如果系统只有一个自变量 x,一个响应变量 y (可以有多个应变量,为方便起见,暂假定只有一个应变量) 的 n 次试验的试验样本具有下表形式:
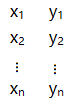
假设过程是线性的,那么就可以写出数学模型,
yi= a +bxi + ei,(i=1,2,...,n) ------(4.1)
其中
e=(e
1,...,e
n)
T 为观察的误差向量,假定它服从正态分布。
这里,a 和 b 是待确定的参数。即,未知数是 a 和 b。求 a 和 b 的过程,使用最小二乘法。俗称
配直线 。
因为实验有误差,算出来的 a, b 也是有误差的,所以叫做估计值。
以后我们用 β 表示估计值,文献标准写法,应该加一个帽子,因为 HTML 加这个帽子太麻烦,我们省略这个帽子。 就是说,我们要配的直线是回归直线
y^= β0 + β1 x-----(4.1')
根据最小二乘原理,为了确定 β0 和 β1, n 个观察应使
Q=∑ni=1(yi -y^i)2
为最小。其中 y^
i 为回归值。所谓回归值就是对应于回归直线上的预报值,
根据
极值原理,要求
∂Q/∂β0= -2∑ni=1(yi-β0-β1xi)=0,------(4.2)
∂Q/∂β1=-2∑ni=1(yi-β0-βixi)xi=0 ------(4.3)
即
∑ni=1(yi-β0-β 1xi)=0, -----(4.4)
∑ni=1(yi-β0-βixi)xi=0。 ------(4.5)
由 (4.4) 得
β0=y--β1x-,------(4.6)
其中
x-=∑ni=1xi/n,------(4.7)
y-=∑ni=1yi/n。 ------(4.8)
由 (4.5) 进而得
β1=(∑ni=1xiyi-nx-y-) / (∑ni=1xi2-nx-2)。------(4.9)
直接从样本求得估计值 β
1,代入 (4.6) 得到 a 的估计值β
0。
β
0称为回归直线的截距,即回归常数,β
1 是回归直线的斜率。
如果过程机制决定回归直线应过坐标系原点 (0,0),此时称回归直线无截距,则由 (4.6) 得
β0 = 0 ,------(4.10)
β1=y-/x-.------(4.11)
规定一个记号代表一种算法,
(x,y) = ∑ni=1 xi yi,
称向量
x,
y 的内积为 (
x,
y) 。把
cf(
x,
y)=nx
-y
- 称为修正量。
在不致误会的情况下, cf(
x,
y) 简记做 cf 。把
Lxy=(x,y)- cf(x,y)------(4.12)
称为差乘和。则
β1=Lxy/Lxx ------(4.13)
如果变量的均值为0,
β1= (x,y)/(x,x) ------(4.14)
不能配一条直线就算,y 与 x 之间到底是不是线性关系,需要满足统计学条件:
r= Lxy/(LxxLyy)1/2------(4.15)
这个关系称为相关系数(correlation coefficient)。相关系数的最大值为 1,称为正相关,最小值为 -1,负相关。
绝对值 |r | 越接近于 1,y 与 x 之间的线性关系越好;
离 1 越远,其线性关系越差。当 r=0 ,线性关系不存在或说没有关系。
用 r 来衡量 y 与 x 之间是否有线性关系, r 需要达到一个起码值(临界值),
相关系数临界值记作 r
α(n-2) 。它依赖于自由度 n-2 和置信系数 α 两个参数。
这个临界值可以查统计学相关系数临界值表。也可以由近似计算得到,在我的计算程序中,由近似计算提供。
如果
r< rα(n-2) ------(4.16)
就说 y 与 x 之间以置信水平 α 相关,否则称以置信水平 α 不相关。
相关不相关,就看 α 与 1 之间的差距的大小。 1-α 被认为是置信概率。
有时简单地记作 P=1-α 并称为 P 值。P 值太小,置信概率太低。在统计学上没有意义。
说在统计学意义上不相关。
由此,当 P 接近但不等于 1,我们说 y 与 x 之间是高相关的,当 P 接近但不等于 0,弱相关。
调整 α 使 r
α(n-2) 从右侧接近 r ,
用一个参数 α 或 P 判断 y 与 x 之间的线性相关关系具有同等效力。
自由度不同的相关性也可以比较。“门槛”是人定的,统计学上定 P=0.95。
具体定多少,依工程具体情况确定。
当目的是认定事物之间的相关性时,为防止误判断,把 α 取得小一些,即 P 取得大一些。
当目的是认定事物之间的无关性时,标准放得宽些,防止“证据不足”。
当把安全性放在第一位,把警戒指数降低,报警频率提高;要想降低报警频率,就把警戒指数提高,
到有更大把握时才发警报。当观察误差比较大时,有时把 α 定得比较大。
当 α>0.3, p<0.7 以后,相关性较弱,点的分布散乱,通常认为不足以证明其相关。
统计学以 0.05 为界,若 α<0.05, p>0.95 说“在统计学意义上显著”,
若 α<0.01, P>0.99 则说“在统计学意义上非常显著”。
这是诉讼判决时用的。在科学研究中,我主张放松,在化工过程中,我使用 p=0.75。
在观察过程中,p=0.6 也不放过。最后认定依据两个原则:统计学上的 α=0.05 原则和实践原则。
所谓实践原则,就是反复实践认为某个判断是正确的,哪怕没有达到 p=0.75 的标准,也作出判定。
在化学实验中,执行 0.05 准则太高,会丢失很多优化机会或者丧失许多判断机会。
平面上矩形区域中的一组点,点的纵横坐标分别组成两个向量。这两个向量的相关系数 r
或置信系数 α 反映这一组点的分布均衡性状况。分布均衡分散,则相关系数趋向于 0,
置信系数 α 趋向于 1, P 趋向于 0。相反,相关系数的绝对值趋向于 1,置信系数 α 趋向于 0,P 趋向于 1,点子分布成一直线。如下图左图点子分布均衡分散,相关系数 r= 0.2,右图点子成一直线,r=1。
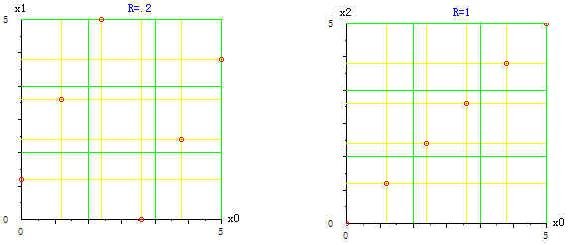 图 4.1. 6个点的不同分布与相关系数之间的关系
图 4.1. 6个点的不同分布与相关系数之间的关系
n 个观察值对其平均值的偏差平方和可以分解为
S总=∑ni=1 (yi-y-)2
=∑ni=1[(yi - y^i)+( y^i-y-)]2
=∑ni=1[(yi - y^i)2+(y^i-y-)2]
=S剩+S回. ------(4.17)
其中,
S
回=∑
ni=1(y^
i-y
-)
2
称为回归平方和,即自变量的变化引起因变量的变化。
S
剩 =∑
ni=1(y
i - y^
i)
2
称为剩余平方和,由实验误差所引起。
根据回归分析理论,回归系数 β 的波动不仅与误差的方差σ
2 有关,而且还与观察点的分布范围大小有关。
x
i 分布越宽,则 β 的波动越小,即对 β 的估计越精确。β 的波动还与试验样本的大小有关,n 越大,估计越精确。
在什么地方取样,样本就是那个地方的信息,它不代表其他地方的信息。
基于局部的回归结果,除了机理模型外不能向实验区域之外延拓,不能预报实验区域以外的值。
可以尝试去预报,未经检验证实无效,那是高风险的。
参 考
- 茆诗松,丁元,周纪芗,吕乃刚编著,《回归分析及其试验设计》,华东师范大学出版社,上海,1981
- T.Hastie,R.Tibshirani,J.Friedman, The Elements of Statistical learning, Springer-Verlag,New York,2001
- J.S.Milton, Jesse C.Arnold, Introduction To Probability and Statistics,(Third Edition ),1995