Whenever I do a new setup and learn something new, it is my practice to write a guide and keep it as my reference. Recently I had to migrate my witness from one server to another server. This article is going to be a guide for setting up a Hive node from scratch. I know some people would say Docker is convenient but I don't use Docker much so I wanted to do the setup without the help of Docker. This guide will provide you with step-by-step details to do the setup and finally, it will have information about the errors I came across during the setup and what would be the reason and resolution for the same.
Before I start the guide, I have to definitely credit two guides that I used for my reference. With these guides, it was definitely a smooth ride. I didn't have any bigger challenges. The first guidesecond guide was from @mahadiyari and the was more recent by @themarkymark. Thank you so much for taking the time to write the guide.

Step 1: Getting the server specs ready
Getting the server is the first prerequisite. I'm using Ubuntu 22.04.1 LTS as my operating system in this guide. I would recommend using the same and not going with any version older than this. Maybe Ubuntu 20 is also okay but older than that is not recommended.
1 TB SSD
32 GB RAM
4 Cores
In my case, I used an even more powerful dedicated server for doing the setup. But from what I understand the above specifications should be sufficient for now. Please also note that based on the blockchain data and based on the plugins you had enabled, the storage data might differ. Additionally, we have to also understand that based on the blockchain growth the storage requirements will also go up.
Step 2: Initial server setup
When I usually get a new server, I do the following first to make sure the server is up to date with the basic utilities.
sudo apt-get update -y
sudo apt-get upgrade -y
sudo apt install git -y
sudo apt install ufw -y
sudo apt-get install fail2ban -y
You can google each one of them to know more about what it does. I personally find it important for my servers. In addition to the above below are some of the dependencies that are necessary for running a hived instance.
apt-get install -y \
autoconf \
automake \
autotools-dev \
build-essential \
cmake \
make \
g++ \
doxygen \
pkg-config \
libboost-all-dev \
libyajl-dev \
libreadline-dev \
libsnappy-dev \
libssl-dev \
libtool \
liblz4-tool \
ncurses-dev \
pearl \
python3 \
python3-dev \
python3-jinja2 \
python3-pip \
libgflags-dev \
libsnappy-dev \
zlib1g-dev \
libbz2-dev \
liblz4-dev \
libzstd-dev \
ninja-build \
I wouldn't say that I know what everything above does. I found these things in the other guides and I'm using them here as well. You can google and do the reading if you have time to understand what each one of the packages does.
Step 3: Cloning the repository
Now the server setup is done the next step is to clone the repository. There are a few places from which the repository can be cloned. I would recommend using the primary source to clone the repository and only if it is unavailable, it is recommended to use the mirror sources.
git clone https://gitlab.syncad.com/hive/hive
cd hive
git checkout v1.27.3
git submodule update --init --recursive
At the time of writing this article, 1.27.3 was the latest version and if you are checking this article later, you have to check which one is the current version and check out that version. Below are some of the mirror sites available to clone the repository if the primary repository is unavailable.
https://gitlab.com/hiveblocks/hive
https://github.com/openhive-network/hive
https://git.dbuidl.com/HiveClone/hive (maintained by @rishi556)
I would recommend using them only if the primary is not available. There can be built errors if the repository was not properly cloned.
Step 4: Create a build folder and compile the code
There are two ways to compile the code. You can either use make or ninja. We can create a new directory inside the hive directory after cloning. We are already inside the hive directory from the previous step.
mkdir build && cd build
Below is the command to compile the code with make.
cmake -DCMAKE_BUILD_TYPE=Release ..
make -j$(nproc) hived
make -j$(nproc) cli_wallet
make install
Below is the command to compile the code with ninja
cmake -DHIVE_STATIC_BUILD=ON -DBUILD_HIVE_TESTNET=OFF -DCMAKE_BUILD_TYPE=Release -GNinja .
ninja install
The compiling works in both ways but I saw a few recommendations to use ninja instead of make. After this step is done, you can check the version of hived using the below command.
hived --version
It should give an output similar to this based on the version you are running.
{"version":{"blockchain_version":"1.27.3","hive_revision":"b512d8fc126fbbfb23d4de5b9154517aa00fcc4e","fc_revision":"b512d8fc126fbbfb23d4de5b9154517aa00fcc4e","node_type":"mainnet"}}
Step 5: Downloading the Block_log file
There are two options to get the block_logs. You can either download a copy from others and sync only the remaining blocks or replay the blocks from the beginning. In option one, if you would like to download the block_log file, it can be done from the below location.
https://gtg.openhive.network/get/blockchain/compressed/
Thanks to @gtg for this. HF26 introduced a feature where we can use a compressed block_log file. This reduces the space requirement for hived instances. There is also a utility available in the package itself to compress the existing logs, if not you can download the compressed log from the above location and get started from there.
Directory for holding data
You would be wondering where to place the above files and what would be the default location for the hived instance. Other guides recommended creating a new directory for this and copying the config with the below command.
cd /root
mkdir hive-data
hived -d /root/hive-data --dump-config
In my case, I did not create a new directory but instead used the below command to create the config file.
hived --dump-config
This will by default create a folder called .hived inside the root and have all the data inside that folder. I found it comfortable and started using that. People who would like to replay the blockchain from the first block can ignore the below commands.
cd /root/.hived/blockchain
wget https://gtg.openhive.network/get/blockchain/compressed/block_log
wget https://gtg.openhive.network/get/blockchain/compressed/block_log.artifacts
The block_log file and block_log.artifacts file can be downloaded to the above directory. If you had created your own data directory, the files should be placed inside the /root/hive-data/blockchain directory.
Step 6: Updating the config file
In the previous step, we would have used a command to dump a config file. That would create a config.ini file and place it inside the data folder which is /root/.hived/ in our case. Updating the configuration is the next important step.
plugin = witness condenser_api database_api network_broadcast_api account_by_key account_by_key_api block_api wallet_bridge_api
webserver-http-endpoint = 0.0.0.0:8091
webserver-ws-endpoint = 0.0.0.0:8090
witness =
private-key =
There are so many parameters in the file that can be updated, but I only updated the above parameters and it was enough for me. People can choose whichever plugin they want to enable in the node based on their needs. Some plugins are basic and other plugins can be enabled if they need it.
In my case, I'm going to be using my private key directly in the config file as I'm keeping my server private. If people want to use their private keys in a secure way, I strongly recommend the cli_wallet feature that is explained in the other guides.
Step 7: Replaying the node and syncing
The next important part is to replay the node and bring it to the current block. You either do the replay with a block_log file that you downloaded or without any block_log file. Doing the replay without the block_log file can take some time based on your server specs. The below command can be used to replay the node.
hived --replay-blockchain
The above command will check for the existing block_log file in the default location /root/.hived/blockchain and start replaying, if not available it will create a new file in that location and start replaying from the genesis block. For people using a custom data directory, the below command should be used.
hived -d /root/hive-data --replay-blockchain
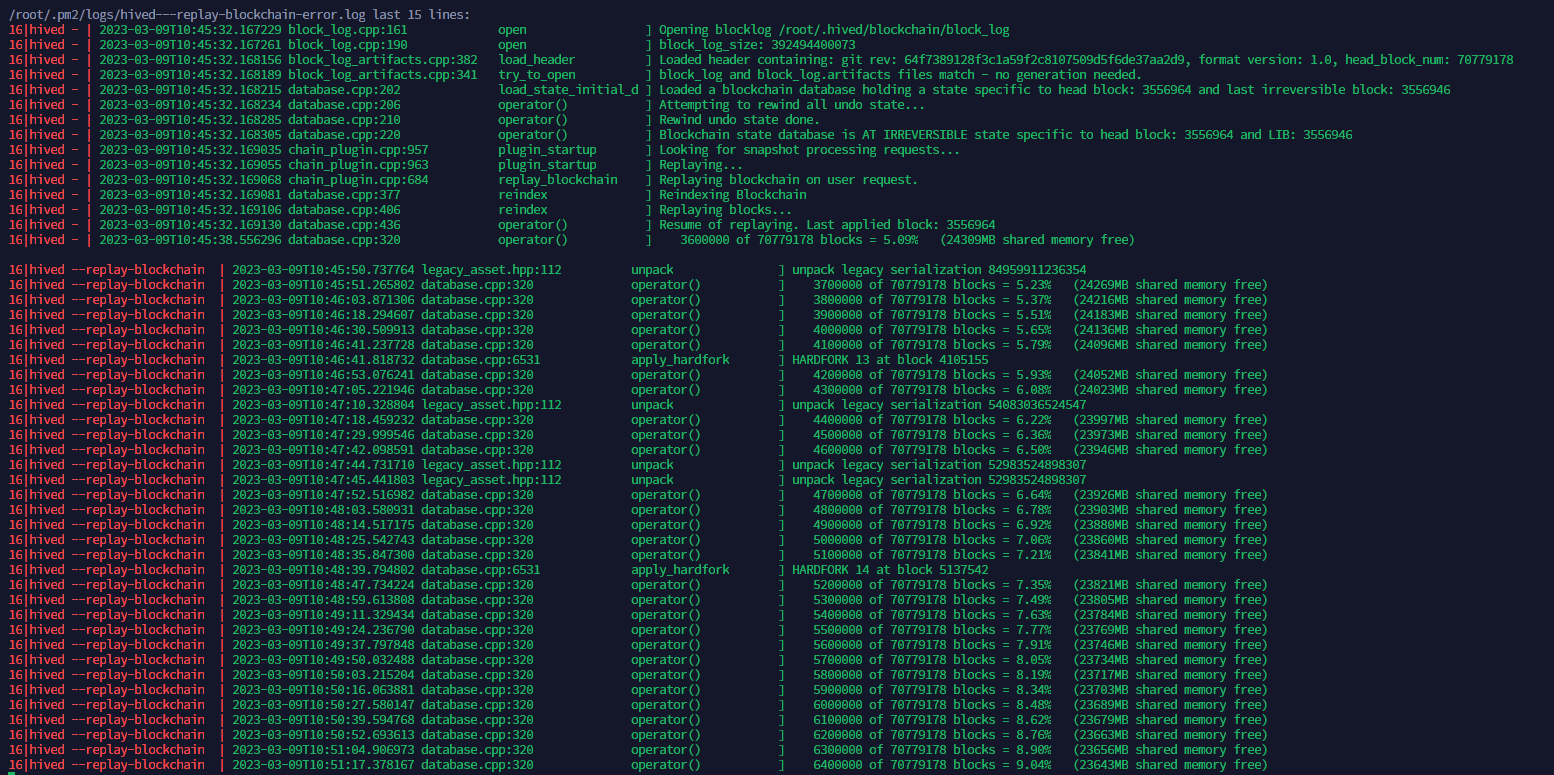
The above image shows what happens when the replay is started. There is no harm if we stop the replay. When we run the same command again, it would resume from where it left off.
Step 8: Syncing and running your node
If you have an existing block_log file, the replaying should be faster and after the replaying part gets over, syncing will start. For running the node, you don't have to use the command --replay-blockchain anymore. It is sufficient to run the command hived alone and if syncing is required, it would sink up to reach the latest block.
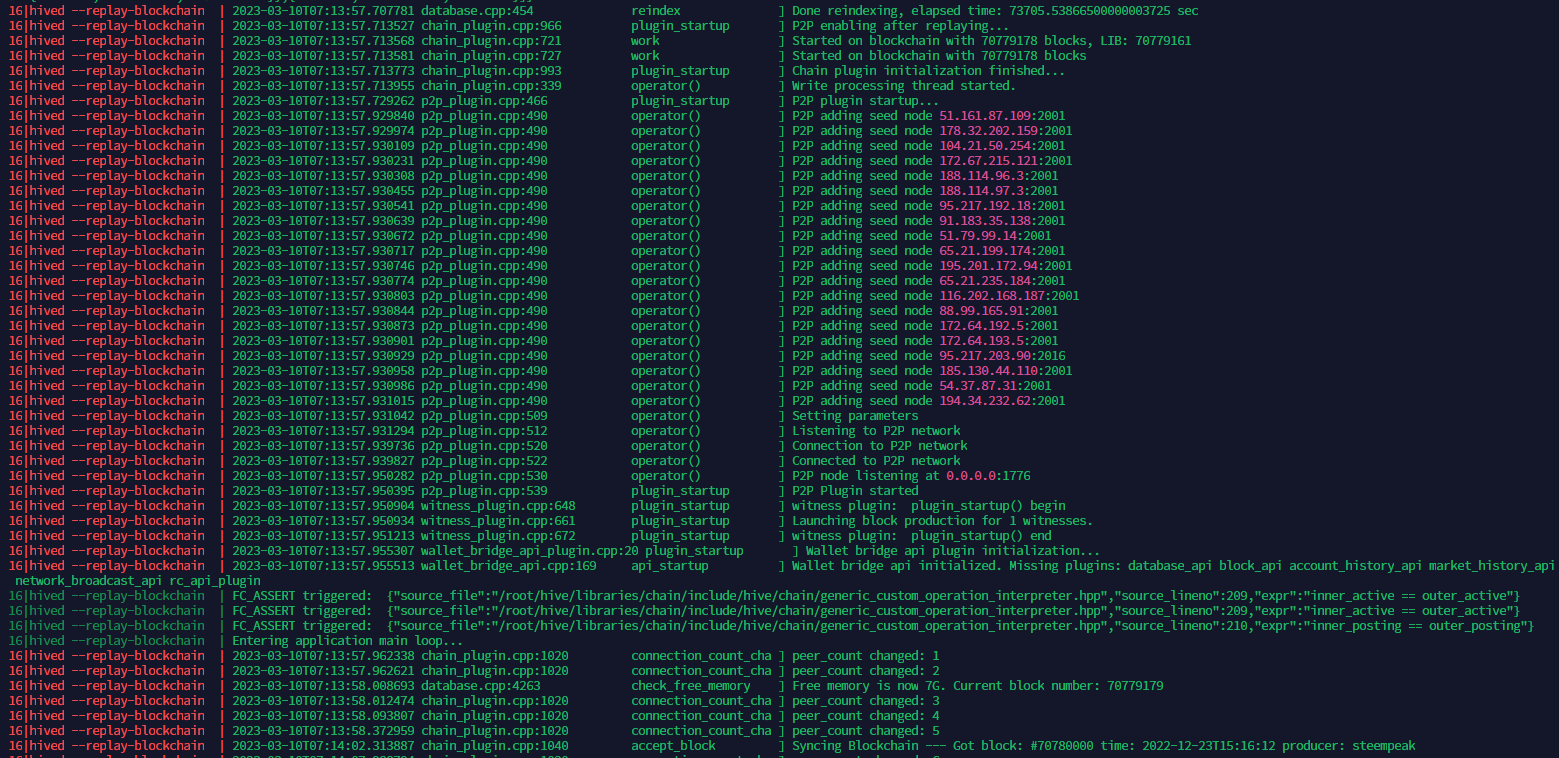
The above screenshot shows that the replay is done and syncing is starting in the last line.
Difference between syncing and replay
I had the same question too and I thought both were the same. Then I realized there is a small difference between both. Replaying is when the node catches up with an existing block_log file until the highest block in the file. Syncing usually happens after that. Let's say the current block of the chain is 7000 and the highest block in the block_log file is only 6000. The process of catching up after 6000 blocks till 7000 blocks are called syncing. In the case where there is no block_log file, the node would have to sync from the genesis block.
Step 9: Keeping the node running
Using the hived command directly would run the node and show us the logs but if we disconnect the node will stop. In order to keep it running in the background even after we disconnect, we can use 3 methods.
- tmux
- screen
- pm2
The other guides mention using screen or tmux which is good. But I personally like using pm2 because I'm going to anyway use it to run my pricefeed service. I'm not going to go into details of installing nodejs. Assuming you have installed nodejs, the below commands can be used to run the node as a process inside pm2.
npm i pm2 -g
pm2 start "hived" --time
The above command will create a process and keep it running. Those who are familiar with pm2 should know the features and make use of them to start, stop, restart and view logs, etc.
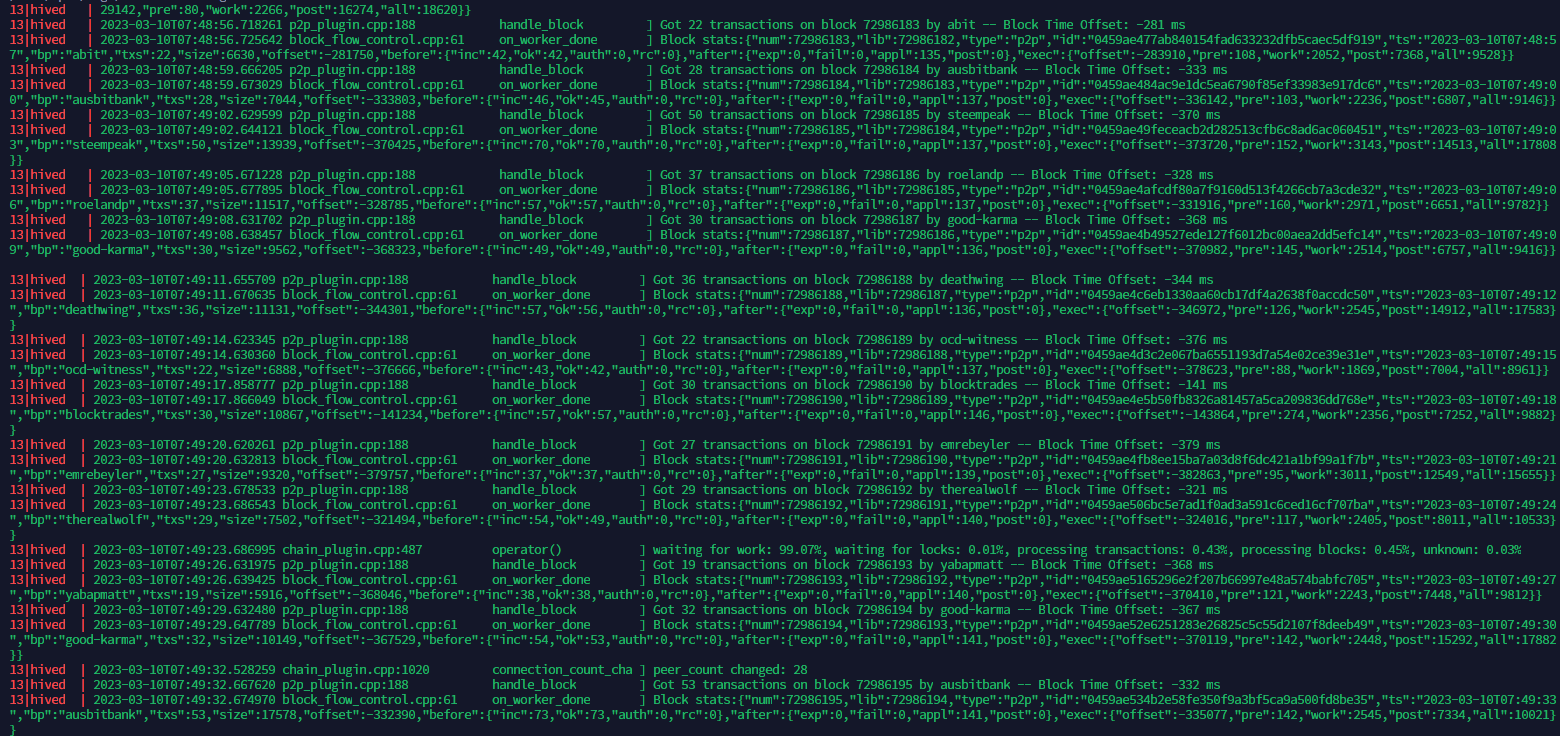
A normally running node should look like the above. A new block is produced every 3 seconds and details should be visible over there.
Step 11: Enabling and updating the witness parameters
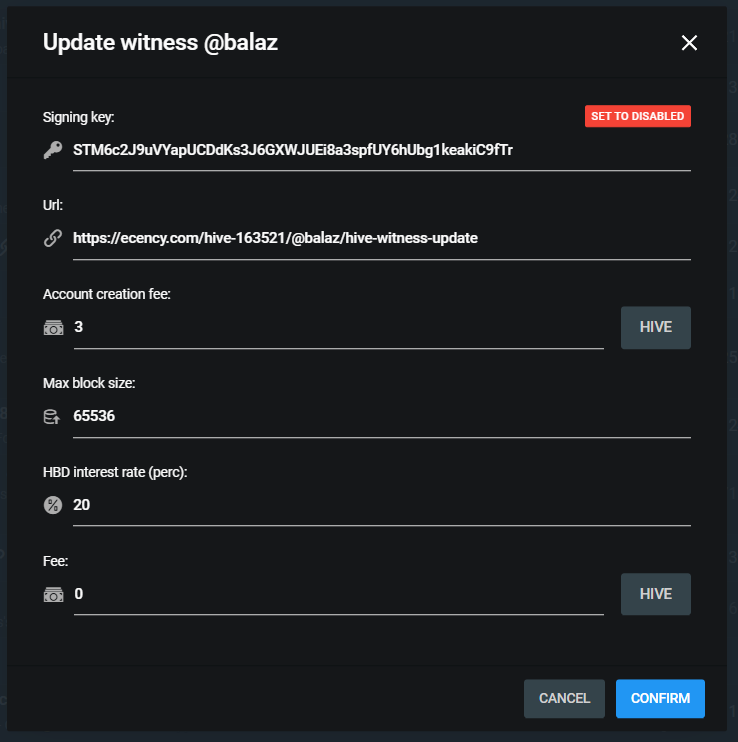
The witness can be enabled with the help of the below command directly from the server. But I still prefer using the Peakd interface to do the update.
update_witness "balaz" "[https://ecency.com/hive-163521/@balaz/hive-witness-update](https://ecency.com/hive-163521/@balaz/hive-witness-update)" "STM6c2J9uVYapUCDdKs3J6GXWJUEi8a3spfUY6hUbg1keakiC9fTr" {"account_creation_fee":"3.000 HIVE","maximum_block_size":65536,"hbd_interest_rate":2000} true
There is a nice interface available on Peakd to enable and update the witness parameters.
For geeks who would like to do the update directly by broadcasting an operation, the below can be used to broadcast with your own code or via keychain from your own website. Whichever method is suitable and convenient for you can be used.
[
[
"witness_update",
{
"owner": "balaz",
"url": "https://ecency.com/hive-163521/@balaz/hive-witness-update",
"block_signing_key": "STM6c2J9uVYapUCDdKs3J6GXWJUEi8a3spfUY6hUbg1keakiC9fTr",
"props": {
"account_creation_fee": "3.000 HIVE",
"maximum_block_size": 65536,
"hbd_interest_rate": 2000
},
"fee": "0.000 HIVE"
}
]
]
Some of the above parameters take effect only if you are a top 20 witness. But even otherwise it is a good practice to keep all the values up to date.
Note: The details about your witness will be visible only after you produce your first block.
Step 10: Updating the price feed
Pricefeed update is considered important and it sometimes is also used as a parameter by people to decide whether to vote for someone as a witness or not. It is very easy to update the price feed. Below are links to some of the public repositories that can be used to run a service that updates the price feed.
https://github.com/brianoflondon/v4vapp-hive-pricefeed - Credits and thanks to @brainoflondon. It has some unique logic and people who like python can use this.
https://github.com/someguy123/hivefeed-js - Credits and thanks to @someguy123 and @rishi556. This is being used by many people and is very handy. It updates the price feed based on the interval we set.
https://github.com/Jolly-Pirate/pricefeed - Credits and thanks to @drakos. This is a little optimized version of the price feed and is also being maintained well. I personally use this.
Step 11: Associating a domain to your hived node (optional)
Some people keep their nodes private and some people are happy to associate a domain to their node and make it public. For people who would like to associate a domain with their nodes, the below article will provide the details.
https://ecency.com/hive-163521/@balaz/step-by-step-guide-t-21-03-2023-guuqz
Caddy is my preferred method.
Note: Keeping your Hive witness server protected is very important. If you want to run an RPC node or expose your RPC node to the public, it is recommended to run it in a separate box and not combine it with your witness server. Having an intermediate Cloudfare tunnel to your server from the DNS is also safe if you enable RPC and expose it for public use.
Errors and challenges
Item 1:
While doing the initial server setup while trying to install packages or upgrade packages, I came across the ablow error message. The issue was because the installation file Hetzner provided was having some unwanted package installations done. Removing those packages got the issue resolved.
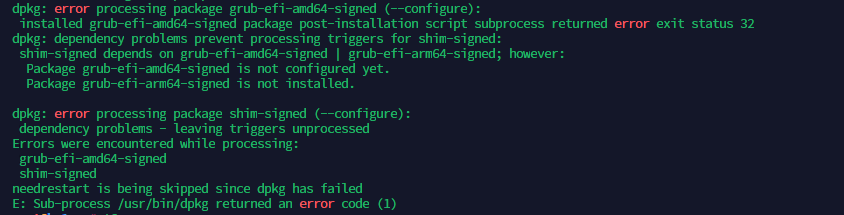
The resolution for the above problem is available here.
Item 2:
After I tried to build the package I got the below error message. I did try using cmake as well as ninja as someone suggested, but the issue was still there.
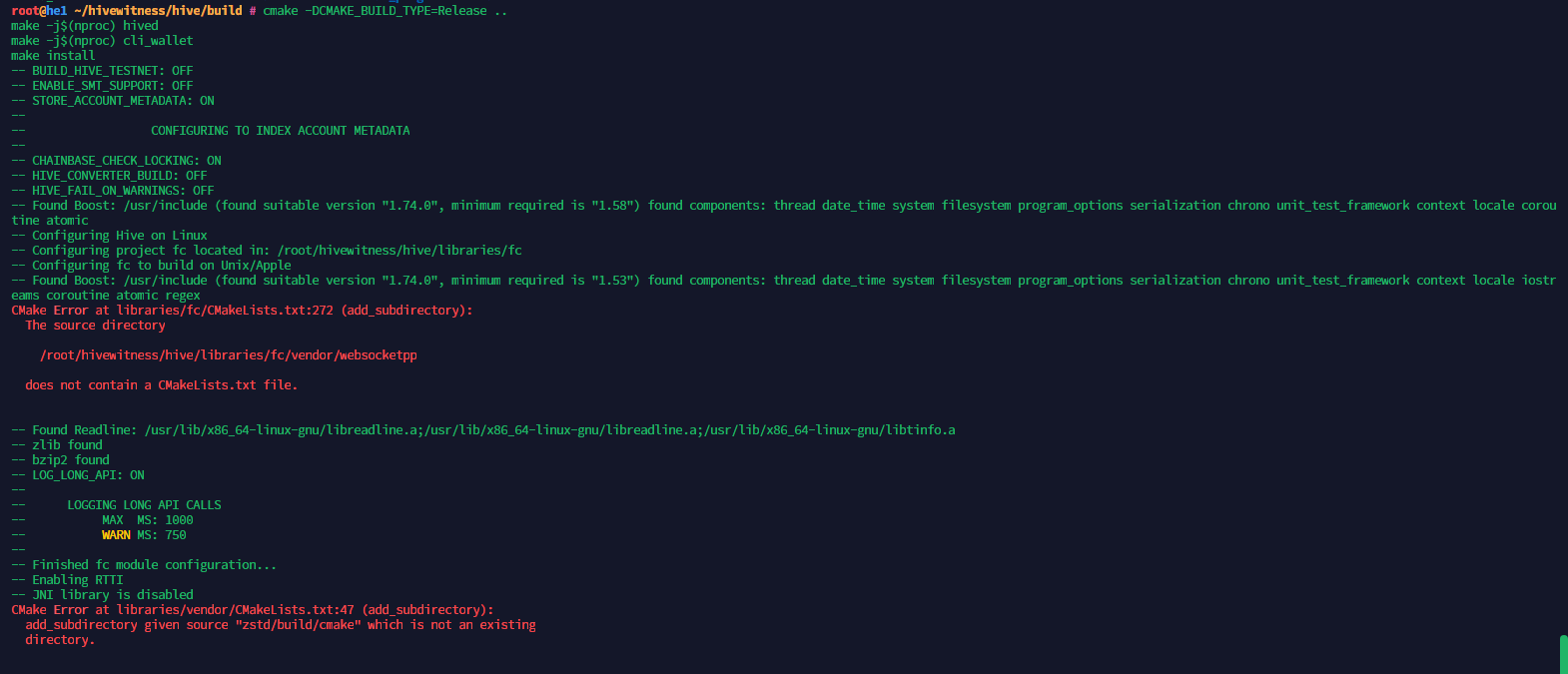
Someone then suggested cloning the repository again from a different source. This time I cloned the repository from the GitLab directly instead of using any of the mirrors and tried to do the build again and it worked.
If you like what I'm doing on Hive, you can vote me as a witness with the links below.
 |
 |
 |
 |
 |
 |
~~~ embed:1640646860816920578 twitter metadata:MTgwMzU1NTg5fHxodHRwczovL3R3aXR0ZXIuY29tLzE4MDM1NTU4OS9zdGF0dXMvMTY0MDY0Njg2MDgxNjkyMDU3OHw= ~~~
The rewards earned on this comment will go directly to the people( @documentinghive, @bala41288 ) sharing the post on Twitter as long as they are registered with @poshtoken. Sign up at https://hiveposh.com.
Cannot open the post. 😏 Always get an error message from Ecency.
Sounds very interesting, this guide though.
Yes, I noticed that too. I have reported this on the Ecency server. It works on the web though.
Interesting guide, I've always wondered how you set up a witness node. Btw, Hive-Engine node setup is similar as well?
Hive Engine setup is something different. I have a guide for that too.
https://stemgeeks.net/hive-163521/@bala41288/step-by-step-guide-to-setup-hive-engine-witness-from-scratch
So helpful!
!1UP
Thanks. Cheers!
NO!!!! Not with your witness node. Another node that you keep lying around with the same specs with your node, sure. But not your witness node. You don't want to expose that to the public and cause any unnecessary issues.
Too fast to reply. Please check the Note in that section. 😂
That section should be renamed in that case since it's not a witness node, but just a regular hived node.
Oops yeah, bad title. Agreed. Updated it.
Better to remove it. It just adds confusion when you mix topics.
$WINE
0.200 WINEXCongratulations, @theguruasia You Successfully Shared With @balaz.
You Earned 0.200 WINEX As Curation Reward.
You Utilized 2/4 Successful Calls.
Contact Us : WINEX Token Discord Channel
WINEX Current Market Price : 0.084
Swap Your Hive <=> Swap.Hive With Industry Lowest Fee (0.1%) : Click This Link
Read Latest Updates Or Contact Us
You have received a 1UP from @wrestorgonline!
@stem-curator, @neoxag-curator
And they will bring !PIZZA 🍕. The @oneup-cartel will soon upvote you with:
Learn more about our delegation service to earn daily rewards. Join the Cartel on Discord.
$PIZZA slices delivered:
(7/20) @curation-cartel tipped @balaz (x1)
Congratulations @balaz! You have completed the following achievement on the Hive blockchain And have been rewarded with New badge(s)
Your next target is to reach 4000 upvotes.
You can view your badges on your board and compare yourself to others in the Ranking
If you no longer want to receive notifications, reply to this comment with the word
STOPCheck out our last posts:
Support the HiveBuzz project. Vote for our proposal!
hey! Where on peakd.com can I find the Witness Update panel? I can't seem to locate it.
You have to login from your witness account and go to the witnesses page. Then against your name in the list, you will be able to see the set properties option.
Oh, OK. I have been experimenting with running a witness, but when I try to run the command from the wallet command line, I get the error "unable to create a database lock" (or something similar, I am not in front of it)
That is why I can't get to the interface on peakd yet. I will keep troubleshooting when I get time. Thanks!
Unable to acquire database lock
{"error":"Unable to acquire database lock","data":{"id":1,"error":{"code":-32003,"message":"Unable to acquire database lock"}}}
state.cpp:38 handle_reply
Have you ever seen this error while running update_witness?