最近打算把中文区的文章信息保存到数据库中,然后分析一下这些数据。本来想这应该是一个非常简单的程序。但在实现的过程中遭遇了这个utf8mb4编码的问题。下面把整个排错过程记录一下。

图源:Pixabay
问题的出现
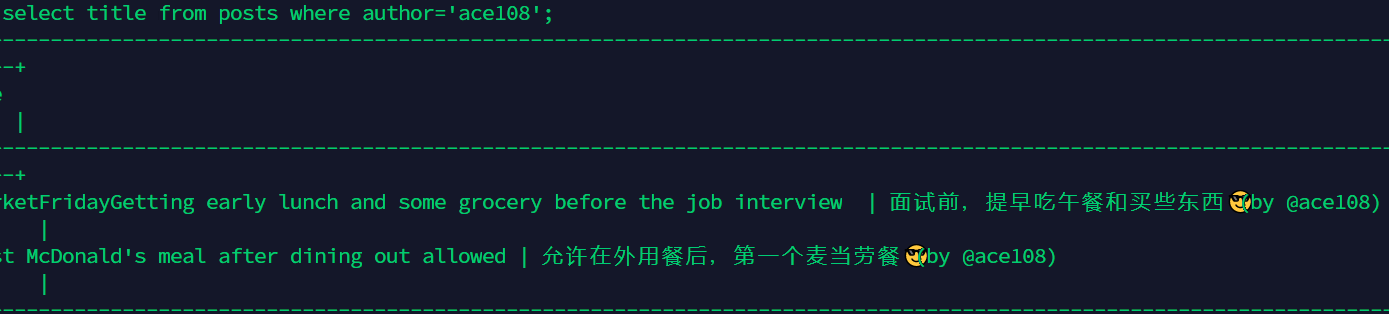
程序很简单,就是读取中文区中的最新N条文章,然后保存到数据库中。对于一般的文章,没有任何问题。但对于个别的文章,比如 ace108 的一篇文章,
📷Flirting with Silver I | 追求银I😎
保存的时候出错了:
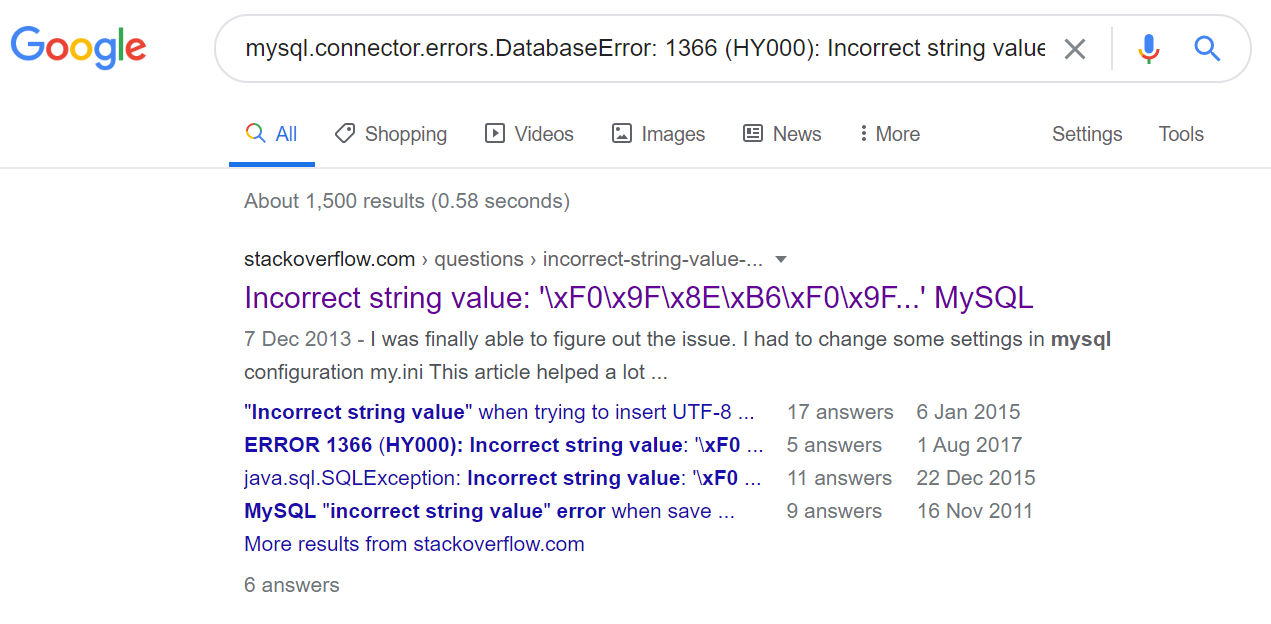
mysql.connector.errors.DatabaseError: 1366 (HY000): Incorrect string value: '\xF0\x9F\x93\xB7#M...' for column 'title' at row 1
仔细查看了一下,似乎是因为文章标题中出现了表情符号所致的。
解决方案
在网上查找了一下,很多人都遇到过类似的问题,似乎我的初步判断是正确的。问题在于:在默认设置下,不支持表情字符的编码。
那么,什么是utf8mb4字符集呢?查阅了一下MySQL的官方文档:
utf8mb4 is a superset of utf8mb3. The utfmb4 character set requires a maximum of four bytes per multibyte character.
我们平时用的 utf8 其实就是MySQL中的 utf8mb3。而 utf8mb4 是我们常见的 utf8 的父集,以4个字节来保存多字节字符。不难想象,utf8mb4 能够表示的字符范围更广,比如包括那些表情符号。在MySQL中建议使用 utf8mb4,它是完全兼容 utf8mb3的。
知道了原因,解决方法就很简单了。
首先,更改表的字符集:
ALTER TABLE posts CONVERT TO CHARACTER SET utf8mb4 COLLATE utf8mb4_bin;
接下来,更改 “title” 这一列的字符集
ALTER TABLE hive.posts MODIFY COLUMN title VARCHAR(200) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL;
在Python程序中创建数据库连接的时候,指定“utf8mb4”字符集:
hivedb = mysql.connector.connect(
…...
charset = 'utf8mb4'
)
至此问题成功解决,表情符号也能保存到数据库中了。