
This document serves as recommendation and blueprint for Block Producer candidates for infrastructure implementation and secure network configuration for the launch of EOS Blockchain.

Diagram #1, Overview of secure Pre-Launch Mesh network of BP and/or full nodes. Credit to @pythagoras345 for the diagram
We are basing above network topology based on community discussions around security of the network.
These recommendations are based on the following facts:
- EOS software, while functional, has not been vetted for security weaknesses. It should not be directly exposed to open Internet connections.
- Block Producer’s (BP) private keys, used for signing new blocks, are currently stored in plain text on BP server file system.
- Security of each BP node will depend on configuration of all services running on each server exposed to Internet.
- There is significant incentive for attackers to gain access of BP node and/or derail EOS launch process.
Hence we need to take additional steps in shielding each BP node from possible attacks and decreasing attack surface to a minimum required to run the network.
We see that a fully meshed, private tunnel network with encrypted peer to peer communication between BP nodes will go along way in protecting servers running BP nodes from a range of possible attacks.
The BP community have successfully tested building mesh network of nodes using WireGuard software and then starting EOS Mainnet on top of this private tunnel mesh network.
The goal is for each BP server to not be exposed to the Internet over a public IP address and only link over private tunnel to full nodes and other BP nodes.
Below is a deployment diagram for EOS Tribe as an example of such configuration:
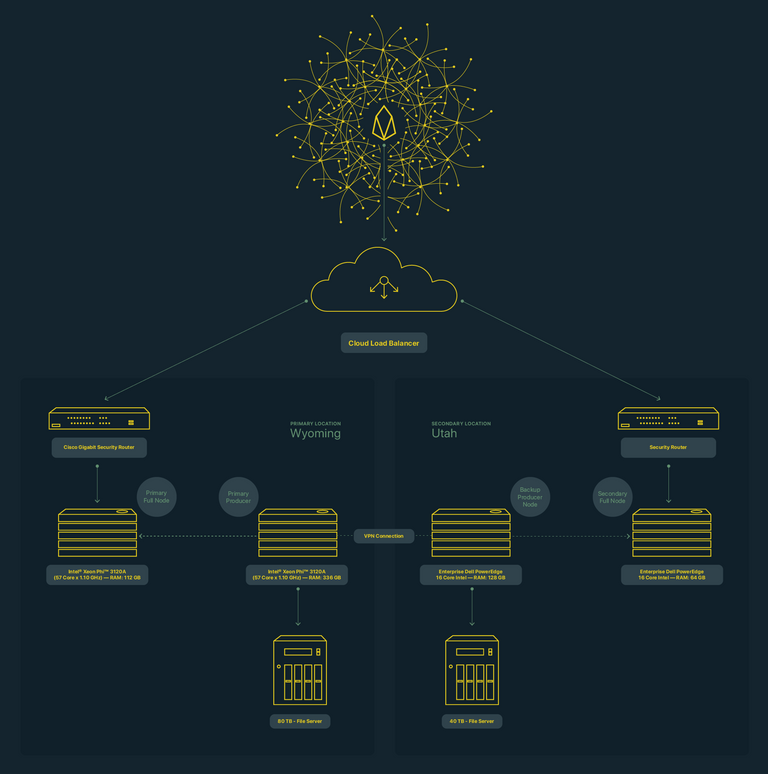
Diagram #2, EOS Tribe Deployment Diagram as an example
Consider primary location only: a full node is exposed via security router to the Internet using Cloud Load Balancer.
Then Primary Producer (BP node) links to full node for synchronization over VPN channel.
There is no direct route from Internet to reach Primary producer node limiting any potential attacks to producer node to a minimum.
The Cloud Load Balancer serves two purposes:
- It protects server endpoints from DDoS attacks.
- It reroutes traffic to a secondary location should a primary location become unavailable (due to power loss, DDoS attack, etc).
There are several consideration with this design that BP needs to consider:
1. SSH access to producing node server for maintenance purpose:
Since there is no direct route to BP node – the reasonable question would be how a BP candidate will be able to gain SSH access to BP server node for maintenance and upgrades.
And the solution would be to use full node as a jump point to a producing server.
Since between both machine established a trusted VPN connection, gaining access to full node from outside of the system, user will be able to connect over SSH to BP server.
Our recommendation is to store SSH keys for access to Producing node server on a full node server and use secure password for additional security.
Same rule applies for SSH access to full node server.
2. Full node crash or goes out of sync.
As one can see on Diagram #1 each BP node connects to other trusted BP nodes over VPN network as peers as well as its own copy of full node. Hence if full node becomes unavailable or goes out of sync, the BP node will be able to stay in sync with it’s other BP peers.
3. Primary BP node crashes
A more challenging task is detecting a primary BP node crash and falling back to a backup location.
In situations when both BP and full nodes become unavailable (due to power loss for example), the Load Balancer will be able to detect it and redirect traffic to backup location.
However in a situation when the Primary BP node goes offline while the full node is running it will be more challenging.
We are planning on using heart beat approach with a full node running a cron job periodically pinging BP node nodeos endpoint for alive status and making this status available to Load Balancer over dedicated BP health endpoint.
The BP node will also run regular cron job monitoring nodeos process, restarting it if it crashes and reporting crashes/restart events for maintenance.
If you only have primary location – this is where it stops.
If you use Backup secondary location – continue on:
Secondary BP location will actually run both producer and full nodes as read only full nodes to stay in sync with the chain.
A parallel cron job on secondary BP node will monitor alive status of primary BP node directly over established VPN connection. Should primary BP node become unavailable, the process needs to wait a given period of time to allow for primary node a chance to get restarted, after which time the process restarts the nodeos process using config file, which contains producer keys and switches into production mode.
Should a primary producer come back to life later (due to power restore for example), the restart script at the primary BP node checks the status of the secondary BP node for its producing status, and vice versa.
Connect With Us
- Website - https://eostribe.io
- Github - https://github.com/eostribe
- Telegram - http://t.me/EOSTribe
- Facebook - https://www.facebook.com/groups/eostribe
- Twitter - https://twitter.com/eostribe
- Medium - https://medium.com/eostribe
- Discord - https://discord.gg/Su7pDGt

This is perfect, thanks @eostribe!
I like it! I sent you a little typo screenshot via DM. For the SSH access, here at EOS UK as well as using SSH keys, we're also using a hop box methodology to add an extra layer of protection, which we know works really because we managed to accidentally lock out our Adviser for Security & Infrastructure who couldn't get on even though he had a username and password! Haha. Great work though guys I look forward to seeing you later today in the BPs Infrastructure group hangout for the call.
awesome job, thank you and good luck!