![]()
Comparing BOINC User XML data serialization methods
I've been working on converting BOINC project user XML GZ extracts to more desirable data formats, utilizing xmltodict to simply convert the XML to a dict in Python then outputting to JSON, MSGPACK & ProtoBuffers.
Let's start by comparing file sizes!
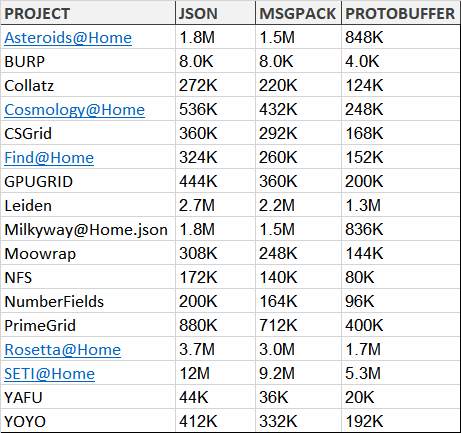
It's interesting to note the difference in file size between the three data serialization formats - the clear winner being Google's protobuffer!
Now let's compare how long it took to read the files from disk:
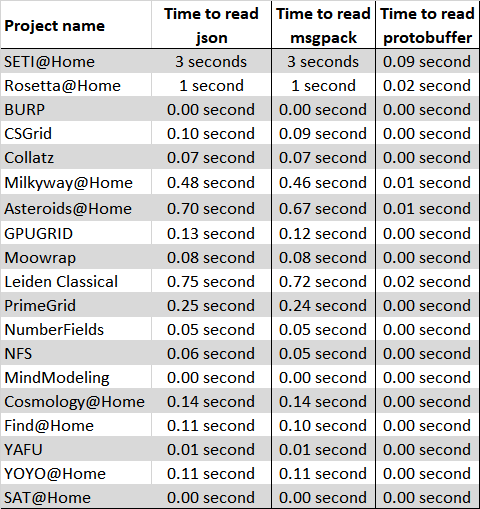
This was performed on a low power laptop with an SSD, it's clear from the above stats that ProtoBuffers are the winner, followed by MsgPack then shortly after JSON.
You can find the constructed data formats within the GRC HUG REST API Github repo.
Have any questions or suggestions for alternative data serialization methods, please do reply below!
Best regards,
CM.
ProtoBuffers seems almost too good to be true. Are there any significant downsides to using ProtoBuffers for serialization? Does it require a lot of CPU to serialize/deserialize? Does it require special software?
(it's Protobuf, @cm-steem :))
The only downside I can think of is that it's binary so it's more difficult to read off the air. I use Protobuf at work to publish data from a microcontroller to an Android app and a web service. Doing that in text with lexical interpretations would be a nightmare.
To further compress the binary serialization we could use 16 byte binary representation of the CPIDs instead of using it's hexadecimal form. I suspect that's where a lot of the storage goes.
Do you think that's possible via flat buffers or grpc?
Do you have more details on how this can be done in python? Do you mean compresing the string or just converting the CPID from a string to binary?
The files would be far smaller if the CPID was omitted, relying on userId instead & perhaps constructing a separate index for userId:CPID for quick lookup.
Never heard of those :)
Sure. Change
User.cpidfromstringtobytesand assign using hex conversion:>>> cpid = '5a094d7d93f6d6370e78a2ac8c008407' >>> len(cpid) 32 >>> cpid.decode('hex') 'Z\tM}\x93\xf6\xd67\x0ex\xa2\xac\x8c\x00\x84\x07' >>> len(cpid.decode('hex')) 16It does make it more tedious to use but there should be a significant reduction in size.
For a fairer comparison I should time how long it took to write to disk.
Downsides of proto buffers is just that it's slightly confusing to work with at first, but now we've got an established proto file it's easily replicated.
Doesnt need much cpu to serialize/deserialize, however I don't have the stats to back that up.
In terms of special software, just the protobuf3 software package - there should be alternative language implementations for interacting with the files in c++ for example.
Very good work! Results like these can be expected from using protobuf as it's machine-readable only. I consider msgpack to be "almost" human-readable :D
Yeah, if you open the msgpack file you can clearly interpret CPIDs in the compressed text, where at the protobuffer text contents look like garbage.
Interestingly enough, if you compress each file type in a GZ file they come out to be approximately the same file size.
Given protobuffer read speeds, you could avoid storing data in memory & rather request it directly from disk for each query, lol.