Neben den Prozessen sind Dateien und Dateisysteme die Objekte, mit denen jeder Anwender und Programmierer zu tun hat; sie bestimmen zu einem großen Teil seine Arbeitsumgebung. Dateisysteme dienen der Verwaltung von Dateien (files). Eine Datei ist eine Folge von Datensätzen, die zusammengehörige Information enthalten. Für den Benutzer wird eine Datei durch ihren Namen (filename) kenntlich gemacht. Oft wird der Typ einer Datei durch eine Erweiterung (extension) des Dateinamens bezeichnet, z.B. *.mp3 für eine Musikdatei oder *.txt für eine einfache Textdatei.
Wir wollen nun untersuchen, wie das Dateisystem intern die logische Sicht auf die physische Sicht abbildet. Während eine Datei sich aus logischer Sicht als eine Folge von Datensätzen darstellt, ist sie aus physischer Sicht eine Folge von gleich großen Blöcken. Auf der Festplatte wird jeder Block mit Zusatzinformation versehen und in einem Sektor gespeichert.
Aus zwei Gründen wäre es wünschenswert, die Blöcke einer Datei möglichst hintereinander auf der Platte zu speichern: Bei sequentiellem Zugriff auf mehrere aufeinander folgende Blöcke wird dadurch die Zeit für die Bewegung der Schreib-/Leseköpfe minimiert. Und bei wahlfreiem Zugriff auf einzelne Blöcke kann man leicht die Blocknummern berechnen:
Wenn der i−te Block der Datei gelesen werden soll und die Datei bei Block b beginnt, so muss der Gerätetreiber einen Leseauftrag für den Block mit der Nummer b + i erhalten. Leider führt der Wunsch nach zusammenhängender Speicherung von Dateien zu demselben Problem der externen Fragmentierung, wie bei der Hauptspeichervergabe: Zwischen den Dateien entstehen Lücken, die sich nicht mehr zur Speicherung längerer Dateien eignen. Eine Kompaktifizierung durch Zusammenschieben der vorhandenen Dateien ist zwar möglich, wird aber wegen des hohen Zeitaufwands in der Regel nicht bei laufendem Betrieb durchgeführt. Man hat deshalb auch beim Sekundärspeicher die Forderung nach zusammenhängender Speicherung aufgegeben und stattdessen Speicherverfahren entwickelt, bei denen die Blöcke einzeln gespeichert werden können, wo immer gerade Platz frei ist. Hier stellt sich die Frage, wie man die Blöcke effizient wiederfindet.
Beispiel : FAT
Eine Lösung könnte darin bestehen, die Blöcke einer Datei in einer Liste zu verketten: In dem Verzeichnis, das die Datei enthält, wäre dann beim Dateinamen die physische Adresse von Block Nr. 0 der Datei aufgeführt; am Schluss dieses Blocks stünde die physische Blocknummer von Dateiblock Nr. 1, und so fort. Diese Idee geht zwar effizient mit dem Speicherplatz um und vermeidet externe Fragmentierung, sie hat aber einen anderen schwerwiegenden Nachteil: Wahlfreier Zugriff wird nicht unterstützt. Um Block Nr. i zu lesen, sind nämlich i Externzugriffe auf die Blöcke 0,...,i-1 notwendig.
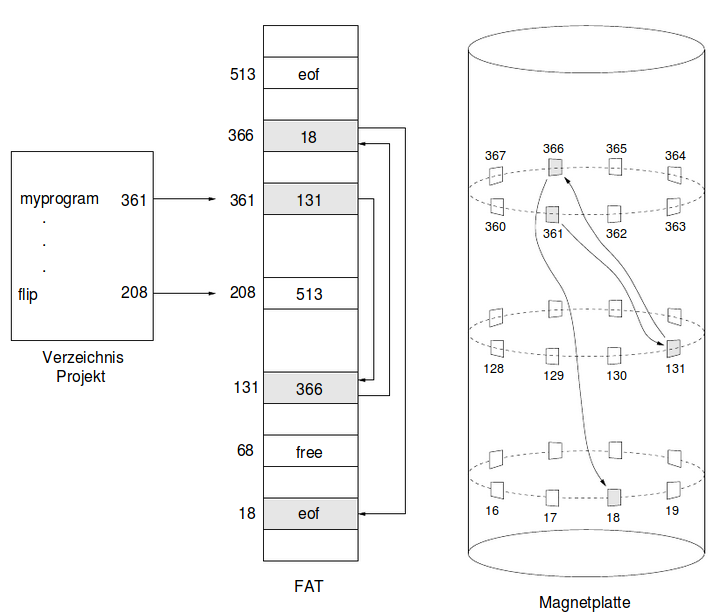
Die Betriebssysteme MS-DOS und OS/2 umgehen diesen Nachteil durch einen einfachen Trick: Verkettet werden nicht die Blöcke, sondern ihre physischen Blockadressen. Sie wird als FAT (file allocation table):
FAT: array[0..MaxBlockNummer-1] of BlockNummer
implementiert und enthält für jeden Block der Festplatte einen Eintrag. Im Dateiverzeichnis steht bei jedem Dateinamen X die physische Adresse i von Dateiblock Nr. 0. Der Eintrag FAT[i] enthält dann die Adresse j des zweiten Blocks der Datei X, in FAT[j] steht die
Adresse des dritten Blocks, und so fort. Für den letzten Block l der Datei hat FAT[l] den speziellen Wert eof, der für end of file steht. Für freie Blöcke lautet der Eintrag free. Wenn eine Datei verlängert werden soll, kann man also die FAT dazu benutzen, einen unbelegten Block zu finden.
Die FAT wird auf konsekutiven Blöcken im Externspeicher abgelegt. Die Blockgröße sollte so bemessen sein, dass die FAT zur Laufzeit in den Cache im Hauptspeicher passt. Dann kann man die physische Adresse des i-ten Blocks einer Datei mit i Hauptspeicherzugriffen herausfinden, also rund tausendmal schneller als bei einer Verkettung der Blöcke im Externspeicher.
Anstatt die Blöcke einer Datei als verkettete Liste zu verwalten, kann man für jede Datei einen Index anlegen. Ein Index ist eine Tabelle, die zu jeder logischen Blocknummer die zugehörige physische Blocknummer enthält. Sie entspricht der Seitentabelle eines Prozesses bei der Hauptspeicherverwaltung. Diese Indextabelle wird selbst auch im Externspeicher abgelegt.
Auch mit diesem Ansatz ist das Problem der externen Fragmentierung beseitigt. Heikler ist dagegen die Frage nach der Indexgröße: Bei einer sehr kurzen Datei ist es nicht zu rechtfertigen, einen ganzen Block für die Speicherung des Index zu verwenden. Wenn dagegen die Datei sehr lang ist, reicht ein einzelner Block hierfür nicht aus; es kann dann sogar notwendig werden, einen Index für den Index anzulegen.
Quelle
Munegowda et. al. Cluster Allocation Strategies of the ExFAT and FAT File Systems: A Comparative Study in Embedded Storage Systems. Volume 154. Juli 2012. DOI: 10.1007/978-81-322-0740-5_82
Du hast ein Upvote von unserem Kuration – Support Account erhalten.
Dieser wird nicht von einem Bot erteilt. Wir lesen die Beiträge. (#deutsch) und dann entscheidet der Kurator eigenverantwortlich ob und in welcher Stärke gevotet wird. Unser Upvote zieht ein Curation Trail von vielen Followern hinter sich her!!!
Wir, die Mitglieder des German Steem Bootcamps möchten "DIE DEUTSCHE COMMUNITY" stärken und laden Dich ein Mitglied zu werden.
Discord Server an https://discord.gg/Uee9wDB
Hello,
Your post has been manually curated by a @stem.curate curator.
We are dedicated to supporting great content, like yours on the STEMGeeks tribe.
If you like what we are doing, please show your support as well by following our Steem Auto curation trail.
Please join us on discord.
@tipu curate
Upvoted 👌 (Mana: 0/10 - need recharge?)
This post has been voted on by the SteemSTEM curation team
and voting trail. It is elligible for support from @curie and @minnowbooster.
If you appreciate the work we are doing, then consider supporting our witness @stem.witness. Additional witness support to the curie witness would be appreciated as well.
For additional information please join us on the SteemSTEM discord and to get to know the rest of the community!
Please consider using the steemstem.io app and/or including @steemstem in the list of beneficiaries of this post. This could yield a stronger support from SteemSTEM.