这两天Hive HF24的官方候选版出来啦,简单测试了一下,看看都有哪些变化。

(图源 :pixabay)
编译
首先测试了一下编译,编译过程中我觉得需要注意的就是,如果你之前使用make -j$(nproc) steemd,那么要相应的改成make -j$(nproc) hived其它的包括编译命令行钱包过程都和之前没太大变化,就不再赘述了。
编译会生成hived这个可执行文件,这样好多了,再也不会弄混了。
编译完成看一下版本号:
./hived --version
"version" : { "hive_blockchain_hard_fork" : "1.24.0", "hive_git_revision" : "1aa1b7a44b7402b882326e13ba59f6923336486a" }
直接运行
直接运行hived试试看
hived
除了一些其它信息外,会显示出LOGO以及版本号信息等,chain_id还没有变化(应该是分叉时变化吧)
Reveal spoiler
我们会发现hived在用户目录下创建了.hived隐藏目录,里边包含默认的配置文件等,然后区块自动开始同步。
Reveal spoiler

如果等它自动同步完成,会是一个超级漫长的时间,直接关掉。
从原有blockchain数据运行
将原有的hive 0.23.0的blockchain数据复制到.hived目录下,测试是否可以直接运行。
发现出现如下错误:
Probably database created by a different compiler, build, or operating system.
截图:
Reveal spoiler
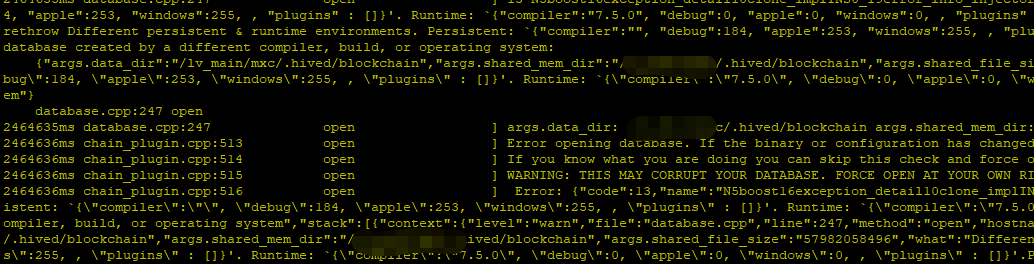
尝试一下使用--force-open,则出现如下图所示错误:
Reveal spoiler
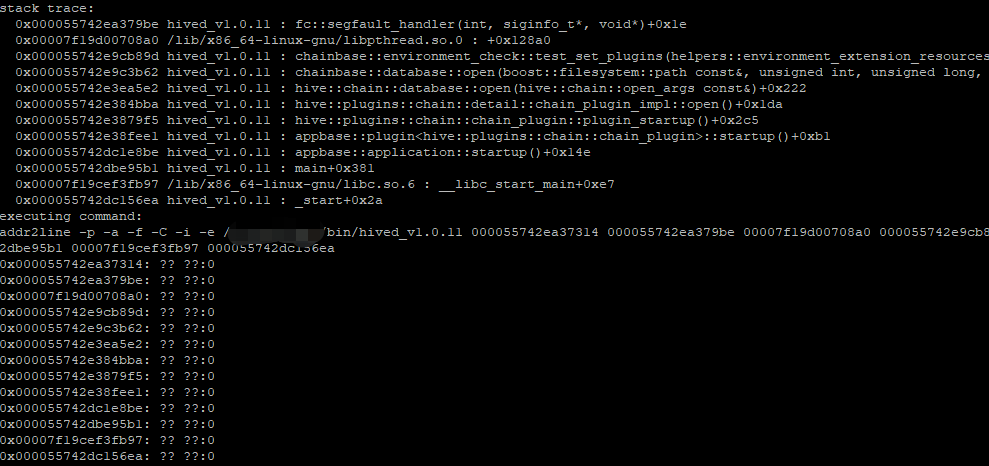
看来想偷懒是不行的啦。
Replay
既然用原来的数据直接运行不行,那就只好Replay了。
直接使用如下指令replay区块,发现出现和直接用原来数据运行一样的错误:
hived --replay-blockchain
使用如下指令删除shared_memory.bin以及block_log.index,再replay,一切正常:
rm -rf shared_memory.bin block_log.index
测试Replay过程重启
分别在Reconstructing Block Log Index以及Replaying blocks过程中用Ctrl+C终止程序,均能正常退出。
退出后重新执行hived --replay-blockchain均能正常接续。
Replay完成大致用时7、8个小时(默认配置、SSD)
同步过程重启
当replay完,在同步到最新块(Syncing Blockchain)的过程中,使用Ctrl+C终止程序,程序正常退出。
执行hived,程序正常接续,一切正常。
测试快照功能
hived有个激动人心的新功能,那就是快照。
我之前测试快照功能死活没找到快照生成到哪里,今天看到@gtg 在聊天里说的需要在配置文件中加上:
plugin = state_snapshot
加上后,在测试一下生成快照:
hived --dump-snapshot test123
发现快照成功的生成了:
Successfully opened db at path: `/xxx/.hived/snapshot/test123/snapshot-manifest'
State snapshot generation. Elapsed time: 37245 ms (real), 84648 ms (cpu). Memory usage: 71527496 (current), 71994160 (peak) kilobytes.
Snapshot generation finished
和我之前想象的快照是一个文件不同,快照是一个文件夹,包含一大堆文件,不过这没啥区别啦:
Reveal spoiler
之后就可以使用快照来启动hived啦:
hived --load-snapshot test123
然后会出现一堆类似如下的信息,等待就好了:
Reveal spoiler
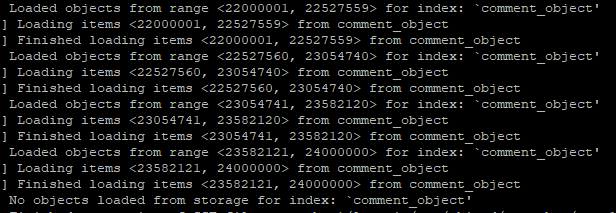
然后等了大概十多分钟后竟然出现如下信息:
Reveal spoiler
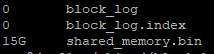
看了一下blockchain目录:
Reveal spoiler
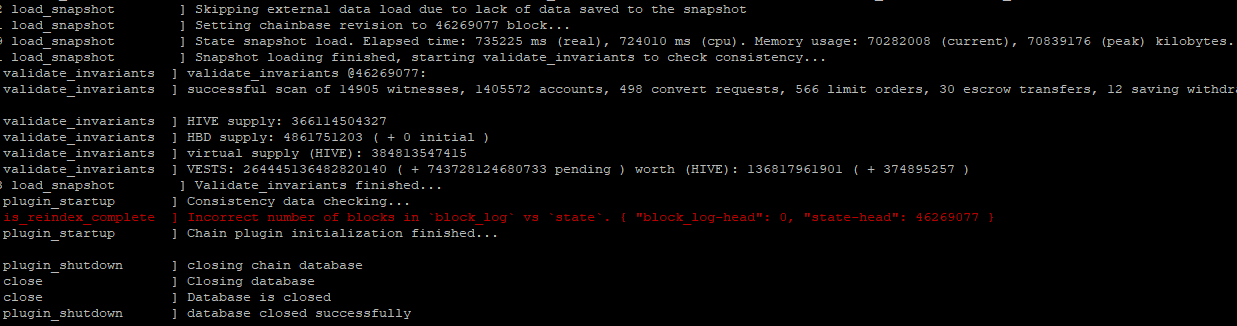
重启hived,出现如下错误:
head_block.valid() && head_block->first.id() == head_block_id(): Chain state does not match block log. Please reindex blockchain.
看来我还是没用明白快照功能,一定是哪里搞错了。😳
其它
一个值得夸赞的地方是,shared_memory.bin 大小缩减到17G(原来要接近60G了),这样的话,运行见证人的机器可以降低一些配置啦,会省下大笔的开销。
另外,早晨看到 @gtg 发了一个hive HF24相关的测试贴,内容很详尽,大家可以参考一下那个。
🤤技术大佬
补充一下:
我还以为hive的快照功能和EOS一样,能直接从快照启动呢,今天试了一下加载失败。
看了一下开发者频道的聊天,才知道还是依赖于block_log,相当于通过快照和block_log回到快照时间点的状态。
尽管不能摆脱对block_log的依赖,但是也避免了类似EOS上没法用get_block啥的获取快照之前的block的问题。
总之,还是相当不错的功能。