At this point in the project, four relationships are functional and there is one left to go. We have saved the most complex and difficult relationship for last. For this relationship, we need to retrieve the piece of content that the current author has upvoted in the past seven days where the author contributes the most to the overall weight of the post. This is more complicated in that we need to retrieve the actual votes associated with a piece of content and then perform operations on those votes.
To clarify this relationship further, we need to perform the following steps:
- Grab pieces of content that the author has recently upvoted (in past 7 days)
- For each piece of content get votes for that piece of content
- Get a proportion by comparing the author's contribution to total contribution
- Pick relevant content with the highest proportion
First, we need to filter the votes away from the other operations. At this point the structure should be familiar as it follows the design patterns used by the other four relationships:
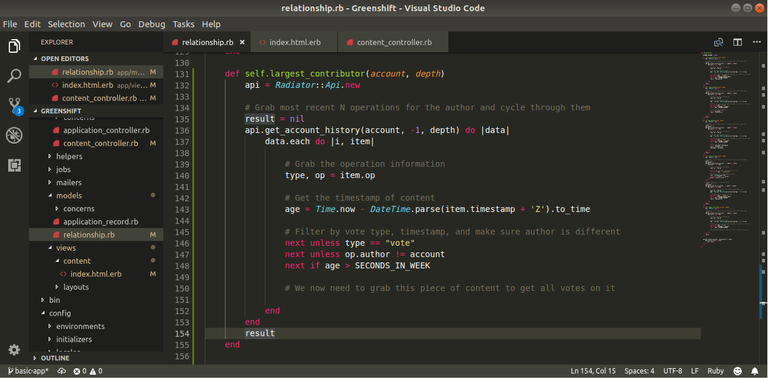
Now that we are getting content that has been voted upon, we now need to take each piece of content and retrieve the votes attached to the content. Unfortunately, the API call that we currently working with doesn't give us this information. So, we will need to make a second call using the get_content method. This method requires the permlink and author of a post which we do get with the current information we get from the blockchain.
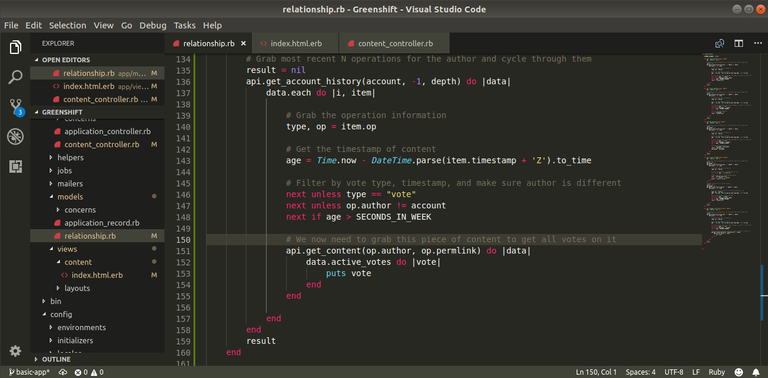
In our second query to the blockchain, we receive a ton of information. For now, we will verify that we are getting votes for a specific piece of content and then cycle through the votes to see what information is given to us. Since this information is given to us in Hashies rather than JSON or regular ruby hashes, we can simply call fields using the dot notation. This allows the clean code we see above.
You notice that we use puts vote in the code instead of passing the result back to the user interface. This allows us to debug through the terminal. We still need to start the server, but now every time we send a request to pull information, we can see the information print to the terminal. Since we are asking for potentially a lot of information, it seems better to check it via the terminal rather than waste time trying to render it into HTML:
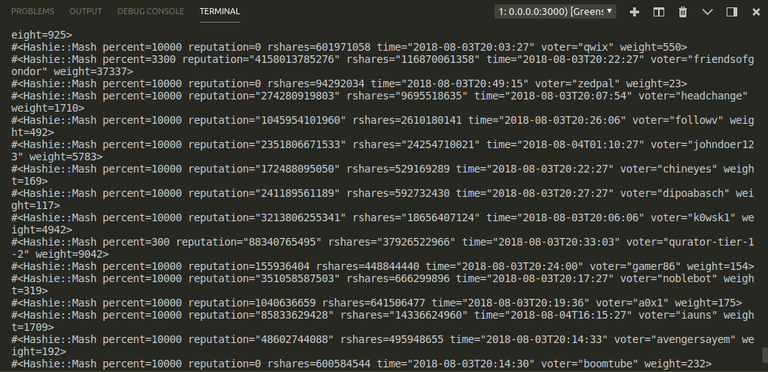
From the second query inquiring into each active vote, we are given:
- The percent of the vote (voting weight)
- The reputation of the voting account
- The rshares associated with the vote
- The timestamp of the vote
- The voting account name
- Some other value called weight
Luckily for us, that value called weight tells us the overall contribution of the voter to the post in context of all of the votes. That is exactly what we need. We won't need to waste time counting rshares and doing any division. We simply will need to find the vote that corresponds with the current author (of the previous post) and then check whether or not that weight is higher than the one we will end up storing. We'll attack this next time and finish up defining the initial implementations for this stage of the project.
Congratulations @qfilter! You have completed the following achievement on Steemit and have been rewarded with new badge(s) :
Click on the badge to view your Board of Honor.
If you no longer want to receive notifications, reply to this comment with the word
STOPTo support your work, I also upvoted your post!
This post has been just added as new item to timeline of Q-Filter on Steem Projects.
If you want to be notified about new updates from this project, register on Steem Projects and add Q-Filter to your favorite projects.