Some of you might have heard that RC will become part of consensus some time in the future. The plan is to make all necessary changes first, then leave it with no changes for one whole hardfork, to make sure all nodes are "on the same page". Only then make a single line change to turn warning into hard assertion making the whole mechanism part of consensus.
I'd actually prefer to speed it up, since RC consensus is a direct or indirect prerequisite to many must-have features. So if all top witnesses switch to upcoming v1.27.5, maybe we can make it even for HF28.
While RC was always required to broadcast transactions/blocks and to run a witness, it was (and still is) possible for it to be modified, so nodes with different code versions see state of RC differently and the differences are even retroactive (new code computes different RC state not just for new transactions, but for old ones too). Historically those differences were big and frequent, due to rapid changes after HF20 when RC was introduced as a replacement for bandwidth mechanism. Later there were still bugs that could cause disagreements between nodes even on the same code version. The bugs were fixed for HF26. But the fact that RC is still not part of consensus is actually pretty convenient from development standpoint since only one version of the code has to be kept. As a result there are differences between minor versions of current HF27 nodes. Such differences can cause warnings in node logs similar to this one:
Accepting transaction by notaboat, has 31621211 RC, needs 916378051 RC, block 69392132, witness r0nd0n.
It means there was a block (69392132) containing transaction that the node thinks was incorrectly allowed (by r0nd0n) because payer account (notaboat) did not have enough RC mana - the node notes its protest in its own log, but accepts the block with such transaction.
As an example of recent differences, hived version 1.27.4 differs from previous versions in such a way that it does not put RC mana into negative. Previously in case the node was forced to accept transaction it thought was RC-incorrect, it would allow payer's RC to dip into negative for up to 2 hours worth of regeneration (if the hole was bigger, it would still only put negative 2 hours). The change in 1.27.4 puts the limit at zero (if anyone used more RC mana than they have and such transaction was somehow included in block, their RC mana is set to 0 instead of going negative). It was a step in right direction because, after RC becomes consensus, it will be impossible to ever use more mana than user has, making zero the absolute bottom. But such difference also means that 1.27.4 nodes might think affected users have more mana in comparison to what older nodes think.

I'm slowly making changes towards the final goal of RC becoming consensus. In current version of develop RC is no longer a plugin, its code was moved to main code, but for safety reasons it is still temporarily isolated as if it was still a plugin (that is, exception from RC code will be stopped on the barrier and won't propagate further causing whole block to fail). I'm currently in the process of removing that isolation, starting with handling of virtual operations. After I've finished the batch of changes, I've run full replay to see if everything was still ok.
One new "Accepting ..." warning showed up that I've not seen before. It was from fairly fresh block, so I didn't have it in the pattern because the pattern stopped earlier. I'd probably ignore it if it was from some witness running old version, but it was blocktrades that allowed RC-incorrect transaction:
Accepting transaction by pocketjs, has 91720737 RC, needs 91767026 RC, block 79129983, witness blocktrades.
Unexpected difference
To find the possible problem with my changes I've run whole replay again (twice) with full logging for pocketjs. I thought the problem will show close to the block mentioned in the "Accepting ..." message, but the differences started very early:
- old
{"payer":"pocketjs","usage":[1182,0,0,4245248,166965],"cost":[499619042,0,0,1519011622,38465384],"max":"182243363280","rc":"161409039261","op":1} - new
{"payer":"pocketjs","usage":[1182,0,0,4245248,166965],"cost":[499619042,0,0,1519011622,38465384],"max":"182243363280","rc":"161409039262","op":1}
A difference of one seems like insignificant, but there should be none... Of course I just had to forget to add block number to the message, but the log also contained performance report, so I found that it was third comment ("op":1) made by pocketjs after block 36547200. And immediately before that it received an upvote and a curation.
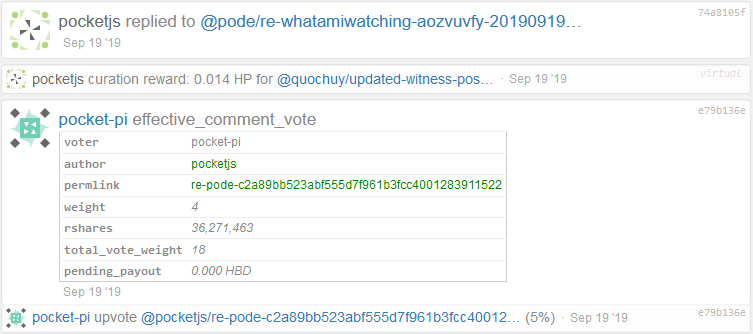
Hm... received upvotes don't influence RC, neither do curations...
💡Aha! Curations don't change RC, but they did! When in testnet configuration RC could start at any block, it had to handle all operations that could influence vests. Once the code was changed, so testnet also starts RC with HF20 like mainnet, a lot of virtual operations no longer needed to be handled by RC code. That included curation related vops. Up to HF17 comment related rewards were stored directly on user main balances, but since then they were moved to separate reward balance, which has to be explicitly claimed. Since HF17 is before HF20, RC code no longer needed to look at those vops, so it no longer does.
Ok, but how do those changes affect mainnet that always activated RC on HF20? Let's see what the change was about:
https://gitlab.syncad.com/hive/hive/-/commit/db338d32f8c401d25103ed38fd703056bcea5f9c
As you can see from the commit message, the change around curation related vop isn't even main topic of the commit. It was just done on the fly, since main change affected the code in similar fashion. The code is the same for every operation that can update vests. First the RC mana is regenerated using old parameters (amount of vests and therefore max mana) up to the point of operation execution. It is called in "pre apply operation" signal handler. Once operation updates vests, RC parameters are recalculated, so next time regeneration happens, it will use updated values. Update is called in "post apply operation" signal handler.
Surely removing regeneration of RC mana when parameters don't change and no-op update of parameters can't change anything, right?
Unfortunately not true. While update of parameters truly didn't do anything (computed exactly the same values as were already in the state), mana regeneration is not entirely neutral. It is done by calculating fraction of "time of full regeneration" that had actually passed since last regeneration and multiplied by power of that regeneration (max mana). The calculations are done on large integers, which means final division actually truncates resulting value if it does not divide perfectly. This means that the more regeneration cycles are performed, the less there might be on final mana. F.e. if we have max = 12 and start at zero, single regeneration after 5 days will set the value to 12, however if we do superfluous regenerations before that, after 2 and 4 days, we'll get 0 + (12*2)/5 = 4 and 4 + (12*2)/5 = 8, with final 8 + (12*1)/5 = 10 (the real values of RC mana are in billions on average and time is expressed in seconds and not whole days, but the principle is the same).
So, that innocent looking change influenced RC mana, case closed.
Wait a minute. Didn't you just show that new version will see more RC mana on the same account compared to old version? It doesn't at all fit situation with
blocktradesthat is running 1.27.4 - older than 1.27.5+ that is indevelop.
Ok, ok, you got me. We need to investigate further.
I've seen that already...
Every time pocketjs reached either zero or full mana the tiny differences caused by above problem would reset, so half of the old-vs-new logs actually matched.
The exact moment when the new "Accepting ..." message shows up is with the following difference:
- old:
{"payer":"pocketjs","usage":[127,0,0,24320,119099],"cost":[63697579,0,0,3877090,24192357],"max":42228130976,"rc":15168,"op":0} - new:
{"payer":"pocketjs","usage":[127,0,0,24320,119099],"cost":[63697579,0,0,3877090,24192357],"max":42228130976,"rc":0,"op":0}
So, everything is the same except for the mana, but the difference is much bigger and new code showed less mana than old code. Since it bottomed mana at zero, let's see difference on previous operation:
- old:
{"payer":"pocketjs","usage":[130,0,0,24320,119099],"cost":[65227475,0,0,3874565,24200940],"max":42228130976,"rc":44862049,"op":0} - new:
{"payer":"pocketjs","usage":[130,0,0,24320,119099],"cost":[65227475,0,0,3874565,24200940],"max":42228130976,"rc":44800592,"op":0}
A big, 61457 difference (well, maybe not that big for RC value, but enough to cause problem). The difference is in the middle of a very long sequence of differences starting as early as block 68428800 - over 10M blocks before the problem exposed itself. The first difference in the sequence is the following:
- old:
{"payer":"pocketjs","usage":[131,0,0,24320,119099],"cost":[146631188,0,0,2690242,26789722],"max":42228130976,"rc":0,"op":0} - new:
{"payer":"pocketjs","usage":[131,0,0,24320,119099],"cost":[146631444,0,0,2690213,26789728],"max":42228130976,"rc":0,"op":0}
But what is it? 🤔 There are differences in resource costs...
And then I remembered, that I've actually investigated such difference before and even made new pattern for "RC stats". The difference in costs was caused by the following change:
https://gitlab.syncad.com/hive/hive/-/commit/1516893ebe56f7773e22bd12d7fb3c190e7c8ffd
Among other changes calculation of extra cost (above cost of custom_json_operation) associated with execution of RC delegation was moved from signal handler to the evaluator. The change put it after check (see line 34) on activation of the feature at HF26. It made no difference for valid RC delegations, but changed cost of those that were ignored (posted too early), namely eliminated extra cost for them (after all they were not executed).
The influence of that change was not straightforward. It shifted popularity share of resources. The change eliminated consumption of some resources, which made them less popular (therefore less costly), but that also means other resources became relatively more popular increasing their cost. The influence is not permanent. Over time its significance diminished and the old and new values would converge after several million blocks, but before that the differences in transaction costs easily reached the values observed in this case. When the differences in costs finally stopped affecting pocketjs, the difference in RC mana was at the level only slightly more than when the problem occurred. If the user burned all mana or let it regenerate, the difference would reset, but it is not unusual for accounts to fly between both extremes for extended periods of time.
And that concludes the investigation on extra "Accepting ..." message. But there is more to the story.
RC stamps
During time leading to HF24, when the whole team was doing many optimizations while learning the code, the most common problem we've encountered was the replay failing on claim_reward_balance_operation. That time I wondered why the operation is so wasteful. After all it requires user to tell how much of each of reward balances they want to claim. And the wallets pretty much always put whole reward balances there. Wouldn't it be cheaper if the operation just claimed everything there is to claim? I don't know if it was made this way on purpose, but in the light of the problems we had with that operation, the way it works is a blessing. It protected us from so many subtle bugs, I can't even count. The thing is, whenever someone made a change that even slightly, by a single point, changed amount of vests a user had or how much was in reward pool, or a global price, or inflation, or the way rewards are calculated, then after a week or a month, or even longer time, but surely and inevitably some claim_reward_balance_operation would blow up during replay. Super annoying, because once that happened, it marked a start of painstaking investigation consisting of multiple replays with extra logging to find the source of unwanted change. Annoying, but incredibly useful.
I wanted something with similar effect but for RC. After all, once RC becomes part of consensus, differences in RC levels might lead to forks, so it will be too late to learn that some change caused nodes to diverge million blocks before the failure. Previously I thought that daily reports in RC stats will provide enough data to detect such issues, but the problem described above (the first one) showed that even if all parameters, resource usage values and costs are the same, there are still some changes that might slip through unnoticed. That's why I've decided to compute a rolling hash made of RC mana values of payers taken after the transaction (a stamp of RC mana state) and add it to daily reports. The addition is here:
https://gitlab.syncad.com/hive/hive/-/commit/fb359bbfcc13b2201636fe260a7ed0d7d3fb172d
Once the new RC stamp was included in develop I've rebased my branch and decided to run replay again. Just a formality. After all the investigation found the source of the problem and new RC reality was accepted.
And then it broke...
The next day I've checked results and first couple daily reports were the same. But after that nearly all reports differed in stamps... 😱
😢 At least I know the new RC stamps mechanism is working as intended. 😢
Time for yet more replays. 😞 This time with full RC logging, but only up to 28M, ~1.5M of RC activity. Even before I got the results (10GB extra log from each run 😨 have fun comparing that), I knew what happened (it is sometimes good to get some sleep). The difference is of the same kind as the first problem, but a bit more subtle. Here it is:
https://gitlab.syncad.com/hive/hive/-/commit/229621a42c17864af29445e22dce97a424ddc72c
Previously RC regeneration always happened when fill_vesting_withdraw_operation was encountered. That is because visitor code inside signal handling didn't have easy access to information if that regeneration was actually needed. However once the code was moved to where the action happens, it is natural to only perform regeneration when it is necessary, that is, when vests are being changed. The change affects accounts that were targets of vesting route with liquid Hive on its end. They would previously had their RC mana needlessly regenerated, which does not happen after the change.
Three full replays later I could confirm that was the last source of differences:
- on version right before the change - result was exactly like previous pattern, showing that changes prior to the identified one didn't change RC stamps
- on version with only the selected change - new pattern
- on version with all changes from the merge request - result was exactly like new pattern, showing no further commits caused additional changes in RC stamps
The two good things that resulted from all the above was:
- implementation of RC stamps - it proved its usefulness already
- I was able to catch up with requests for code review while waiting for replays to finish 😉
If Arthur C. Clarke was a Hive developer... ;-)
Thanks for the write-up, it is very interesting to find out what the core development looks like and what challenges there are. A very tricky indeed, this one was.
Do you think modularity can help reduce this fragility?
You'd need to expand on what you mean by modularity.
There are many things left to be done that could help prevent making mistakes and/or make it easier to detect and diagnose issues.
hivedcode.assetcan be replaced with strongly typedtiny_asset<>(f.e.HIVE_asset), which makes compiler protect you from accidental mixing of assets. Such changes are usually done on the fly, when particular code is being modified anyway.Overall I mean the separation of concerns/functionalities into their own compartments, so that they do their thing internally (in an ideal case, of course). As you know, in this way interactions between modules that can lead to all sorts of unpredicted behaviors are vastly reduced. As far as I understood, you were describing debugging a situation where one concern (RC costs) was being influenced and was influencing other concerns, in various subtle loops. The logic of such interactions gets very complicated and can be extremely hard to debug, and obviously leads to fragility where you make a change somewhere and completely unexpected changes pop up somewhere else.
Would it make a difference if the RC code does its thing internally and returns back its results to the main program? I don't know how feasible that would be either. But simple straightforward logic seems far better than subtle and complicated. Obviously refactoring involves a kind of reconceptualization where numerous little things are organized into robust concepts with clear flow of information.
No no, this one is "all stays within family" type of case. RC code was moved from one place to another and cleaned up. The key point is that if you look at the changes, it "is obvious" they should not influence anything, yet they unexpectedly do. It shows that changing blockchain code is a bit like walking on a minefield. It is also an introduction to the power of new RC stamps mechanism that right after its inception caught such subtle influence that would otherwise most likely never be detected.
I have similar story about ongoing bug with power down (its fix will activate with HF28), or already fixed in
v1.27.5, but with wild workaround, problem of strange values on some accounts' properties detected during testing of Balance Tracker app. I might describe them in future articles, since it could be useful case study for people wanting to try their skills on consensus code.Congratulations @andablackwidow! You have completed the following achievement on the Hive blockchain And have been rewarded with New badge(s)
Your next target is to reach 4000 upvotes.
You can view your badges on your board and compare yourself to others in the Ranking
If you no longer want to receive notifications, reply to this comment with the word
STOPCheck out our last posts: