这里将会从sampleRNN逐步优化,来引出attention。
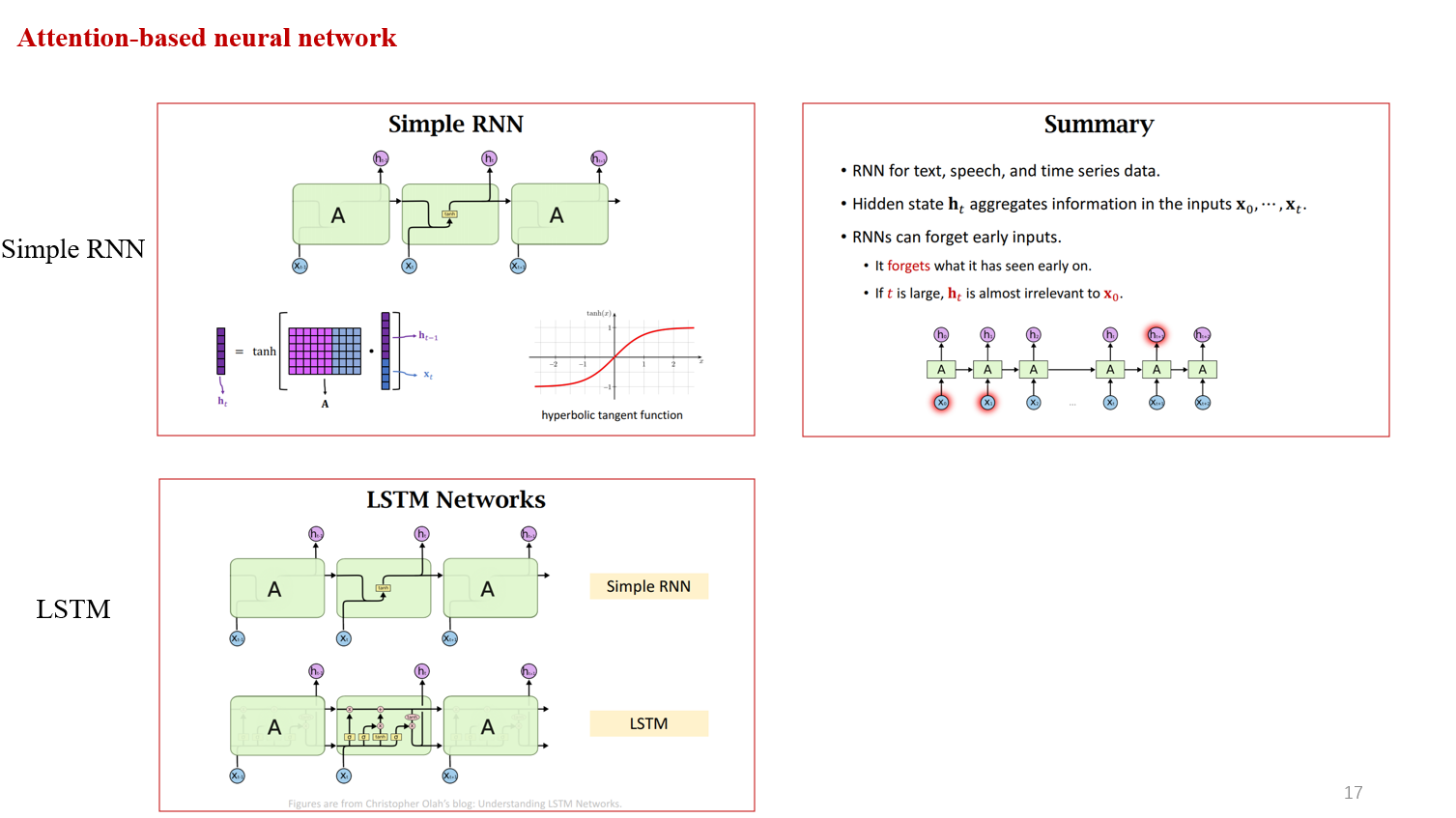
首先,simpleRNN,X是输入,A是一个函数(Neuron),它输出的状态是h。H2的计算是基于H1的状态以及X2的输入,这样进行下去。直到最后输出Hm的结果包含了之前所有的信息。但是RNN存在的一个问题就是当输入的句子或者文本过长,最后的Hm会遗忘之前的结果,即,我们修改了前面的输入,不会影响最终的结果。
那么我们对simpleRNN进行改进,因为RNN会遗忘,所以每一次,我们将初始的X进行处理,输入下一个状态。因此LSTM的效果总是稍好于RNN。
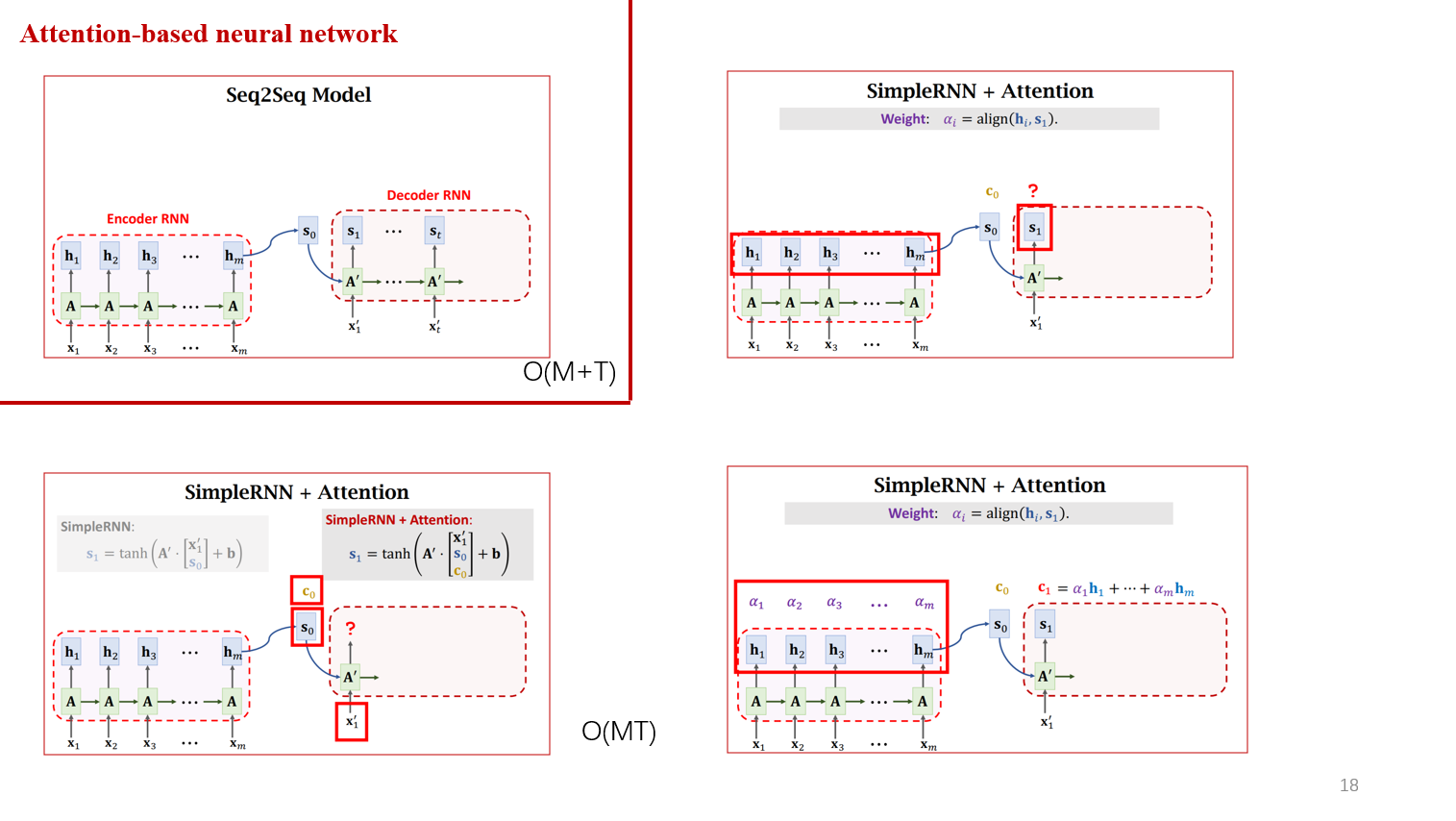
接下来,我们继续优化,刚才提到RNN产生的最后一个状态,作为输入到decoder,会遗忘输入靠前的信息。那么我们在decoder 中加入attention会怎么样呢?
这里,我们初始化C0,S0,结合X1' 作为decoder的输入,得到S1,那么计算S2需要C1怎么计算呢? 这里我们计算了S1与encoder中每一个h的相关性,作为加权平均后计算C1。所以,简单的理解就是attention的每一个结果是直接考虑了所有的原始数据。
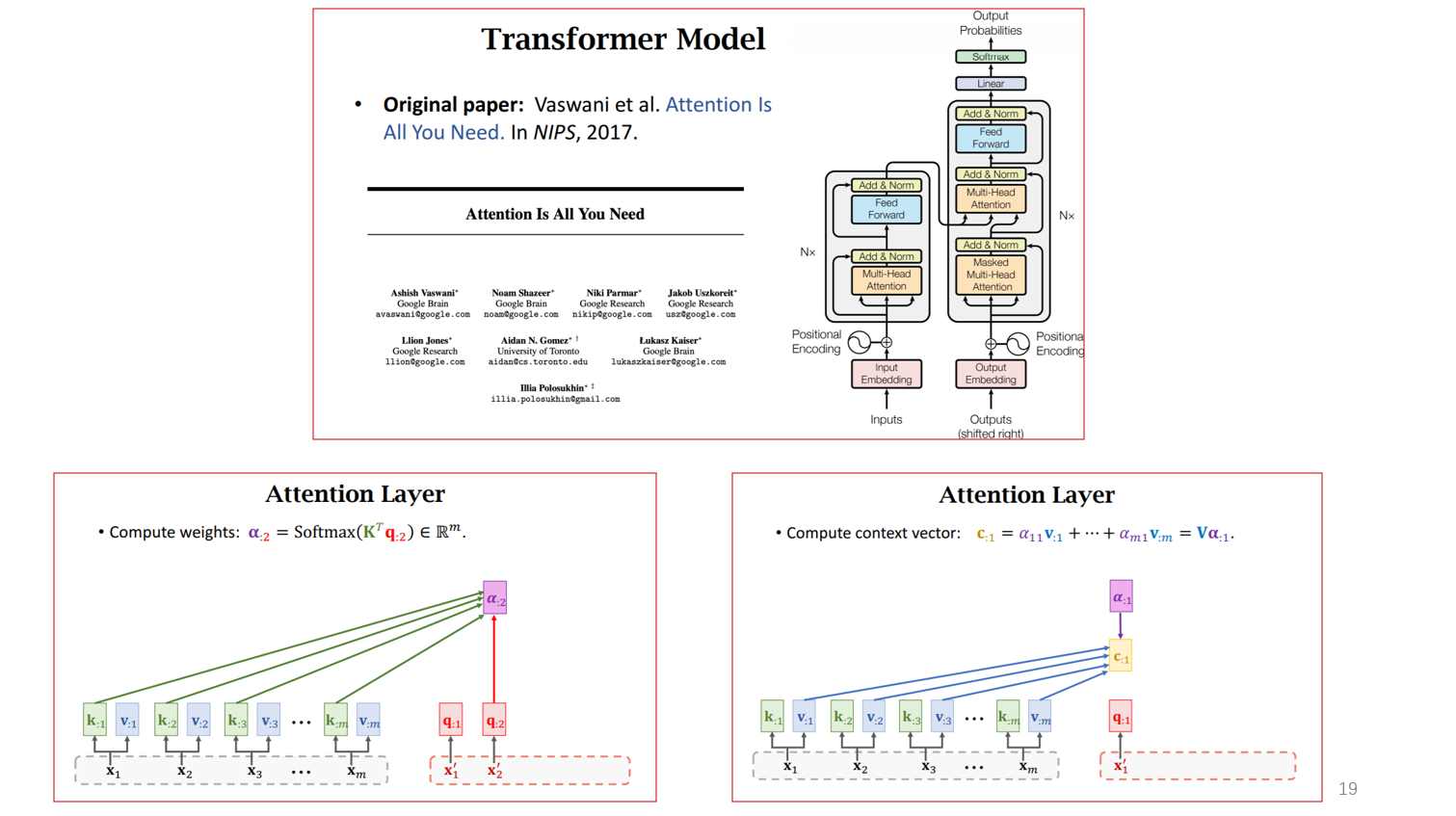
刚才是attention与RNN联合使用,后来在2017年,发现attention可以单独使用。这里简单的理解就是,在encoder的时候,产生了K与V两个参数,一个在计算alpha的时候使用,一个在计算C的时候使用。
完全看不懂
术业有专攻~~
不错
谢谢~