As part of the Gridcoin Research 4.0 Roadmap (starting here and continuing in a number of other posts), members of the community have proposed to redesign the calculation of magnitude, replacing Recent Average Credit (RAC) with Total Credit Delta (TCD). A big motivation for doing so is the fact that RAC is complicated to calculate, even under the simplest possible assumptions (for details, see this post and references). This has lead to frustration in terms of estimating rewards. On the other hand, TCD is much simpler: it is just the difference in a user’s credits earned on a specific project between superblocks.
The community has already voted to replace RAC with TCD. So what’s my goal here? Well, I want to try my hardest to ‘poke holes’ in either metric and see what ‘exploits’ I can find. This will help us know how to securely transition from RAC to TCD, and also function a sanity check to make sure TCD does what we really want it to.
IF you are busy and don’t have time to read this (somewhat technical) post, that’s ok. Just bookmark it as something to reference when RAC and TCD come up again in future discussions. If you have enough time though, then great – read on!
This post will be the first in a short series of ‘case studies’ each looking at potential ‘exploits’. Let’s begin…
Case study 1: Distribution in time
.png)
Scenario A. Suppose you have a GTX 1080. You’re crunching Einstein@home. Would it increase earnings to 'save up' completed workunits and submit all at once? Or send them in as they are completed? In other words, does it help to strategically 'spike' your RAC?
Scenario B: The same idea as in A. Would it increase earnings to crunch intensely on project X for 1 day, switch to project Y and crunch again for 1 day, then project Z, etc. ? Or stick to the same project?
Scenario C. Suppose you can rent a huge computing cluster for some $ / (FLOPS * unit time). Is your profit margin maximized by crunching super intensely for 1 day ('spiking')? Or distributing the crunching over time? Admittedly, this case is a little artificial, since if mining is profitable you’d want to crunch as much as possible anyways. But let’s suppose you’re right on the margin of profitability. Could crunching super intensely all at once push you from loss and into profit? Or perhaps the cluster is under high demand, so that, for instance, you can only choose one of the two: 1) Crunching at X FLOPS for 1 day, or 2) Crunching at X/30 FLOPS over 30 days. Is option (1) preferable?
Some simplifying assumptions: First, the number of whitelisted projects does not change. Next, the network RAC (call it ‘R_total’) for your chosen project is fixed: R_total = constant. I’ll call your own RAC on the ith day ‘R_i’, starting at i = 0. Let’s also assume RAC is updated daily, and your initial RAC is 0: R_0 = 0.
In terms of these quantities, what are your total earnings? Well, let’s say superblocks arrive daily. Then we should have:
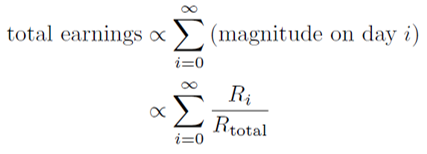
I'm skipping over the technicalities behind actual distribution of rewards, RSA, research age, and all that. Those are quantities I admittedly don't understand 100%. Nevertheless, I hope the above equation for the total earnings is mostly correct, even if the actual rewards distribution over time is more complex.
Now, let’s say you earn X_1 credits on day 1, X_2 credits on day 2, and X_3 credits on day 3. We will assume this is all the crunching you do, although the conclusions that follow will hold regardless of how many days you crunch. Our initial questions now boil down to a mathematical statement: For fixed total credits, X_1 + X_2 + X_3 = constant, does the distribution over X_1, X_2, and X_3 matter?
Answer: No. I'll sketch the steps in the proof. Let r = 1 - 2^(-1/7) = 0.09428… Using the results from here and here, and assuming time is given in units of days, we have
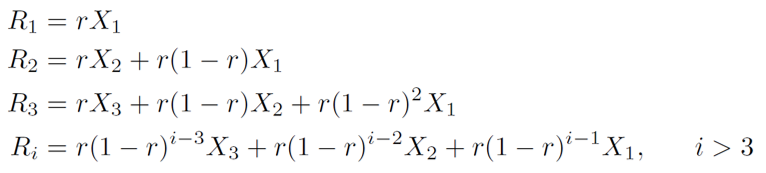
Great. Now let’s add everything up:
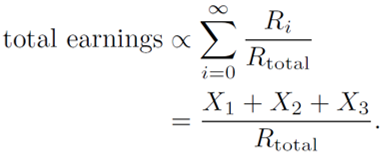
In the second step I have assumed R_total does not depend on i. Under these circumstances, then, it indeed doesn't matter how you distribute your credits. There is one rather obvious caveat, however: R_total does depend on i:
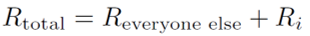
i.e. you are competing with yourself. For small R_i this doesn’t matter, and our previous result holds to a very good approximation. But for large R_i you definitely get better earnings by distributing resources equally across time and projects. This issue was touched on in this post. Top miners, take note!
Now I want to argue that this is actually a good feature. We want the top miners to distribute their resources consistently across time and uniformly across projects. This makes for a more robust network.
In a similar vein of thought, I want to argue that fluctuations in 'R_{everyone else}' are not problematic. This is because 'R_{everyone else}' functions sort of like the 'difficulty' in ordinary hash mining. Just like difficulty regulates how often blocks are mined, 'R_{everyone else}' regulates the mining power devoted to a project, as miners look to where they can maximize profits. So this extra variable shouldn't bother us at all.
That’s it for RAC. How about TCD? I think it should be fairly obvious that exactly the same conclusions hold for TCD. So in the transition to TCD, we shouldn’t have to worry about unfair distribution of resources to maximize rewards. I apologize if this was already obvious to some people. But it’s good to have down on paper. In the next couple posts I’ll look at more interesting ‘case studies’, where RAC and TCD are in fact different in their outcomes. Stay tuned.
One final note. This analysis is done at an abstract and simplified level. In reality, the behavior of RAC is a huge mess, due to a variety of uncontrolled variables; see the posts by @jefpatat on this topic (starting here). Just another reason to get rid of RAC and move to TCD!
I'm not sure this is so good. It effectively punishes crunchers (small and large) who want to contribute to one project over another. If the crunchers had a say in which projects were more important than others this might make sense, but otherwise this creates a highly centralized magnitude distribution which automatically makes all whitelisted projects equal, regardless of thoughts of the community.
This effect won't matter unless someone controls ~ > 10% of the weight on a project. So most crunchers shouldn't have to care at all. From the side of project admins, it maybe wouldn't be desirable to have one huge cruncher make up e.g. 50% of the project's total processing power because if that one cruncher went offline or re-allocated resources, there would be a sizable deficit in available processing power. Same with crunching in time. Project admins want to be able to rely on a stable amount of crunch power. Hence the comment about a more 'robust', or stable, network.
This is what I 100% agree with. It is indeed a flaw in the current system that all projects are 'flattened out' and given the same weight on the whitelist. So some large-scale project with huge computational demand can't even petition for more crunch power than a small project with smaller demands or server capacity. We will have to change this down the road via a consensus mechanism. But I think this point is independent from the point about big crunchers distributing resources.
I've looked at a around 5 or so random samples of CPUs from @parejan's posts here and here and it seems like there can be discrepancies over 100% between the same type of hardware (random example - i3-4160T @ 3.1GHz; 2.52 GRC/day on SRBase, 1.01 GRC/day on TN-Grid, though I looked at samples with low, medium, and high number of results).
I completely agree. However, I don't think the current magnitude distribution addresses that problem. The current incentive is such that I can make more than double on some other project, so maybe I'll go there. As it currently stands, that's the case - there are simply massive discrepancies between how much a person makes running one project vs. another. If everyone followed the incentives, there would eventually be an equilibrium where all projects would get the same amount of computational power, and every piece of hardware would get the same amount of GRC on every project. This would guarantee a "stable" (given stable # of active crunchers/hardware) amount of computational power, but it would mean that people might be crunching projects they don't necessarily want to.
I think that the same piece of hardware should receive the same amount of GRC on any project - unless the community agrees that there should be a ranking, with good justification. A large-scale project should only receive more computational power if that's where people want to send their resources - whether through a decentralized "free-market" choice, or through a community agreed-upon ranking of projects - but not based solely on their need.
Sure. I totally get you here. As it stands, earning potential is not even close to evenly distributed across projects. However, this is entirely due to factors outside the scope of my analysis here.
Here I mean stable in time. I'm not necessarily talking about the time-averaged amount of compute power devoted to each project, just fluctuations about the mean.
Yes, this sounds like a good goal.
//
You're bringing up some good points that will have to be addressed in the future. In short, we need to find ways to relieve the tension among the following:
(1) Interest in projects at the level of individual crunchers,
(2) Interest in projects at the level of the entire Gridcoin network,
(3) (~Equal) project earning potential,
(4) Stable network (minimize fluctuations in project compute power over time), and
(5) Project server capacity (small vs large project).
In my opinion the tool we need is indeed a consensus mechanism on the network to decide how to allocate rewards among projects. But some degree of tension will probably remain regardless, i.e. this is a constraint problem where the optimal solution cannot satisfy everyone.
I am just starting to think through these issues in depth. Pending successful implementation of Gridcoin Roadmap 4.0, we will have to address these issues in Gridcoin Roadmap 4.1 :)
Can you elaborate on this tension?
If I'm reading this comment and the other one you made below correctly - please correct me if I'm wrong - is your goal to stabilize (as much as possible) the amount of FLOP/s that projects receive? Is that what you meant by the tension above?
"Interest at the level of individual crunchers" refers to some average person, e.g. a hobbyist, who wants to crunch on his/her favorite project without having to worry about significantly reduced earnings.
"Interest at the level of the entire network" refers to the community's preference weighted by balance + magnitude, as is the case in polls. In my opinion, major stakeholders in Gridcoin should have at least some say in which projects are prioritized. After all, those who have invested most should have proportionate influence over the future trajectory of the coin. This also gives value to the coins as "influence tokens". This last point seems to be somewhat controversial, but for the time being I support the concept.
Regarding your second comment, yes. I wouldn't want to see FLOPS for any given project fluctuating enormously with time. That might frustrate project admins.
I see what you're saying now. I've posted a couple of times about this from the perspective of incentive structures. I agree that there's this problem regarding a decentralized approach and a centralized approach. I just posted today a possible way to address the issue of getting the same amount of GRC for any given piece of hardware on any project. In those earlier posts there was also a lot of discussion regarding ranking projects. I plan to analyze that separately, and I think I'll address what you mentioned here.
Regarding the consistent amount of FLOPS, yes that's a good point. I didn't think about that in my most recent proposal, but I think it might be taken care of as a side-effect. If you can receive the same amount of GRC by running any project, you're more likely to pick a single project and stick with it, so changes to your total computational power should mostly come from new users coming in.
Quick note for clarification: When I talk about regulating compute power via 'R_{everyone else}' , I'm talking about regulating fluctuations in time, not distribution of time-averaged compute power across projects. Similarly for the comment about top miners. If they are motivated to not concentrate all compute power into one project, this will decrease the risk for fluctuations in that project's compute power over time.