TaskScheduler的初始化机制
TaskScheduler,如何注册Application,executor如何反向注册?
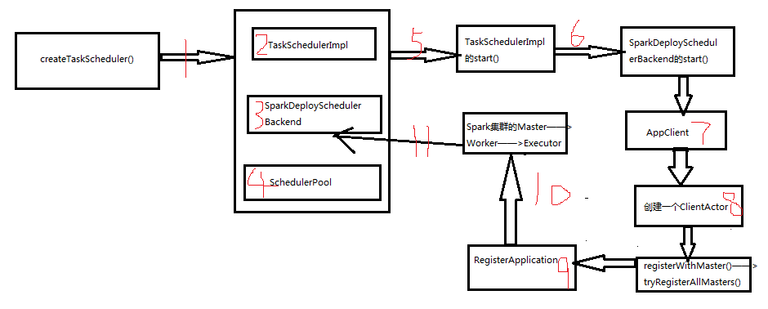
- createTaskScheduler(),内部会创建三个东西。
- 一是TaskSchedulerImpl,它其实就是我们所说的TaskScheduler。
- 二是SparkDeploySchedulerBackend,它在底层会负责接收TaskSchedulerImpl的控制,实际上负责与Master的注册,Ececutor的反注册,task发送到executor等操作。
- 调用TaskSchedulerImpl的init()方法,创建SchedulerPool,当DAGScheduler要让TaskScheduler去调度一些任务的时候,就会把这些任务放到调度池里面,它有不同的优先策略,比如FIFO。
- 调用TaskSchedulerImpl的start()方法,方法内部调用SparkDeploySchedulerBackend的start()方法。
- SparkDeploySchedulerBackend的start()方法,创建一个东西,AppClient。
- AppClient,启动一个线程,创建一个ClientActor。
- ClientActor线程,调用两个方法,registerWithMaster()——>tryRegisterAllMasters()。
- registerWithMaster()——>tryRegisterAllMasters(),向MasterActor发送RegisterApplication(case class,里面封装了Application的信息)。
- RegisterApplication发送数据到Spark集群的Master——>Worker——>Executor。
- Executor反向注册到SparkDeploySchedulerBackend上面去。
TaskSchedulerImpl底层实际主要基于SparkDeploySchedulerBackend来工作。
DAGScheduler
DAGSchedulerEventProcessActor,DAGScheduler底层基于该组件进行通信。(线程)
SprkUI
SprkUI,显示Application运行的状态,启动一个jetty服务器,来提供web服务,从而显示网页。
源码分析
package org.apache.spark,SparkContext.scala
// Create and start the scheduler
private[spark] var (schedulerBackend, taskScheduler) =
SparkContext.createTaskScheduler(this, master)
// 这是我们常用的Sparkt提交模式中的standalone方式
case SPARK_REGEX(sparkUrl) =>
val scheduler = new TaskSchedulerImpl(sc)
val masterUrls = sparkUrl.split(",").map("spark://" + _)
val backend = new SparkDeploySchedulerBackend(scheduler, sc, masterUrls)
scheduler.initialize(backend)
(backend, scheduler)
package org.apache.spark.scheduler,TaskSchedulerImpl.scala
/**
* 1、底层通过操作一个SchedulerBackend,针对不同种类的cluster(standlalone、yarn、mesos),调度task
* 2、它也可以通过使用一个LacalBackend,并且将isLocal参数设置为true,来在本地模式下工作
* 3、它负责处理一些通用的逻辑,比如说决定多个job的调度顺序,启动推测任务执行
* 4、客户端首先应该调用它的initialize()方法和start()方法,然后通过runTasks()方法提交task sets
*/
def initialize(backend: SchedulerBackend) {
this.backend = backend
// temporarily set rootPool name to empty
rootPool = new Pool("", schedulingMode, 0, 0)
schedulableBuilder = {
schedulingMode match {
case SchedulingMode.FIFO =>
new FIFOSchedulableBuilder(rootPool)
case SchedulingMode.FAIR =>
new FairSchedulableBuilder(rootPool, conf)
}
}
schedulableBuilder.buildPools()
}
start()方法,
// start()方法,sparkContext.scala
// start TaskScheduler after taskScheduler sets DAGScheduler reference in DAGScheduler's
// constructor
taskScheduler.start()
// TaskSchedulerImpl.scala
override def start() {
backend.start()
// SparkDeploySchedulerBackend.scala
override def start() {
super.start()
// 这个ApplicationDescription,非常重要
// 它就代表了当前执行的这个application的一些情况
// 包括application最大需要多少cpu core,每个slave上需要多少内存
val appDesc = new ApplicationDescription(sc.appName, maxCores, sc.executorMemory, command,
appUIAddress, sc.eventLogDir, sc.eventLogCodec)
// 创建了AppClient
client = new AppClient(sc.env.actorSystem, masters, appDesc, this, conf)
client.start()
package org.apache.spark.deploy.client,AppClient.scala,
/**
* 这是一个接口
* 它负责为application与Spark集群进行通信
* 它会接收一个spark master的url,以及一个ApplicationDescripition,和一个集群事件的监听器,以及各种事件发生时,
* 监听器的回调函数
*/
def start() {
// Just launch an actor; it will call back into the listener.
actor = actorSystem.actorOf(Props(new ClientActor))
}
package org.apache.spark.scheduler,DAGScheduler
@volatile private[spark] var dagScheduler: DAGScheduler = _
try {
dagScheduler = new DAGScheduler(this)
} catch {
case e: Exception => {
try {
stop()
} finally {
throw new SparkException("Error while constructing DAGScheduler", e)
}
}
}
/**
* 实现了面向stage的调度机制的高层次的调度层。它会为每个job计算一个stage的DAG(有向无环图),
* 追踪RDD和stage的输出是否被物化了(物化就是写入了磁盘或内存等地方),并且寻找一个最少消耗(最优、最小)调度机制来运行job。
* 它会将stage作为tasksets提交到底层的TaskSchedulerImpl上,来在集群上运行它们(task)。
*
* 除了stage的DAG,它还负责决定运行每个task的最佳位置,基于当前的缓存状态,将这些最佳位置提交给底层的TaskSchedulerImpl。
* 此外,它还会处理由于shuffle输出文件丢失导致的失败,在这种情况下,旧的stage可能会被重新提交。
* 一个stage内部的失败,如果不是由于shuffle文件丢失所导致的,会被TaskScheduler处,它会多次重试每一个task,直到最后,实在不行了,
* 才会去取消整个stage。
*/
the Spark UI,
// Initialize the Spark UI
private[spark] val ui: Option[SparkUI] =
if (conf.getBoolean("spark.ui.enabled", true)) {
Some(SparkUI.createLiveUI(this, conf, listenerBus, jobProgressListener,
env.securityManager,appName))
} else {
// For tests, do not enable the UI
None
}
本文首发于steem,感谢阅读,转载请注明。
微信公众号「padluo」,分享数据科学家的自我修养,既然遇见,不如一起成长。

读者交流电报群
知识星球交流群