We are going to talk about cryptographic hash functions. We'll talk about their structure and their properties. Later on, we will see their applications.
Hash function definition
An hash function is a mathematical function that:
- can take in input a string of any size and produces a fixed-size output. We will see hash function with 256-bits output, since bitcoin uses one of this kind.
- it has to be efficiently computable: it is possible to figure out the output in a reasonable length of time.
Hash function properties
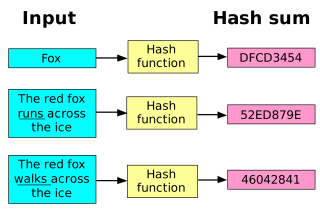
For our purpose, we will need an hash function that is cryptographically secure. There are three main properties that an hash function H must satisfy to be secure:- collision-free: it's almost impossible to find two different input x and y, such that H(x) = H(y). This doesn't mean that there are no-collision at all. In fact, we map a string of any size to 256-bits, so there are only 2^{256} possible output. But, thanks to the H structure it is really difficult to find two texts that map to the same hash;
- pre-image resistance: if we know the hash H(x) it must be really difficult to figure out what x is;
- second pre-image resistance: given an output value y (hash of an element x), it must be really difficult to find another element x' that hashes to y.
Now, let's see in further details this properties and their importance.
Collision resistance
Methods to find a collision
Let's see how to find a collision of a 256-bit hash function, to understand how difficult it is. We will have to pick 2^{130} randomly chosen inputs to have a 99.8% chance that at least two of them are going to collide. It works no matter what the hash function is. But this takes a very, very long time to do. It is necessary to compute the hash function 2^{130} times.
We can say that if every computer ever made by humanity was computing since the beginning of the entire Universe up to now, the odds that they would have found a collision is still infinitesimally small. So this method clearly takes too long.
Now the question is: is there some other method that could be used on a particular hash function, in order to find a collision?
Well, there are many hash function for which it is really easy to find a collision. For example the function that computes the input modulo 2^{256}. It just selected the last 256 bits of the input. One collision would be the values 3, and 3 + 2 ^{256}.
One thing to note is that there's no hash function which has been proven to be collision free. There are just some that people have tried really, really hard to find collisions and haven't succeeded. And so we choose to believe that those are collision free.
Applications of collision restistance
What is good about collision freedom for our purpose? If we can assume that we have a collision-free hash function, then we can use it as message digest.
We know that if x and y have the same hash, then it's safe to assume that they are the same, otherwise that would be a collision.
Suppose that we had a really big file and we wanted to be able to recognize later if compared with another file. One way to do that would be to save the whole big file. And then compare it with the new file.
But, since we have hashes that we believe are collision free, it's more efficient to just remember the hash of the original file. Then if someone shows us a new file claiming that it's the same, we can compute the hash of that new file and compare the hashes. If the hashes are the same, then we conclude that the files must be the same. And that gives us a very efficient way to remember things we've seen before.
Of course, this is useful because the hash is only 256 bits, while the original file might be really big. So hash is useful as a message digest. We'll see later on, why it's important to use hash as a message digest.
Pre-image resistance (or hiding-property)
Why pre-image resistance can't exactly hold
Let's look at a coin flip experiment: we flip a coin and return H("heads") if the result was head and H("tails") if the result was tail.
Now we ask someone who didn't see the coin flip, but only the hash output, to figure out what the hashed string was. That, of course, is really easy. He can compute with two steps the hash of the two possible strings and check the correspondance.
The adversary was able to guess because there were only a couple of possible input values. So, it needs to be the case that there's no value of x which is particularly likely. The way we're gonna fix this problem with common values of x, like heads and tails, is to take x and concatenate with it to a value r, chosen from a random distribution. Using H(r|x) instead of H(x), it's infeasible to find x.
Application of pre-image resistance
We want to do something called a commitment. This is the digital analogy of taking a value, a number, sealing it in an envelope and putting that envelope out on the table, where everyone can see it. Doing that, you've committed to what's in the envelope and, until it's closed, it's secret from everyone else. Later, you can open the envelope and get out the value, but it's sealed. So commit to a value and reveal it later. We wanna do that in a digital sense.
To be more specific, our commitment algorithm will do two things:
- commit to a message: returns two values a commitment and a key. The commitment is the same as the envelope put on the table, the key is necessary to open it
- later you reveal someone the original message and let him verify that it correspond to the original, providing him the commitment and the key
- given the commitment and the envelope on the table, someone just looking at it can't figure out what the message is (pre-image resistance)
- when you commit to what's in the envelope, you can't change your mind later (collision resistance)
How to commit a message
In order to commit to a value message, we're going to generate a random 256-bits value and call it the key. Then we're going to return the hash of the key concatenated together with the message, as the commitment. When we provide someone the key and the message, he can compute the same hash of key concatenated with the message and check the correspondance.So the hash function is used both in the commitment and in the verification. And we use the random key to improve the security as explained in the first paragraph regarding pre-image resistance.
Second pre-image resistance (or puzzle-frendly property)
Further details about second pre-image resistance
Let's see another way to express this property. Given an output y of the hash function, if k is chosen from a random distribution, there's no way to find an x, such that the the concatenation of k and x hash to y: H(k|x) = y.
This applies when someone wants to target the hash function and see when it outputs value y. If there's part of the input that is chosen in a suitably randomized way, it's very difficult to find another value that hits exactly that target.
Application of puzzling property
We're going to build a search puzzle: a mathematical problem, which requires to search a very large space in order to find the solution. There's no shortcuts, a way to find a good solution, other than searching that large space.
The idea is that we're given a puzzle ID, chosen from very spread out probability distribution and a target set Y, which someone wants to make the hash function fall into. We wanna try to find a solution x such that H(k|x) belongs to Y. So, Y is a target range or a set of hash results that we want to match, ID specifies a particular puzzle, and x is a solution to the puzzle. The puzzle-friendly property implies that there's no solving strategy for this puzzle, better than just trying random values of x.
So if we want to define a puzzle that's difficult to solve, we can do it using hash function, as long as we can generate puzzle IDs in a suitably random way. We're going to use this puzzle later, when we talk about bitcoin mining. That's the sort of computational puzzle we're going to use.
SHA-256
We've talked about three properties of hash functions and one application of each of those. Now let's talk very briefly about the particular hash function we're going to use. There are lots of hash functions used for cryptographic purposes, but the bitcoin uses SHA-256, which is a pretty good one. Basically, it works like this:
- it takes the message you're hashing, and it breaks it up into blocks that are 512 bits in size. The message size, in general, isn't necessarily a multiple of block size. To make it a multiple of block size, we will use some kind of padding (i.e. a 1 followed by a certain number of 0)
- you start with the 256-bit value called the IV, specified in the standards document and the first block. This 768-bits string goes through a special function c (compression function) that outputs a 256-bits string
- Then the compression function is applied to the concatenation of the first output and the second block
- the process is repeated until the end of the blocks, the hash is the final 256-bits output