我最近这段时间,一直在研究AI数字人和相关的内容。比如wav2lip、so-Vits-svc等,开始安装时,用的是原生态的python环境,安装起来特别麻烦,原因是一般的模型项目,除了安装项目本身之外,还有一大堆相关依赖的组建需要安装,加上这些组建其中还有些相关依赖,而更麻烦的是,因为版本的不统一或要求,其中一些组建总是会产生莫名其妙的冲突,因此这种情况下,弄的我焦头烂额,痛苦不堪。
好在后来友人提醒,可以通过conda内置的python,这样便可以互相不影响,而且还可以在不同的测试环境中自由切换,试了下之后,果然非常nice。
我找了一台安装有显卡A4000显存16G,内存32G的电脑,开始测试,安装了百度的PandlePandle测试了下,训练后的视频效果还不错,但缺点就是,每次训练需要花费一定的时间,这对直播来说,不能做到实时那种,效果自然大打折扣。
前几天的时候,一友人告诉我,说他手上刚拿到别人做好的版本,可以做到实时驱动生成训练后的视频,不需要预生成,而且还可以跟评论区的用户互动。。。
我对此非常感兴趣,我想到他那个跟评论区用户互动,猜测原理应该是先通过程序抓取到评论区内容,然后交由类似GPT这样的AI,输出文字后,再通过比如微软、百度等TTS语音转换。
但是他提到那个不用预生成,是实时驱动的数字人视频,我就有点不太明白。毕竟我自己测试过多次,训练视频是要花费一定的时间,即便是很强的电脑配置,也不太可能做到几乎实时产生视频。。。
我相信对方不会骗我,也没必要骗我,那么问题来了,他们究竟是怎样做到的呢?带着这样的疑惑,我决定去现场观摩一番。
等到去到现场,对方安排了他们的产品经理给我演示。登陆之后,就是个简单的面板,类似stable diffusion webui那种,我一眼就看到了上边的key,很明显就是chatGPT的api key,不言而喻,评论区的互动原理,跟我之前预估的完全一样。
至于他们是怎样做到数字人实时生成的呢?我当时看过后还不太明白,等到晚上回来仔细思考过之后,终于明白了其中的原理。
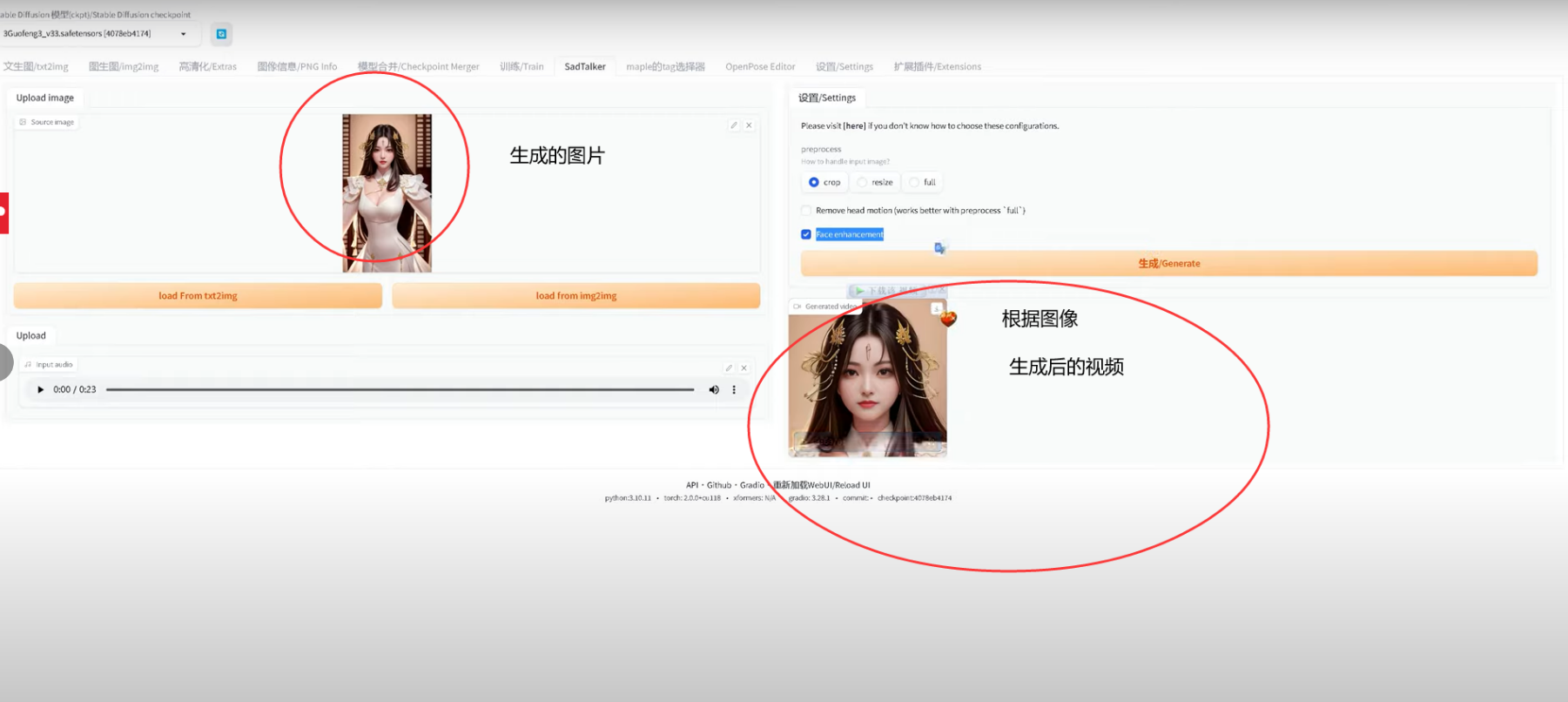
类似如图 stable diffusion webui 这种原理
原来他们压根就不是用像我之前那种办法,视频训练和输出,而是直接使用stable diffusion ,通过大堆堆砌的prompt,先生成一个虚拟的图像人物,然后根据这个人物,结合文字转换后的语音,模拟人物讲话。。。

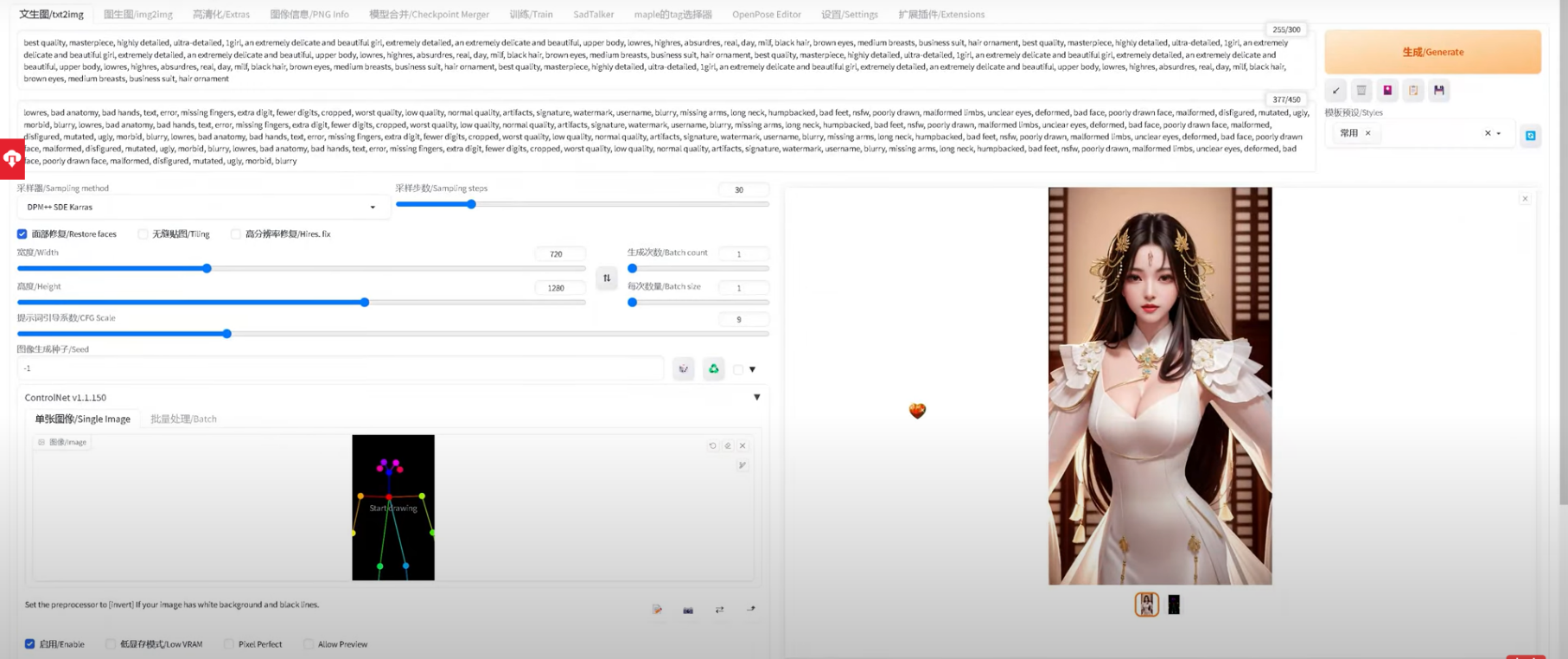
通过大堆prompt 生成后的图像人物
原来他们压根就没搞的像我之前那样负责,而是用了stable diffusion + chatGPT + TTS 这么简单粗暴的办法,直接拿来就用,这样做的好处就是简单、易上手,更重要的是,快速!
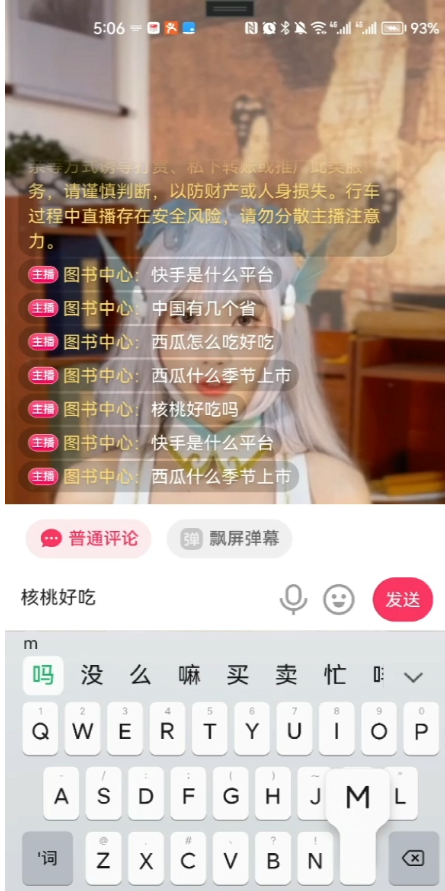
通过OBS接入到某短视频直播平台后的真实效果
想到我们前阵子还在那里一直研究视频训练等,顿感这方面想法落后别人一大截,关键是别人不但敢想,而且还很快付诸行动,这点真是不如人啊!
👍👍
Congratulations @rivalhw! You have completed the following achievement on the Hive blockchain And have been rewarded with New badge(s)
Your next target is to reach 210000 upvotes.
You can view your badges on your board and compare yourself to others in the Ranking
If you no longer want to receive notifications, reply to this comment with the word
STOPCheck out our last posts:
性感😂😂
学习了。