Now that we are moving to using an intermediate database to help facilitate data flow and reduce dependence on the blockchain, it would be good to explore how exactly such a database would work. Last time, we created an updated Post model and defined a Posts database that would store the permlink and author of a post. Both of those things are required to query the blockchain for more information about the post.
So, with this new database, while developing our relationships, we would eventually find permlinks and authors of different posts where we would store that piece of content as a record in our new database. Then, we would return the permlink which we would then use to do two things:
- Reference the record stored in the database
- Be used along with the author (via 1) to query the blockchain
So, in our view, we could then use our new database to query the blockchain to get the title and display that on the screen. Then after selecting a post, we could query the blockchain a second time to get the body of a post and display it on the screen. This is now possible since the Post is now a formal resource and now we can pass around its information around the controller effectively.
But we're still querying a lot. Since we don't need a lot of information for displaying the posts, why don't we add the title to the database? This means that we'll only have to query the blockchain once rather than up to six times for each of the relationships that we have. Sure, we still have to query a lot in the relationships, but this improves efficiency for the moment and eventually we can take a look and making those relationships more efficient.
So in order to add another attribute to the Posts model, we need to generate another migration in order to apply to our schema which defines our database. Last time, we generated an entire model, but this time, we'll simply use the generation function to add another attribute. This effectively adds another column named title to our database:
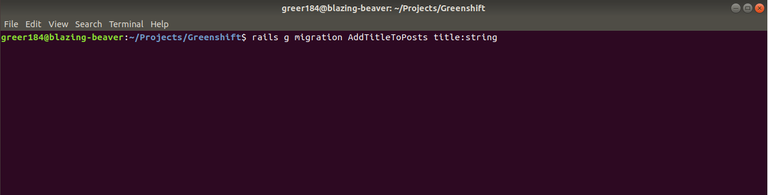
Great, we now have an updated database description. Well not exactly. While we have defined changes to our database, we haven't exactly applied them to the database yet. We actually have to run a migrate job in order to update our schema which I unfortunately forgot last time. But since we just added another migration, now is a great time to update the schema before we add data to it:
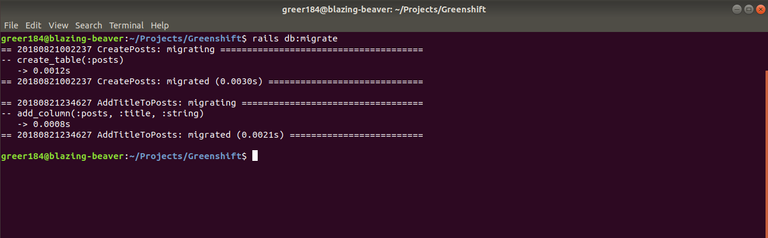
So, now we have a gameplan. We need to begin storing these references so we can lessen the amount of times we call the blockchain. Next time, we'll add our first posts into our database and refactor our old code to reflect this updated method of data flow and storage.
This post has been just added as new item to timeline of Q-Filter on Steem Projects.
If you want to be notified about new updates from this project, register on Steem Projects and add Q-Filter to your favorite projects.