好的文章!
謝謝