Black Box
6 months ago, I attempted writing a guide for programming with Hive.
I tried looking at Hive as a black box.
I still like that concept, but after reading it all again, I realized that I've jumped too far ahead.
I'll try taking shorter strides this time.
I also changed the title and theme a little.
I am trying to explain the exact same things as in the first guide, just with a different approach and more elaborate. By the end, the examples I posted recently, should make more sense.
I'll base the guide around the publicly available nodes, and I'll further explain, why that doesn't matter, later, but in this part we need to look at how you would install your own Hive node.

Hive Nodes
Hive is a software with open source code.
So... you can download the code,
compile it and then run a node. (the rhyme!)

block_log
The Hive blockchain itself gets stored as series of events.
The events are all segmented in 3-second intervals, which are called blocks.
But in the end, all events end up in one long file called block_log.
It's almost like a long tape recording.
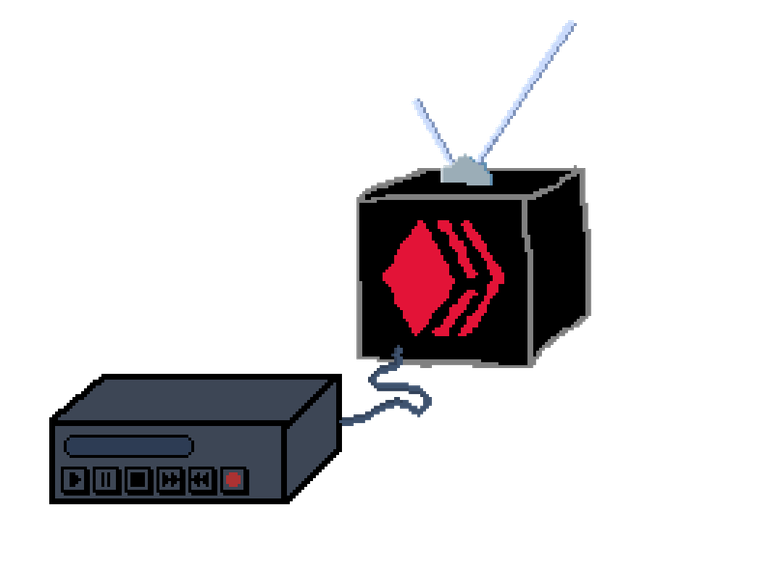
Hived
Compiling the code for a Hive node will leave you with a hived binary.
That's the Hive daemon.
You then need to synchronize your node with the network.
This means, your Hive daemon needs to go through all blocks and replay all state changes that happened up until now.
In the tape analogy, you could load a block_log into you hived tape recorder and fast forward the tape, going over all past events, called indexing.
The Hive daemon watches all events and creates databases in the background.
tables
There are different modules you can activate for your node, called plugins.
What's important here: for the most part, the API calls represent get methods for underlying database tables.
The blockchain itself only documents the changes.
For example: The balance of an account is not directly accessible on the blockchain.
While the blockchain contains all transfers to and from an account, the final balance needs to be calculated;
The data needs to be compiled first, for quick access.
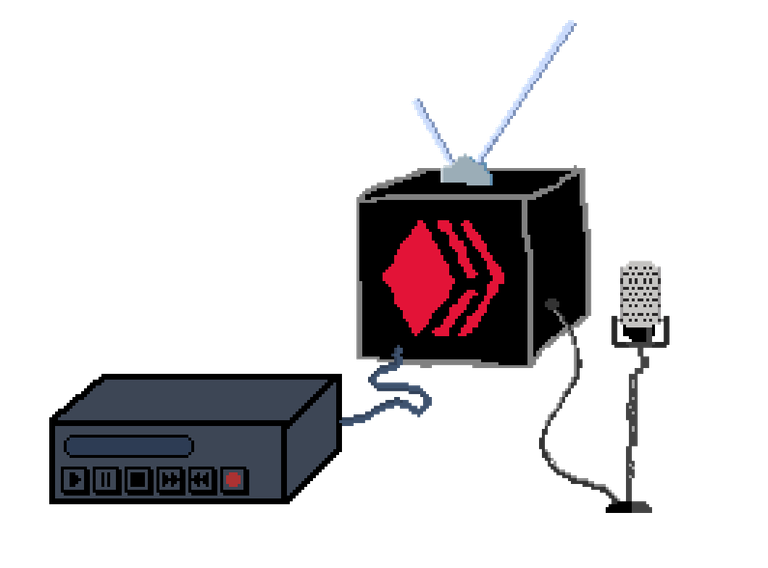
Custom Client
I'll try to write a hacky guide on how to build your own custom client for Hive.
It will enable you to build slim, reliable, customized services for Hive and operate them on a budget.
This is approach isn't the best for all applications; If you want to do historical stuff, analyzing large amounts of data, statistics and such things, HiveSQL is better.
If you don't know, where else to start, this could be a good bet.
However, ironically, I got questions about this stuff myself.
Questions
To some extent, Hive's still a black box to me.
I know how to use some of it, but I don't understand how some of it really works.
Sometimes, all I can hope for is that one of the gods of Hive takes pity and lets themselves down from the Olymp to answer to a mortal.
Wouldn't witness nodes need tables for things like account balance? How do they know, if someone isn't stealing?
block_api.get_block_rangeseems to access a table where the block number is a key. Why is there no public method, which starts from the last entry? At least in SQL databases that's a request with linear speed. (And I could get to the head block in one step). It probably has something to do with block reversibility or rocksDB...
The good part is, that it doesn't really matter; I don't have to fully understand all of it.
If there was a fundamental flaw in consensus finding, serialization, signing and other such things, it would be too lucrative to exploit it - someone would have found it and we'd know.
Notes
- Since I will be using Python requests, you can use the exact same code to access your own node, locally, or the public nodes, via https.
- I will not attempt to sign and broadcast anything for users. I will build a small html + JS based client as example, implementing keychain, because as the developer portal states:
By utilizing Authenticating services, you can eliminate or give more confidence to user, so they are assured their keys are safe. They can securely interact with your application, website or service.
- I have medical issues with my hand, so I asked @manclar to help me with the images for these posts, and paid him for it.
- This is a work in progress and subject to change.
I appreciate all feedback, but please try to not comment 'That's not right' without further explanation. At least provide a link or something.
tagging:
If you want to be included/excluded from this list of subscribers, please let me know.
@chrislybear, @ana-maria, @arc7icwolf, @slobberchops
Sorry I have not got back to you, work has ramped up massively and I am involved in a large project now. My Python coding hat may well stay off for a while, at work it's all Powershell.
Thanks for letting me know.
Best of luck with your project!
It seems to me that you have given a very good explanation of how the blockchain works. I didn't know that events were segmented every 3 seconds. Is there an explanation as to why that time was chosen and not another?
I find this very interesting, and I would like to read an explanation of how this process is calculated or done.
Thanks for the mention and I see that the images in your post look good.
Interesting work, I will be waiting to read your hacky guide, and I know that new witnesses like @daddydog will be interested in taking a look.
pd: get well soon from your injury on your hand.
Hive has a block time of 3 seconds.
Within those 3 seconds all sorts of things must happen; validation of transactions, serialzation, consensus finding and final signing of the block. That takes some time and communication around the globe and stuff.
As I understand it, 3 seconds is a limit, because of the speed which data travels with.
Uhm...
For your account's balance, you just have to go though all blocks and summarize all transfers to and from your account (and all posting rewards and orders on the market and other stuff). In the end, the calculation is a (simple) addition (and subtraction), the result is a sum.
With every further transfer, the sum changes.
So this implies that the larger the user or blockchain data = the longer the response time will be, or does that not affect the process? 😒
No, because there is an API endpoint (and an underlying database table) that provides quick access to that information.
If you wanted to find all necessary information by going through the blocks, it wouldn't really matter, how many transfers an account made - the time consuming part would be going through all millions of blocks, since the account was created. So it would take longer, the older an account is, mostly...
But... That's the whole point of this post.
Please read again 😅
if there are millions of transactions, do it takes longer to find the result?
Suppose there is an account that has been created a month ago and another account that has been created 4 years ago.
Does the one created a 4 years ago spend more time to search through all the millions of blocks than the one created 1 month ago spend less time and is faster? o.O
It would take longer for the older account, if this was the method yes.
But that's the job of the Hive Daemon and when you ask a node for your account's balance, that information has already been prepared and compiled and lies in a database table ready for quick access.
I am begging you: read the post please!
Is this database in the RAM of the local computer? , that is, the PC that is making the query/consult.
If so, I suppose that if there is a lot of data, the PC will need a good amount of RAM available to access that data.(4GB RAM?, 8GB?, 32GB? )
😀 I do, asking to clear the points I want to know more.
Avid reader here! Always ready to learn new coding stuff :)
Next post I'll demonstrate a cool example.
This time, I had to provide some fundamentals...
Oooh, a newbie tutorial! That's great to see!
We need more of these things where things are explained with language understandable for "normies" 😃
Thanks for doing this!
I have picked this post on behalf of the @OurPick project! Check out our Reading Suggestions Posts!
Please consider voting for our Liotes HIVE Witness. Thank you!
Thank you for mentioning and remembering me about that topic! <3
Thank you for remembering and mentioning me.
I probably wouldn't have time to jump into it right away, so I'm bookmarking this post to know where to start. 😉
!ALIVE
!LUV
!PIZZA
(1/1) sent you LUV. | tools | discord | community | HiveWiki | <>< daily@felixxx, @ana-maria
$PIZZA slices delivered:
(2/5) @ana-maria tipped @felixxx