EthreumDB in a nutshell
체인 데이터가 100GB단위를 넘어가면서,
Sync할때 많은 문제들이 발생하고 있으며, 다양한 관련 연구들이 진행중이지만, 현실적으로 다가오기엔 시간이 조금 더 필요한 것으로 보인다.
얼마전부터 이더리움의 DB 분석을 계속 해왔던 이유는, 어떻게하면 노드의 쉬운 네트워크 가입을 지원할수 있을까 고민하다, 첫번째 넘어야 할 허들이 데이터 크기라는 것에 생각이 닿았기 때문이다.
현재 데이터들이 어떻게 구성되어 쌓여가고 있는지 를 분석하고, 좀더 좋은 방향으로 연구를 진행해 보고자, 이 글을 시작했다.
기본 자료형 알기
geth의 경우 chaindata 폴더(leveldb)에 블록 체인의 모든 데이터를 저장하는데, 저장되는 데이터의 종류는 다음과 같다.
1. State Data
흔히 말하는 이더리움 계정의 정보이다.
key, value의 형태로 보자면
[secure-key + hash : address]
[hash , rlp(stateObject)]
[roothash, rlp(trie-node)
의 데이터가 주를 이루며, 흔히 우리가 이야기하는 머클패트리샤(MPT) 자료구조의 데이터를 생각하면 된다.
 =600x350)
=600x350)
DB에는 아래와 같은 식으로 쌓일것이다.
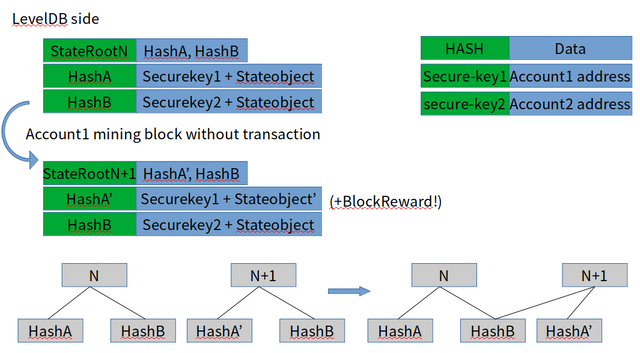
Tip 1.: 블록체인은 흔히들 지갑에 돈이없다고 표현하는데, 그 이유가 여기에 있다. 지갑은 단지 이더리움 계정의 주소와 서명기능만을 가지고 있을 뿐, 해당 주소의 실제 데이터 자체는 stateObject라는 타입으로 노드의 DB에 존재한다.
2. Chain data
흔히 블록체인이라고 표현하는 데이터들이며, 다음의 데이터들이 LevelDB에 저장된다.
Transaction
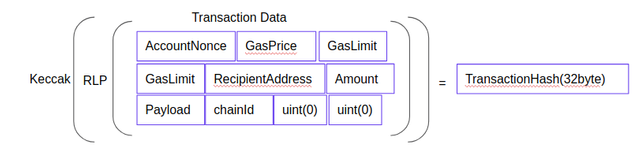
트렌젝션의 자료구조는 이렇게 생겼고, 아래의 그림처럼 트렌젝션 해시나 서명값이 채워진다.
 =400x250)
=400x250)
트렌젝션해시와 서명필드는 다음과 같이 계산된다.

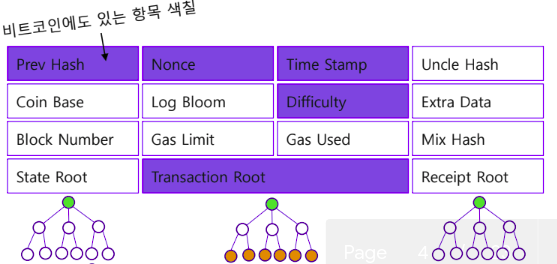
Block Header
블록체인의 데이터의 무결성은 거의 대부분 헤더에 담긴다고 볼 수 있겠다. 더 설명할 필요는 없을듯.
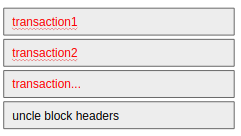
Block Body
블록에 담길 transaction list와 uncle 블록으로 판정된 블록의 header hash list를 저장한다.
Reciept & Log
트렌젝션의 실행결과, 소모가스량 등이 저장되는 영수증과, contract의 event emit에 활용될 Log정보등을 포함한다
 =250x350)
=250x350)
Tip 2. DB에 실리는 추가정보들
Database version, Last[Block,Hash,...]는 sync logic에 관련된 필드들이다.
헤더, 블록등이 현재 어디까지 싱크되었는지를 나타내는 필드로서, Node가 On/Off될때 DB를 읽어 이어 받기를 할 수 있다.
DB를 물리적으로 나누어 보았다
모든 데이터를 각자의 Db에 나누고 싶었지만, 우선 코드 구현상 가장 빠르게 작업할수 있어보였기 때문에 chaindata와 Statedata를 따로 저장하도록 분리를 해 보았다.
(수정: https://github.com/NAKsir-melody/go-ethereum/commit/192a1412677ae0332a46f8ea17ba46ff6e79708c 참조)
먼저, private network single node상에서 데이터를 검증해 본다.
self mining의 경우 블록 confirm 타이밍이 되어야 potential block을 genesis chain에 추가한다.따라서 DB에 안보일수 있으므로 caching관련옵션을 끄고, confirm타임도 1로 변경해야 원하는 데이터를 확보할 수 있었다.
데이터 검증은 아래 처럼 어카운트 2개를 생성한 것이statedb에 쓰여지고,트렌젝션을 통해 데이터를 전송하면, Trie가 추가적으로 써지는 것을 확인하는 방식으로 진행하였다. chaindb에는 나머지 블록정보만 존재하는 것을 확인하였다.
//coinbase생성하고
personal.newAccount("base")
miner.start()
miner.stop()
//1번 블록이 마이닝되었을때 db확인
//추가 계정을 생성하고, 해당 계정으로 1eth전송
personal.newAccount("guest1")
eth.sendTransaction({from:eth.coinbase, to:eth.accounts[1], value: web3.toWei(5,"ether")})
//2번블록 mining
miner.start()
miner.stop()
// statedb의 stateObject를 확인하여 balance가 9, 1 ether가 나와야 한다.
이제 눈감고도 rlp를 깔수 있게 되었다 lol
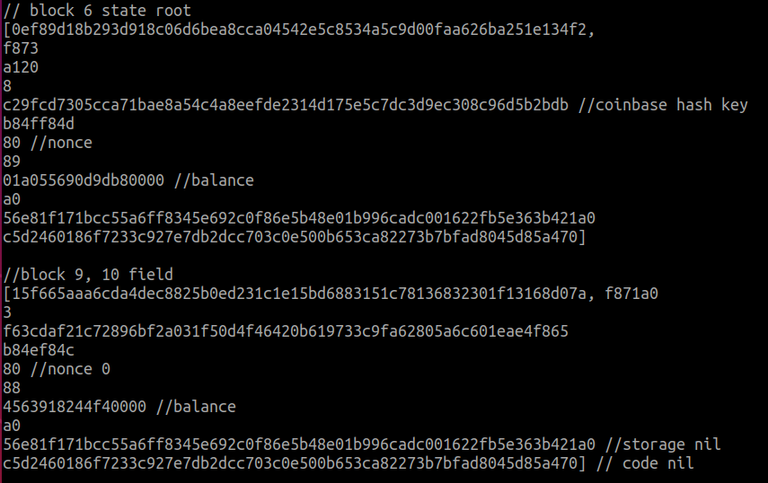
Public 체인의 데이터를 확인해보자
private network테스트에서 생각하지 못한 부분은 db업데이트가 sync시에도 일어난다는 것이다. sync로직에서 기존에 데이터가 1개의 db로 이루어져 있다고 가정하여 stateroot를 chaindb에서 생성하려고 하는 문제가 있었다
수정(https://github.com/NAKsir-melody/go-ethereum/commit/c5cf1f83d05991dc5ccf891edab350d409693141
싱크가 동작하면서, 가장 먼저 작은 스크립트를 만들어 주기적으로 db의 사이즈를 모니터링해봤다.
#!/usr/bin/python3
import subprocess
import time
def du(path):
return subprocess.check_output(['du','-sb', path]).split()[0].decode('utf-8')
if __name__ == "__main__":
f = open('data.csv', 'w')
while True:
string = du('chaindata') + '\t' + du('statedata') +'\n'
print(string)
f.write(string)
f.flush()
time.sleep(3)
f.close()
초기 결과 확인
Testnet 싱크초기의 각 DB의 크기변경 추세를 그래프로 나타내보면, 아래와 같다.
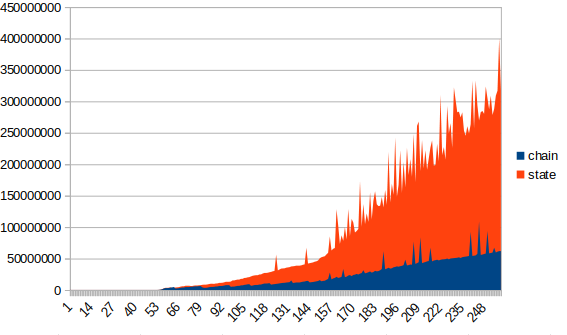
파란색 데이터가 chaindb이고, 빨간색 데이터가 statedb사이즈인데, statedb가 월등히 많은 것을 확인하였다.
초기에는 계정은 많이 만들어놓고 막상 트렌젝션이 별로 없었나? 하는 생각도 들고,
이러다가 트렌젝션이 활성화 되면, 역전하겠지? 라는 생각도 든다. 무튼 데이터 분석 환경은 우선 성공적으로 구축이 된것으로 판단된다.
최종 결과는 진행중,
개인적으로 진행중(반포기중)이다. 사용하는 오래된 노트북의 리소스 문제로 더이상 진행하기 힘들것 같다. 다만, 이러한 시도를 통해 무언가 sync방식을 좀더 변화시킬수 있을것 같다는 생각이 드는것 같다.
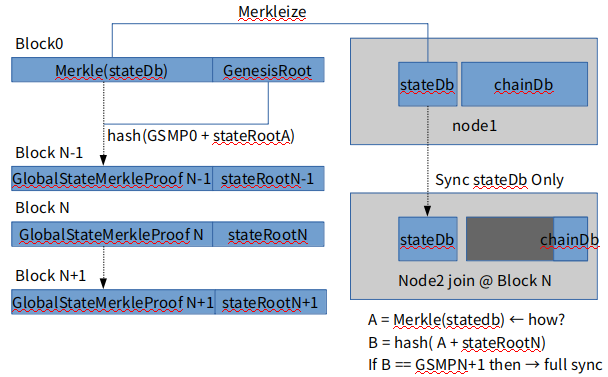
정리되지 않은 스케치이지만, 첫싱크때는 회색부분의 체인데이터가 필요없게 하는 방법을 생각하는 중이다. 싱크 이후에는 요청에 따라 les프로토콜의 ODR로 읽어와줘야 할것이다. 그런데 생각해보면 parity warp싱크랑 그다지 다른거 같지도 않다.
마치며,
백수생활중에 해온 업무를 정리하는 차원에서 글을 정리해보았는데,
이게 연구인지, 혼자놀기의 진수인지 조금 헷갈린다.
이전 회사에서 느끼지 못했던 리소스의 부재에 대한 아쉬움도 있고.
블록체인 왜 하냐고 정말 많은 질문을 받았다. 매번 설명 할때마다 장황 했었는데, 요근래 조금씩 정리가 되었다.
"돈이 될 것 같아서 나왔는데, 코드가 너무 재밌어서 눌러 앉았습니다."
잘못 분석된 내용이 있거나, 수정할 부분이 있다면
[email protected]로 언제든 연락부탁드립니다.
태그에 sct / kr 를 사용해 주시면 더 많은 분들이 응원해주실것 같아요!!
sct : steemcoinpan 이라는 steem 디앱으로, steem 뿐만 아니라 sct 보상도 받을 수 있어요
kr : 한국 커뮤니티... ^^
고맙습니다^^