Primero una breve historia
La tecnología de comunicación en internet ha evolucionado al trabajo en paralelo de varios computadores. En la actualidad, con la masividad de acceso a la red, y el volumen de datos trasegados consecuente de ello, es impensable la sostenibilidad de la conexión global sin concebir un grupo de ordenadores trabajando en conjunto. Facebook no posee un super computador (debajo de San Francisco y protegido por efectivos del ejército de USA) que se encarga de atender todos los pedidos de sus usuarios. De hecho, poseen sus servidores distribuidos en varias partes del mundo, y estos consiguen ponerse de acuerdo para parecer ese único supercomputador.

Fuente
Para el usuario final, los datacenter hacen millones de operaciones de un momento a otro, sin que este lo note
Estos servidores necesitan comunicarse de una manera que se pueda escalar (que logren atender pedidos y trasegar información en un orden de crecimiento aceptable), y que sepan reaccionar a los fallos de alguno de ellos. Pensar por ejemplo, en copiar toda la información de una plataforma (Facebook o cualquier otra) en cada servidor, es una solución segura en el sentido de los fallos, pero es impracticable a medida que tu negocio tenga éxito. La curva de crecimiento de trabajo de la plataforma alcanzaría los cielos en cuestión de los cientos de usuarios, cosa que se puede conseguir fácilmente con un emprendimiento hoy en día.
Viene la ingeniería
Aquí es donde juega un papel importante la manera en que estos servidores van a comunicarse. La arquitectura de comunicación de un sistema distribuido, es el conjunto de statements o decisiones que va a tomar cada componente de dicho sistema para lograr funcionar como un todo. En el caso que nos ocupa, a ti que me lees y a mí que escribo, vamos a hablar del Anillo de Chord, una arquitectura que permite el mantenimiento de una tabla de hash repartida entre los nodos de la red. En este post no hablo de aplicaciones concretas de la arquitectura, sino de su implementación en sí.
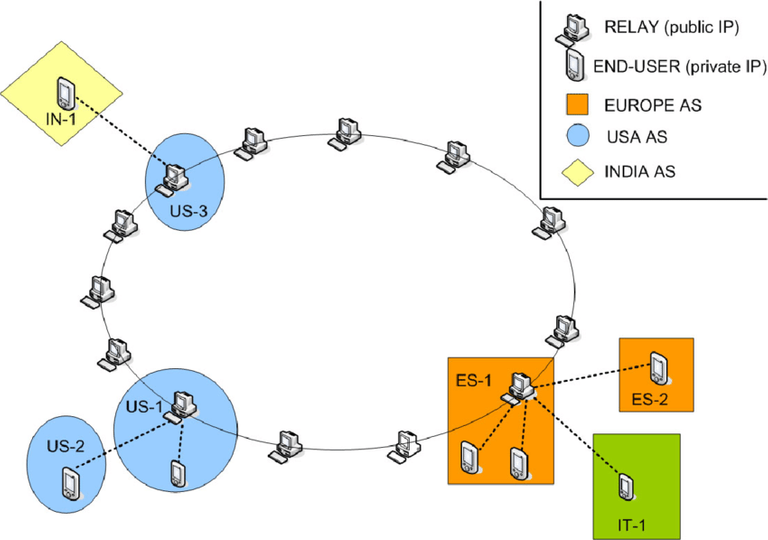 Fuente
Fuente Una representación gráfica del anillo de Chord
Una pequeña nota. A a partir de ahora se hace necesario cierto conocimiento técnico, como algún curso básico de programación, conocimientos de redes y de programación concurrente, saber algo de sistemas operativos o de interfaces de redes a nivel de código, y algo de matemáticas. De todas formas, si sientes que no conoces sobre los temas pero quieres aprender, continúa leyendo y lo que no hayas entendido me lo dejas en los comentarios. No te desanimes si no entiendes o eres nuevo, este no es un tema fácil. Requiere tiempo de procesado.
Una tabla hash (o hash table en la literatura en inglés) es una función matemática, como las que nos enseñan en la escuela, que dado una llave (o un valor del dominio), nos devuelve un valor específico. Podemos decir, por ejemplo, que el conjunto f = 1:2, 3:4 , es una tabla hash, en donde f(1) = 2, y f(3) = 4 (voy a asumir que la notación se sobreentiende). Chord, se encarga de mantener la consistencia de una tabla hash, de forma tal que cuando digamos f(x), obtengamos la y deseada.
Entonces, se definen las componentes de la arquitectura como nodos de la misma, representados por un id, que es un valor del dominio de la tabla de hash. O sea, el id de un nodo, es también una llave a la que le podemos pedir el valor. Adicionalmente, los nodos deben cumplir la condición de soportar la interfaz de red estándar (con IP's y sus añadidos.) Esta es más una especificidad técnica, es la manera de comunicar los nodos.
Para mantener la información estable, la arquitectura, de manera algorítmica, se encarga de sostener una invariante, en todo momento, dada una llave x, se puede conocer su sucesor x', que es el id del nodo más cercano a x. Formalmente, succ(x) = x', si x' es el menor número tal que x < x', y es el id de un nodo de la red. En este punto, la decisión más cómoda, es que el nodo tal que id = x', sea el que posea el valor de f(x). Es de esta forma que se logra la consistencia. Como dije, no hablo de aplicaciones de la arquitectura, así que la naturaleza de qué representa f no es relevante en esta implementación.
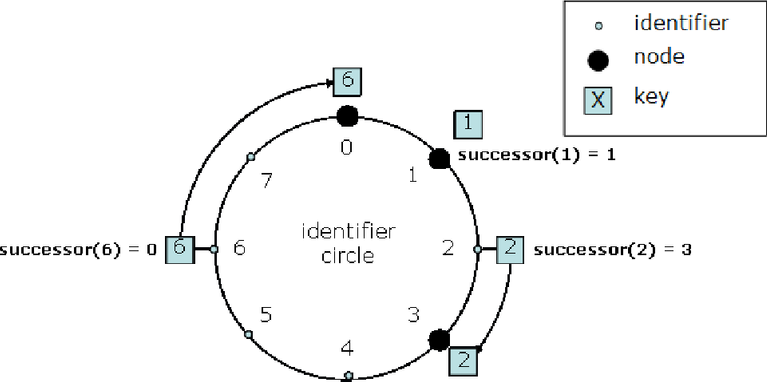
Fuente
Aquí se puede ver que succ(6) = 0
Manos a la obra
La idea es conseguir que la implementación de Chord haga un balance entre la escalabilidad y la tolerancia a fallos. Para esta implementación, la cual pueden buscar en github, usé los siguientes softwares:
- python3.7. El lenguaje de programación que usé.
- pyzmq16.0.3. La biblioteca para emitir mensajes. Es el acrónimo de Zero Message Queuer. Si quieres saber más de ella busca aquí
- ubuntu18.04 El sistema operativo
- Docker, una herramienta que permite crear y administrar contenedores (Hablaré de contenedores en otro tutorial. Específicamente algo sobre blockchain.)
La estructura de los mensajes
Usando la API de zmq, podemos hacer que los mensajes viajen de un nodo a otro en forma de JSON, una notación que se ha estandarizado mucho en el mundo informático y que resulta muy cómoda.
Un nodo necesita escuchar pedidos de otros nodos, responder a los mismos, y viceversa: hacer pedidos y que le respondan. Esto define dos tipos de mensajes, los de pedido o request, y los de respuesta o replier. Todos los mensajes de tipo request esperan una respuesta, pues como su nombre lo indica, se trata de mensajes hechos de un nodo A a un nodo B, porque A necesita saber algo de B.
En consecuencia, B emite un replier con la información de la solicitud. En caso de que B no responda, A insistirá un número de veces x hasta que considere a B como un nodo muerto. En el caso de los request existe la clase request dentro de utils.py, que sirve para encapsular las instrucciones asociadas a enviar el mensaje varias veces. Como en el caso de un replier, solo se envía el mensaje sin ninguna otra consecuencia, no lo consideré necesario.
Otro tema del que hablar es de la estructura de los JSON's que envío. Estos no están atados a unas llaves fijas, pero si deben tener un conjunto mínimo de llaves. En el caso de los replier pongo las llaves response y return_info, y en el caso de los request, uso command_name y method_params. Como dije, ambos tipos de mensajes pueden tener más llaves, pero éstas deben aparecer.
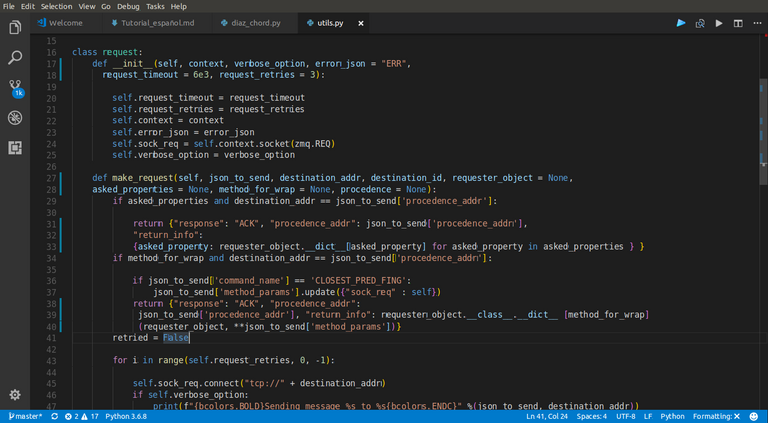 |
|---|
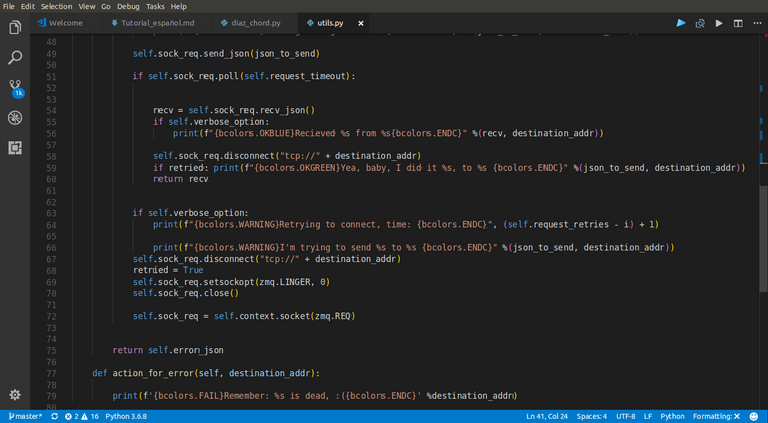 |
| Aquí puede verse la clase request, usando la API de zmq para hacer pedidos que duren un tiempo dado, y en caso de no respuesta, considerarlo un fallo |
La clase Node
Dentro del archivo diaz_chord.py está el código que se activa dentro de cada nodo de la red. Me referiré indistintamente a la clase nodo como un nodo simplemente, aunque en este caso se trate de solo código. Aquí están las instrucciones principales para que la arquitectura funcione. Para entendernos, es bueno aclarar qué necesita hacer un nodo. "La necesidad es la madre de la invención", recuerda Eric S. Raymond en su libro La catedral y el bazar. Pero para poder entender qué hace falta, hay que usar un enfoque eficiente. Mi propuesta es ir de lo más simple a lo complejo (o al menos intentarlo, hay un momento en que las cosas se ponen circulares y no hay forma de escapar de esa circularidad.)
La red más simple que se puede tener, y que no nos sirve para nada, es de un solo nodo.
De hecho, la idea de iniciar la red con un solo nodo no es compleja, pero posee ciertas limitantes teóricas. El artículo que presenta a Chord, afirma un conjunto de invariantes que se deben mantener para que la propiedad de Chord (aquella del sucesor que antes mencioné) no se pierda, mas no hace la salvedad de que en el caso de una red con un solo nodo, si hay sucesivos fallos y uniones de nodos al anillo, la red corre el riesgo de no funcionar bien. Lo diré sin muchas complicaciones, y parafraseando a quienes hicieron la teoría al respecto: si cada nodo tiene una lista con los k sucesivos sucesores en la red, necesitas k+1 nodos inicialmente conectados a la red de forma exitosa al menos en la red, para garantizar que Chord siga funcionando bien a pesar de fallos. En algún momento volveré en otro post sobre esa teoría. Ese sí que va a ser denso. Nuestros nodos tienen 3 sucesores consecutivos en la red. Si alguien usa el código, deberá tener cuidado de que no hayan fallos hasta que al menos 4 nodos estén en la red.
Volviendo a las simplezas. Nos habíamos quedado en un nodo inicial.
El __init__ para un nodo inicial
 |
|---|
| Aquí puede verse todo lo que necesita un nodo, sea el primero o no de la red |
Lo más raro que se puede ver en esa foto son las líneas 21-23, pero esto, más que nada, es construyendo el id que va a tener el nodo a partir de una regla (verán que dice hash, pero no tiene que ver con la tabla de hash que mantiene Chord.) En la línea 25 se guarda el id a partir de esa regla. Lo otro es el contexto que define zmq (a partir del cual se crean los sockets, que son unos descriptores de fichero especiales, que se usan para escribir y leer cosas en la red), la succ_list de cada nodo, de tamaño 3, y otras propiedades que tendrán razón de ser en cálculos posteriores.
El client_requester declarado en la línea 41, es de tipo request, que engloba la estructura de mensaje que antes explicamos.
Las líneas 34-37, asignan a cada string, que representan todos los comandos que se pueden transmitir de un lugar a otro.
Y bueno, como el nodo es introductorio, se le puede mandar directamente a esperar un comando.
La función waiting_for_command()
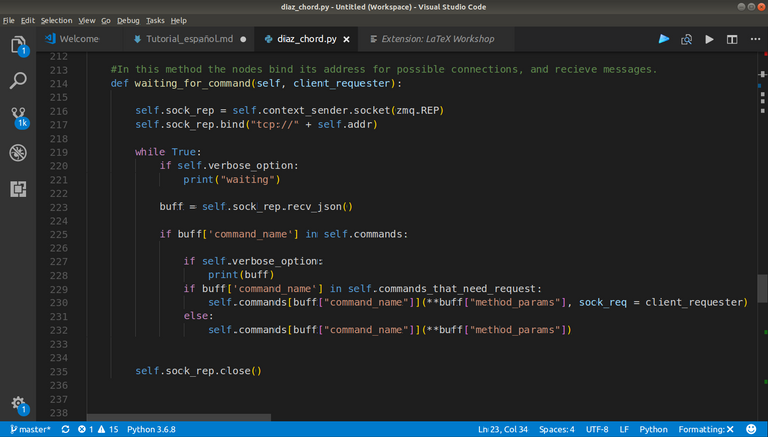 |
|---|
La función waiting_for_command() dentro del nodo, se encarga recibir cualquier request que se le haga al mismo y enviar respuesta |
En la foto, se puede ver en la línea 216 cómo se crea un socket de tipo replier usando zmq. Este socket puede enlazarse a una dirección IP disponible en el sistema que representa al nodo, tal como se muestra en la línea 217. Esta es una manera de habilitar un espacio de memoria en ejecución para que se escriban datos dentro de él a través de la red. Mientras el nodo viva, va a estar esperando una respuesta de otros nodos, es por ello el while True. La línea más interesante que queda, a mi entender, es la 223, y es porque la misma bloquea la ejecución del hilo del programa (volveremos ahí más tarde), pare recibir el JSON que tiene la información del mensaje. Luego se ejecuta la función en dependencia de lo que haya en buff['command_name'], lo que esta diga dentro del diccionario self.commands.
El __init__ para un nodo que hace join
Si un nodo ya no es inicial, necesita para poder entrar a la red, el IP de un nodo, de esta forma puede hacer un request a dicho IP, y obtener quién es su predecesor y "ubicarse delante de él". Nuevamente hay que recordar la invariante que se quiere mantener.
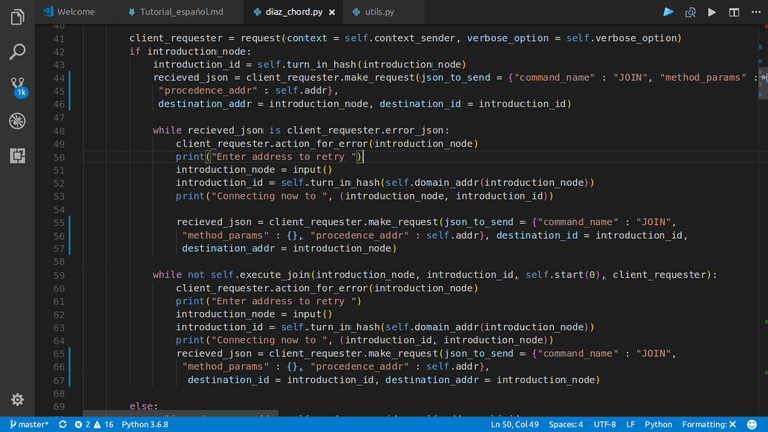 |
|---|
| Si algún request falla, se le pide al usuario que vuelva a entrar otro IP |
|:--:|
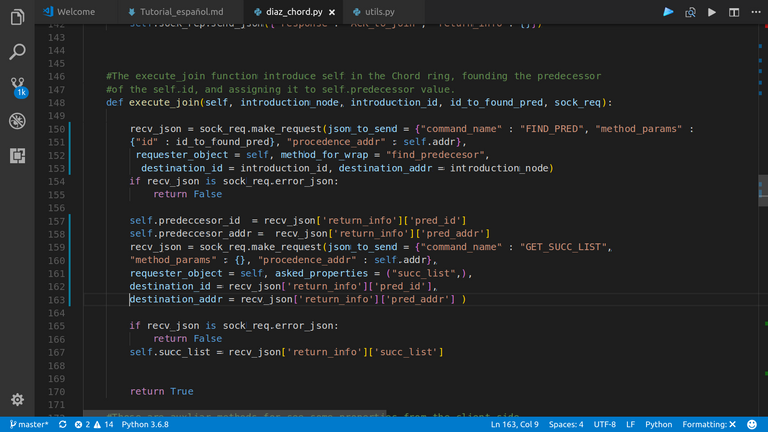 |
|---|
| Este es el método mediante el cual el nodo nuevo se inserta en la red. Busca su predecesor según su id, y guarda ese valor. Asimismo almacena la succ_list de su predecesor como suya. |
| :--: |
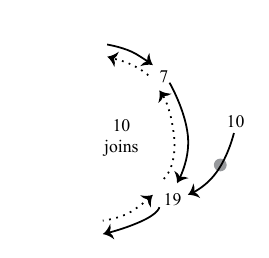 |
| :--: |
| El nodo 10 en esta foto, ha ejecutado el método anterior. |
La red estabilizándose
Luego de hacer join exitosamente, el nuevo nodo aún no pertenece a la red. Para que esto ocurra debe ejecutar stabilize, que es el acto de notificar a su sucesor vivo más próximo de su existencia, y verificar que el valor que él posee de predecesor esté más cercano a él que el nodo que ejecuta stabilize. En ese caso, la succ_list del nodo realiza la operación de las líneas 119-120. En la instancia contraria, el nodo asume que su nueva lista de sucesores tiene a su sucesor, junto con la succ_list del mismo sin considerar su último elemento.
 |
|---|
El código del stabilize |
Aquí ocurre algo que me parece con creces atractivo: el único acto no pasivo que se toma en todo el código frente a la caída de un nodo, está en las líneas 96-97. Uno podría pensar que como se hacen request en múltiples partes del código, entonces lo correcto es tomar una decisión frente a una posible caida del requestado, más allá de no hacer nada. Eso solo lleva las cosas a un punto de complicación innecesario. Si estamos buscando el sucesor de una llave x, y en esa búsqueda se cae algún nodo al que se le pide información, entonces esperemos: stabilize se va a ejecutar periódicamente en cada nodo, por lo que en algún momento succ(x) va a tener un valor que va a coincidir con el que se desea, porque teóricamente la red se encuentra en un estado donde mantiene la invariante. Es el principio KISS gritándote a la cara (Keep It Simple Stupid!!).
Independiente de si se pudo o no estabilizar el nodo a partir de su sucesor, este envía un request pidiendo a su sucesor que rectifique si el nodo es su predecesor.
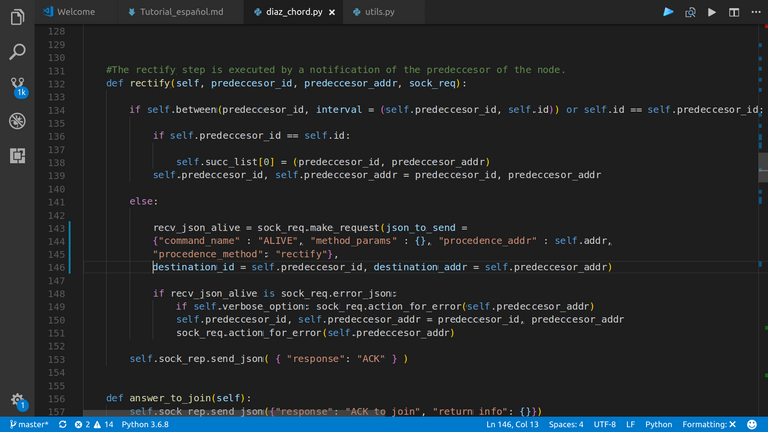 |
|---|
El código de rectify se ejecuta en el nodo requestado |
La parte concurrente
Como antes dije, el código de stabilize se va a estar ejecutando periódicamente, cada vez que transcurra una unidad de tiempo guardada en self.waiting_time. Por otra parte, recordemos que el nodo necesita esperar comandos si no está atendiendo ninguno. Una solución, para evitar posibles conflictos sobre disponibilidad, es usar un hilo diferente para cada función. De esta forma tenemos dos funciones ejecutándose en paralelo dentro de un nodo dado.
 |
|---|
| El método wrapper_action, que se ejecuta al final del __init__, y el wrapper_loop_stabilize, que hace lo que hemos explicado. |
La razón de ser de Chord, buscar un sucesor de una llave
Una estrategia cómoda y limpia para buscar el sucesor de un x dado dentro de la red es buscar el predecesor de dicha x, y luego devolver su sucesor, que es el mismo de x. Pensemos en dos nodos A y B en el anillo, tal que succ(A) = B. Estos definen un intervalo. Por tanto, si x se encuentra entre ellos, succ(x) = B. Siguiendo este pensamiento, tenemos el código siguiente:

find_succesor |
|---|
Y bueno, el find_predecessor:
|:--:|
 |
|---|
find_predecessor. El finger_table que ahí se muestra, es una optimización para hacer la búsqueda de un id, en vez de en orden lineal, visitando todos los nodos, en orden logarítmico. |
Aquí, queda ilustrar el método que se encarga de buscar el "dedo" más cercano a partir de la finger_table:
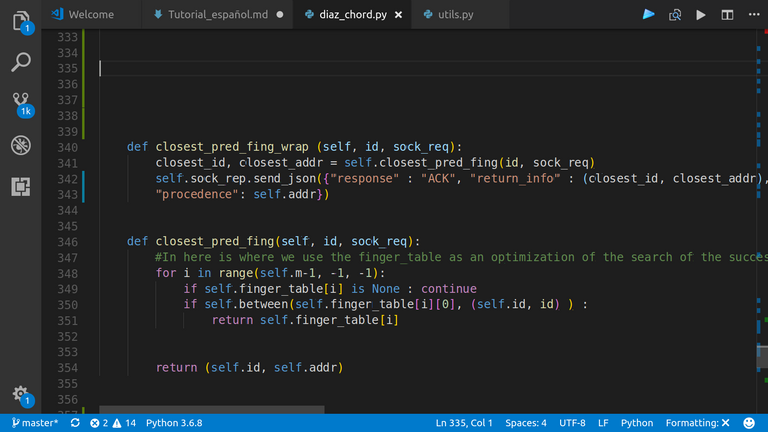 |
|---|
closest_preceding_finger |
El pequeño cliente para hacer request
En client.py hay escrito un cliente que se conecta a la dirección IP que se le diga,
y hace algunas solicitudes que pueden ser respondidas por un nodo. Pueden ver el código
fuente en el repo de github.
¿Cómo correr la red y verla funcionar?
Yo sé que con lo que he mostrado, quien me lee se debe encontrar ávido de conocimientos si ha llegado hasta aquí, (si has llegado hasta aquí pasando por todo lo demás, quiero creer eso), y que la pregunta ahora que te haces es "¿Cómo corre este Chord?", "¿Cómo se despliega?", y yo como soy un buen vendedor de productos y de historias, te digo que en la próxima lo veremos. Hablaré algo de las últimas líneas del código,y de cómo usar docker para correr el sistema.
Conclusiones
Un sistema distribuido es sumamente difícil de testear, tanto por la naturaleza del problema que resuelve, como por la forma en que lo hace. El código que he mostrado, posee ciertas redundancias innecesarias, partes que no tienen razón de ser (no tantas, vamos a estar claro). En fin, que se puede mejorar. Pero funciona. Funciona para varias instancias que he probado. Hablaré de ello luego. Si puedes darme algún feedback, utilizarlo siguiendo las reglas que dejé en github, o dejando algún comentario, sería de gran ayuda.
Un contenido espectacular!!!
Nos leemos! Brillante @diazrock!!!
Muchas gracias @avellana. Subiré más cosas por el estilo. Algunas más ligeras :)
Excelente guía para el trabajo con sistemas distribuidos, ojalá steemit tuviera más contenidos como este. Técnico, preciso e introductorio.
Gracias, el equipo de CubanBlock mostrará otras cosas de programación más adelante.
Congratulations @diazrock! You have completed the following achievement on the Steem blockchain and have been rewarded with new badge(s) :
You can view your badges on your Steem Board and compare to others on the Steem Ranking
If you no longer want to receive notifications, reply to this comment with the word
STOPTo support your work, I also upvoted your post!
Vote for @Steemitboard as a witness to get one more award and increased upvotes!