A few days ago, I converted my original script, which is written in Python and only ran locally on my computer, into an application that can run in a browser with an interface. You can find the article here: https://peakd.com/hive-139531/@louis88/a-single-file-analytics-tool-to-find-post-payouts-from-a-list-of-users
I was actually very happy with the development, as everything worked as I had imagined. But for a long time I had been thinking that retrieving information for every single API call per account is simply too resource-intensive and takes far too long. The idea that came to me was to rewrite the software in such a way that it can be realized with the HiveSQL database query, since information can be retrieved directly and almost instantly. Since I am not very familiar with SQL, I simply discarded this idea and continued working with the API endpoint version. After I published the API version on Github the day before yesterday, I took it upon myself to spend the day yesterday getting to grips with SQL a little more. I became aware of the new development by @blocktrades and @mahdiyari, who have published HAFSQL. More about this in the articles
https://gitlab.com/mahdiyari/hafsql
https://gitlab.com/mahdiyari/hafsql-api
https://peakd.com/hive-139531/@mahdiyari/hafsql-update-200-rc1-breaking-changes
https://peakd.com/hive-139531/@mahdiyari/public-hafsql-database-on-haf
Proposal: https://peakd.com/hive-139531/@mahdiyari/proposal-public-haf-hafsql-database-maintenance-and-development-of-hafsql
SQL Calls are the Solution
My goal was not to retrieve lists of 18,000 for several hours via the API calls, for example, but to get to the details quickly, because waiting several hours was simply lousy and I no longer wanted to. So yesterday I took the time to rebuild the software based on calls to the HAFSQL database from mahdiyari. I have to say, this variant is simply lightning fast and delivers exactly the result I expected. However, I still had another problem - I can't make SQL queries from a local HTML document, for example, so I have to outsource the software to a web server using NodeJS, for example, so that the queries work. Locally this wasn't a problem, but so that you can view and use the software, I had to switch to a service called Render.com, which provides me with a mini-server and receives a ping from uptimerobot every 5 minutes so that the server is (hopefully) permanently online. Anyway, I'm happy that after many hours of work it worked and services like Hivewatchers but also every single user of yours can work with it. Here is the software with the HAFSQL integration:
Hive Analytics Dashboard (using HafSQL)
A web-based dashboard for monitoring Hive blockchain posts using HafSQL database. This tool allows you to track posts from multiple accounts, monitor their payouts, and analyze engagement metrics.
Live-Version
(Running on Render.com / If Service is unavailable - please drop me a Message.)https://hive-fetcher-hafsql.onrender.com/
Github Repo: https://github.com/louis-88/hive-fetcher-hafsql
Screenshots
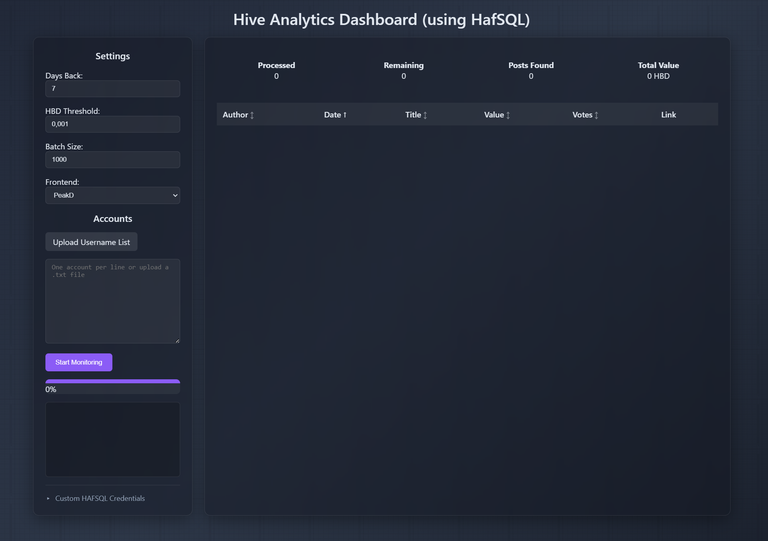
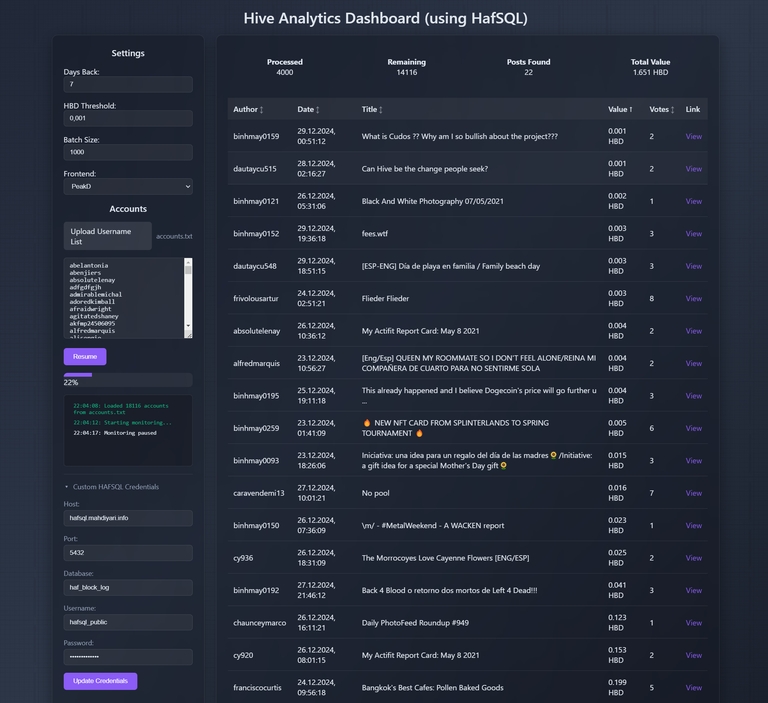
Features
- Monitor multiple Hive accounts simultaneously
- Track post payouts and engagement metrics
- Batch processing of account data
- Customizable time range and payout thresholds
- Real-time progress tracking
- Sortable results table
- Support for both PeakD and Hive.blog frontend links
- Custom HafSQL database connection configuration
- File upload support for bulk account lists
Installation
- Clone this repository:
git clone https://github.com/louis-88/hive-fetcher-hafsql.git
cd hive-hafsql-fetcher
- Install dependencies:
npm install
- Start the server:
node server.js
- Open your browser and navigate to:
http://localhost:3000
Usage
Enter Hive usernames (one per line) or upload a text file containing usernames
Configure settings:
- Days Back: How far back to look for posts (1-30 days)
- HBD Threshold: Minimum payout value to include
- Batch Size: Number of accounts to process at once
- Frontend: Choose between PeakD and Hive.blog links
Click "Start Monitoring" to begin processing
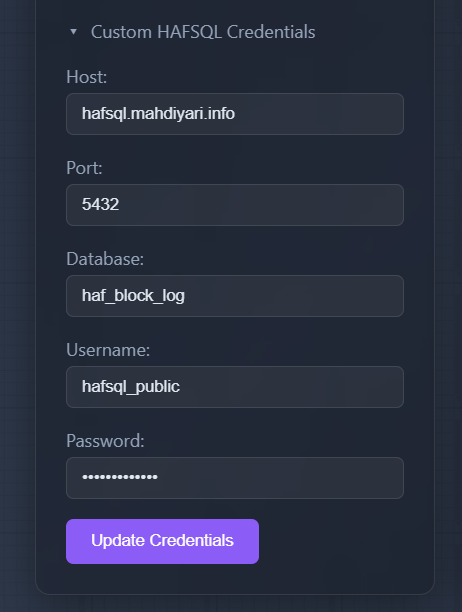
Default HafSQL Connection
The dashboard comes preconfigured to connect to the public HafSQL instance:
Host: hafsql.mahdiyari.info
Port: 5432
Database: haf_block_log
Username: hafsql_public
Password: hafsql_public
You can change these settings through the "Custom HAFSQL Credentials" section in the dashboard.
Tech Stack
- Frontend: HTML, CSS, JavaScript
- Backend: Node.js, Express
- Database: PostgreSQL (HafSQL)
- Additional: pg-pool for database connection management
API Endpoints
GET /: Serves the main dashboardPOST /update-credentials: Updates HafSQL connection settingsPOST /query: Fetches post data for specified accounts
License
MIT
That's it for now - if you have any questions or suggestions, please write a message in the comments.
I ran into some things that I couldn't get to work the way I wanted with Python and using HIVESQL was the way I was able to finally get it done. If you can program in those other languages, SQL shouldn't be too hard for you. Just a lot of referencing tables and stuff.
I have to say, you still did a great job maintaining the frontend to a single file which is amazing for me as a newbie in frontend dev. And hosting a tiny backend is your simplest way to go with HafSQL.
Anyway, thanks for sharing your usage of HafSQL! I need it in my project as HiveSQL will not be free anymore soon.
Hopefully HiveSQL will stay free to use thanks to community support. At least, thank you for yours.