阿扣:阿特,我们已经学过怎样构建神经网络,得到预测结果了。不过到这里还没有完,还有重要的步骤。
阿特:是什么呢?
阿扣:检验效果,来判断模型是否靠谱。
阿特:是不是根据错误率呀?错误率低就说明更靠谱。
阿扣:没错,是这个思路。不过要怎样计算错误率呢?想想看,我们的模型是根据训练数据「拟合」出来的,也就是说,模型在这些数据中「学习」到了规律。但是这不代表模型在其他数据中也能预测得很好哦。
阿特:是不是像有的专家,在某些领域有经验,但是换一个领域可能跟普通人没什么区别。
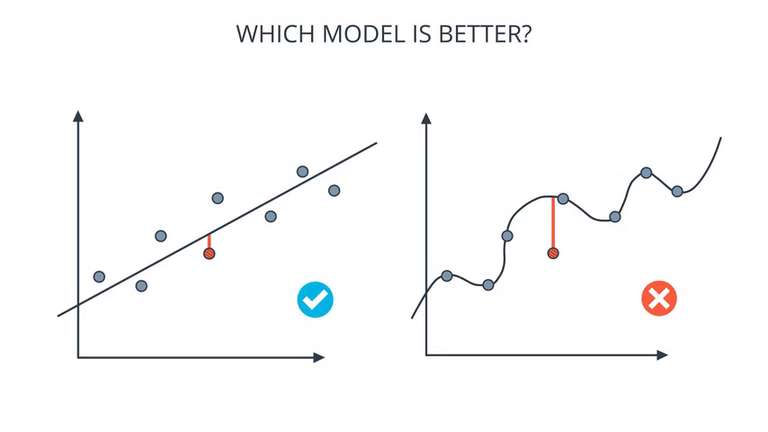
阿扣:说得对。我们的训练模型也是这样,它有可能对给出的数据了如指掌,就像谈恋爱一样,成为某个姑娘的「专家」。但是换一个姑娘,人家喜欢吃什么、爱豆是谁、是不是颜控,它可能就抓瞎了。很多时候,不是模型复杂效果就好,因为那样可能是「过拟合」(over-fitting)了:
Cross validation
阿特:那怎么防止过拟合呢?
阿扣:要学会评估训练效果。当模型遇到新的数据,看看这些数据它预测得咋样。一般的做法是,把训练数据分成 3 部分:
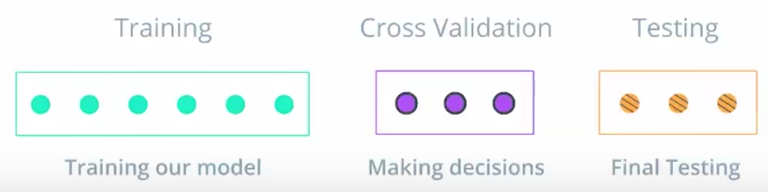
| 数据集 | 作用 | 参考比例 |
|---|---|---|
| 训练集 Training Set | 训练模型 | 70 |
| 验证集 Validation Set | 调整模型 | 10 |
| 测试集 Testing Set | 测试模型效果 | 20 |
阿特:就是把拿到的数据分三份,有一份要存起来,最后才拿出来用。
阿扣:奏四这个节奏。记住啊,千万不要用测试数据来训练模型!不然就「监守自盗」了啊!切记切记!
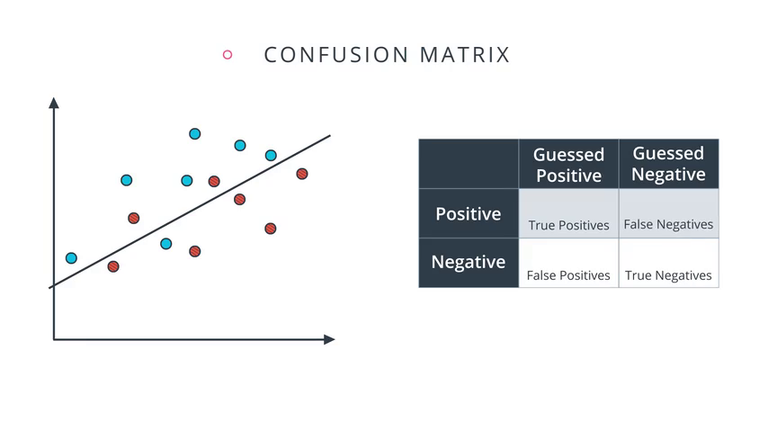
Confusion matrices 混淆矩阵
阿扣:模型在做预测的时候,通常会犯两种错误。我们举个例子——要诊断某个人是不是得病。那么错误会有两种:

- 实际上得病,但是判断为没病 (False Negative)
- 实际上没病,但是判断为得病 (False Positive)
阿特:好惨哦……这种错范不得……
Accuracy 准确率
阿扣:有了混淆矩阵,我们就容易计算出模型的准确率:
Accuracy = (True positives + True Negatives) / Total
阿特:把对的加起来,除以总数。
阿扣:对呀对呀,来,给你留个小测试,看看是不是掌握了:
补充:如何评估线性模型
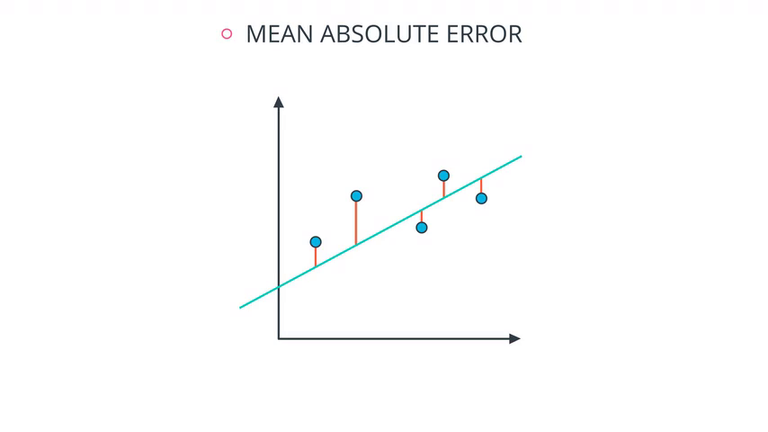
Mean Absolute Error :把每个数据点的误差 $(y-\hat y)$ 加起来
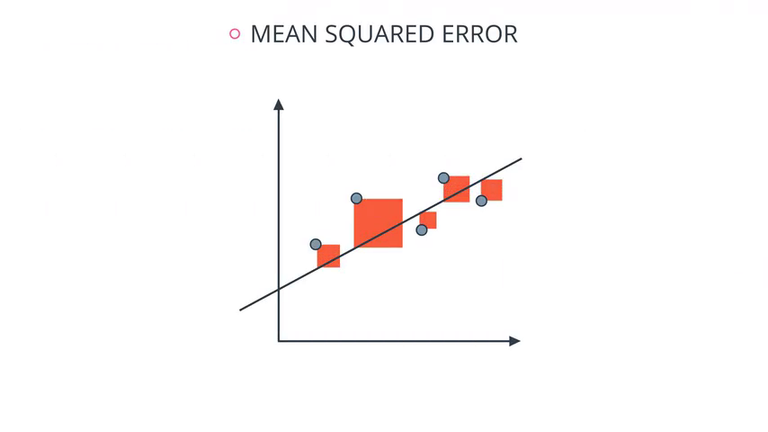
Mean Squared Error :把每个数据点误差的平方项加起来
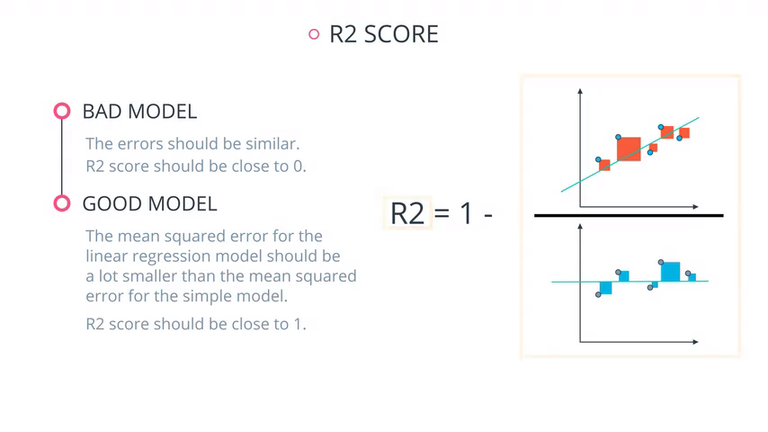
R2 Score :比较训练模型和最简单的模型。
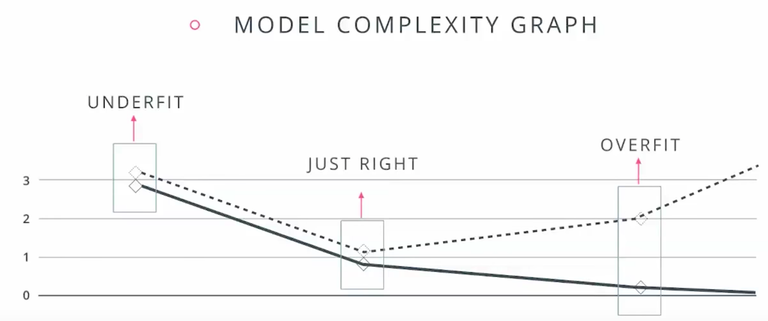
Model complexity graph
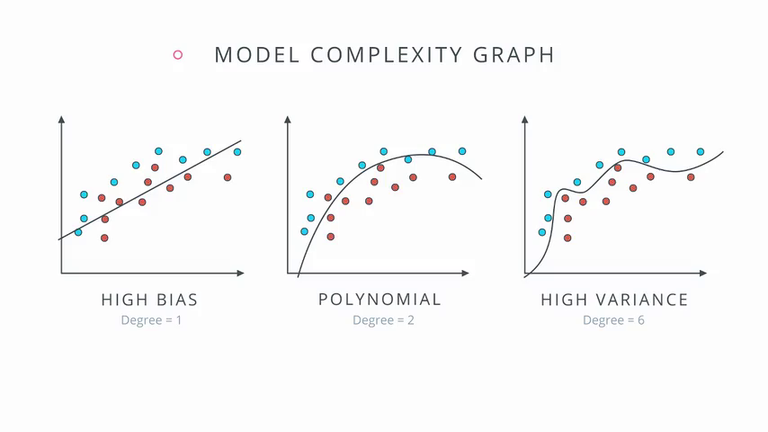
下图虚线表示验证集数据,实线表示训练数据。好的模型,在训练集和验证集上的准确率都比较高。