Standalone模式
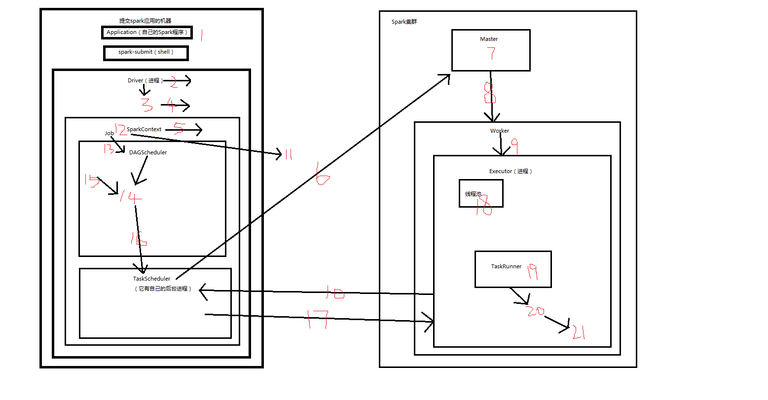
- 提交Spark应用的机器,Application(自己的Spark程序),spark-submit(shell)提交Application。
- Driver(启动一个进程),spark-submit使用Standalone模式提交Application的时候,其实会通过反射的方式,(在本机/客户端)创建和构造一个DriverActor进程出来。
- Driver执行我们的Application应用程序,也就是我们编写的代码。
- 我们编写的spark应用的第一行,先构造SparkConf,再构造SparkContext。
- SparkContext(对象),在初始化的时候,做的最重要的两件事情,就是构造出来DAGScheduler和TaskScheduler。
- TaskScheduler(有自己的后台进程),实际上负责,通过它对应的一个后台进程,去连接Master,向Master注册Application。
- Master,接收到Application注册的请求之后,会去连接Worker,会使用自己的资源调度算法,在spark集群的多个Worker上,为这个Application启动多个Executor。
- Master通知Worker启动Executor。
- Worker会为Applicator启动Executor。
- Ececutor(进程),启动之后,会自己反向注册到这个Application对应的这个SparkContext里面的的TaskScheduler上去,这时TaskScheduler就知道自己服务于当前这个Application应用的Executor有哪些了。
- 所有Eecutor都反向注册到Driver上之后,Driver结束SparkContext初始化,会继续执行我们自己编写的代码。
- 每执行到一个action,就会创建一个job。
- job,会提交给DAGScheduler。
- DAGScheduler,会将job划分为多个stage,然后每个stage创建一个TaskSet。
- stage,stage划分算法。
- 每个TaskSet会提交给TaskScheduler。
- TaskScheduler,会把TaskSet里每一个task提交到executor上执行。所以,之前哪些executor是注册到这个TaskScheduler上面来,那么TaskScheduler在接收到TaskSet的时候,就会把Task提交到哪些executor上面去。(task分配算法)
- Executor(进程),有一个线程池,每接收到一个task,都会用TaskRunner来封装task,然后从线程池里取出一个线程,执行这个task。
- TaskRunner,将我们编写的代码,也就是要执行的算子以及函数,拷贝,反序列化,然后执行task。
- Task,有两种,ShuffleMapTask和ResultTask,只有最后一个stage是ResultTask,之前的stage都是ShuffleMapTask。
- 所以,最后整个spark应用程序的执行,就是stage分批次作为taskset提交到executor执行,每个task针对RDD的一个partition,执行我们定义的算子和函数,这些task在执行完对初始的RDD的算子和函数之后,会产生一个新的RDD,这批task如果在一个stage里面,他会继续执行我们对第二个RDD定义的算子和函数,然后以此类推,这个stage执行完以后会执行下一个stage,到job,直到所有操作执行完为止。
宽依赖与窄依赖
窄依赖,
以wordcount为例,lines RDD,通过val words = lines.flatMap(line => line.split(" ")),得到words RDD,这个过程中lines RDD中的每个partition一一对应到words RDD的每个partition。
第一批task,肯定是,先执行针对hdfs的数据,进行读取,读取到lines RDD中,然后同一批task继续工作,对lines RDD进行操作,执行flatMap算子。
words RDD,通过val pairs = words.map(word => (word, 1)),得到pairs RDD,两个RDD的每个partition也是一一对应的关系。
还是那批task,flatMap算子执行完以后,继续针对words RDD执行map算子。
以上一一对应的关系,就是窄依赖,英文名Narrow Dependency,一个RDD,对它的父RDD,只有简单的一对一的依赖关系,也就是说,RDD的每个partition,仅仅依赖于父RDD中的一个partition,父RDD和子RDD的partition之间的对应关系,是一对一的。
宽依赖,
pairs RDD,通过val wordCounts = pairs.reduceByKey(_ + _),得到wordCounts RDD。
map算子执行完以后,上一个stage就结束了,会切分出一个新的stage,新的一批task会提交到executor执行,针对pairs RDD,执行reduceByKey算子。
宽依赖,英文全名Shuffle Dependency,本质就是Shuffle,也就是说,每一个父RDD的partition中的数据,都可能会传输一部分,到下一个RDD的每个partition中,此时就会出现,父RDD和子RDD的partition之间,具有交互错综复杂的关系,那么,这种情况,就叫做两个RDD之间是宽依赖,同时,他们之间发生的操作,是shuffle。
Yarn-Cluster提交模式
- spark-submit提交(yarn-cluster),客户端与ResourceManager(RM)通信,发送请求到RM,请求启动ApplicationMaster(AM)。
- RM分配container,在某个NodeManager(NM)(随机分配)上启动AM。
- NM,在AM启动(相当于是Driver)以后,反过来与RM通信,AM找RM,请求container,启动executor。
- RM会向AM分配一批contoiner,用于启动executor。
- AM(Driver)又会去找其他的NM,AM连接其他NM,来启动executor,这里的NM相当于是Worker。
- NM(Worker)上的executor启动后,向AM反向注册。
这里,RM相当于Standalone模式里的Master,AM相当于Driver,NM相当于Worker。
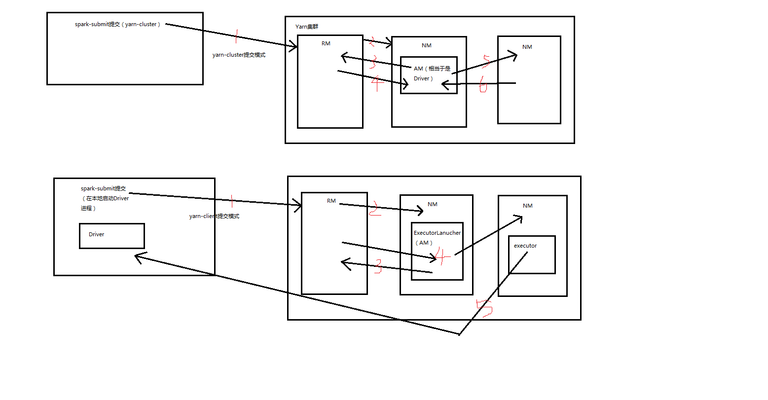
Yarn-Client提交模式
- spark-submit提交(yarn-client),发送请求给RM,请求启动AM。但是还是会在本地启动Driver进程。
- RM,分配一个container,在某个NM上启动AM,但是这里的AM,其实只是一个ExecutorLauncher。
- AM/ExecutorLanucher向RM申请container,启动executor。
- RM分配一批container,然后AM连接其他NM,用container的资源,启动executor。
- NM上启动executor后,反向注册到本地的Driver上。
两种模式的区别,yarn-cluster的Driver相当于就是在NM上的某一个AM,yarn-client的Driver在本地启动Driver进程,在NM上启动的AM,只是一个ExecutorLanucher,ExecutorLanucher只会向RM申请container资源,然后用申请的container资源连接其他的NM,去启动executor。executor启动之后,会反向注册到我们提交应用的本地客户端的Driver进程上,然后通过本地客户端的Driver进程去做其他事情(大量Task的调度,发送到NM上的executor中去执行)。
yarn-client用于测试,因为Driver运行在本地客户端,负责调度Application,会与yarn集群产生超大量的网络通信,从而导致网卡流量激增,可能会被公司的SA(运维)警告。好处在于,直接执行时,本地可以看到所有的log,方便调试。
yarn-cluster,用于生产环境,因为Driver运行在NM,没有网卡流量激增的问题,缺点在于调试不方便,本地用spark-submit提交后,看不到log,只能用yarn application -logs application_id这种命令来查看,很麻烦。
基于yarn的提交模式的spark-env.sh的配置补充
# 加HADOOP_HOME
export JAVA_HOME=
export SCALA_HOME=
export SPARK_MASTER_IP=
export SPARK_WORKER_MEMORY=
export HADOOP_HOME=
export HADOOP_CONF_DIR=
本文首发于steem,感谢阅读,转载请注明。
微信公众号「padluo」,分享数据科学家的自我修养,既然遇见,不如一起成长。

读者交流电报群
知识星球交流群
Congratulations @padluo! You have completed some achievement on Steemit and have been rewarded with new badge(s) :
Click on any badge to view your own Board of Honor on SteemitBoard.
To support your work, I also upvoted your post!
For more information about SteemitBoard, click here
If you no longer want to receive notifications, reply to this comment with the word
STOP