Introduction
There is a wealth of free data available on the Internet in the form of HTML data tables. These tables are typically presented free of charge on the website but with no option to download the data in CSV format. Examples of freely available HTML table data includes baseball statistics, stock price and options chain data, weather data, product rankings, and much much more. The techniques shown in this post can be used to automatically download and process data from any HTML-based website.
Getting Started
Tools Used
In this tutorial we will use Python 3 and Google Chrome. To make it easy to follow this tutorial, I strongly recommend getting the "Anaconda" variety of Python provided by Continuum. Anaconda makes it easy to install dependencies, especially dependencies that have C-linkage. Here is the link to Anaconda.
I also strongly recommend getting Git if you don't have it already. I think most Linux and OS X systems come with it pre-loaded. The materials needed are all provided in this GitHub repository.
Installing Pandas and BeautifulSoup
We will be leveraging two major Python libraries to do most of the work for us. Pandas is a numerical library that makes it easy to handle "mixed" data - that is, data with many different data types mixed together. Mixed heterogeneous data is very often what we are dealing with when scraping data from HTML tables. BeautifulSoup is a powerful language parser that will help us find the tables in the HTML source and help us separate the text from the tags.
If you are using the Git repository, you can create a Conda environment with all the dependencies by using the *.yml file provided in the repo. Use the following command to create the environment:
conda create -f scraper.yml
Another way to do it is to simply create a new environment with the two necessary libraries provided as arguments:
conda create -n scraper pandas beautifulsoup4
This will create a new conda environment with all the necessary packages installed. Conda makes the whole process of finding and installing dependencies super easy!
Once the installation is complete, the script will tell you how to activate the environment. On my OS X machine, I use:
source activate scraper
Inspecting Your Prey With Google Chrome
For this example I am going to pick a website I have never scraped before: ScrapRegister, a website that lists scrap metal prices.
Right-click on the table you are interested in and inspect it's HTML with the "Inspect" function in Chrome.
When you hover over the HTML elements in the Inspect panes, the corresponding part of the webpage is highlighted. This makes the process of finding the tags that represent our data quick and easy.
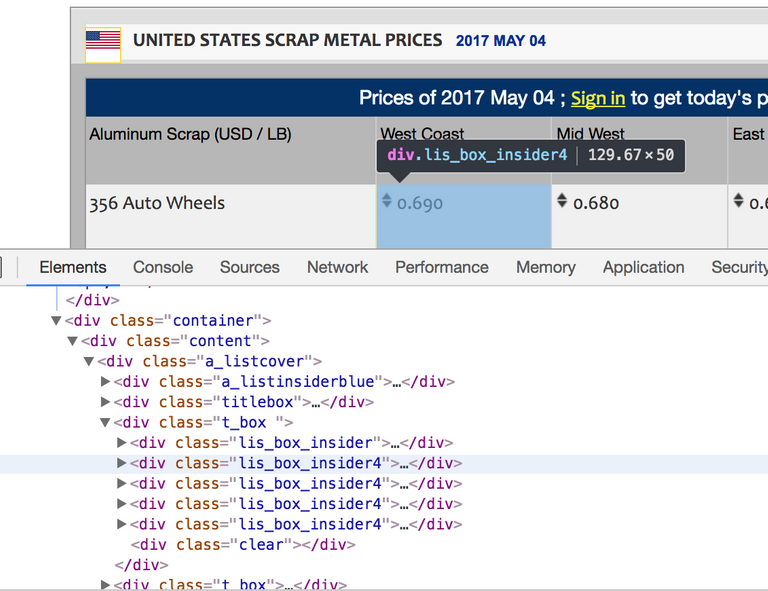
We need to find unique identifiers on these HTML tags that will allow us to automatically extract this data. Typically the easiest way is to use both the type of tag and the "class" attribute of the tag as unique identifiers. First we get the information for the parent, then the header rows and elements, and then finally the data rows and elements. In this example, it is clear to see the following:
- Parent tag is
divand class attribute is"content" - Header row tag is
divand class attribute is"titlebox" - Header element tag is
divand class attribute is"lis_insider"or"lis_insider4" - Data row tag is
divand class attribute is"t_box" - Data column tag is
divand class attribute is"lis_box_insider"or"lis_box_insider4"
We have the information we need to get to coding!
Scripting the Data Extraction
See the "example.py" file in the Git repo for a complete example of the scraping script. Here is a direct link if you're not using the repo on your machine.
The five rules we have applied can be seen clearly summarized by these Python expressions (modified here slightly for clarity):
parent_table = soup.find('div', {"class": "content"})
header_row = parent_table.find('div', {"class": "titlebox"})
header_elements = header_row.findAll('div', {"class": ["lis_insider", "lis_insider4"]})
data_rows = parent_table.findAll('div', {"class": "t_box"})
data_elements = data_row.findAll('div', {"class": ["lis_box_insider", "lis_box_insider4"]})
Using the power of Pandas, we can package the headers and data elements into a DataFrame object in one command:
df = DataFrame([ [ clean_element_text(col) for col in find_all_data_columns(row) ] for row in find_all_data_rows(parent_table) ], columns=headers)
And then in one more command, write the contents in CSV format to a file:
df.to_csv("scrap-prices.csv")
Wrap-Up
The code is quite simple and condensed at only 68 lines of code. It is written such that it should be easy to change the basic rules and URL to work for a different website. Most websites are like this one and can be processed using relatively few rules. Some websites are more difficult and more complicated logic needs to be written to curate the data to our needs. In other situations, the data is not accessible using simple HTTP query and is behind a form. In these cases more work needs to be done to acquire the HTML. As always, you can always keep going down the rabbit hole. I'll be writing more articles that use scraped data to create new data and to create cool visualizations, so stay tuned.
Thanks for sharing.