
There are multiple ways of running a hived node. In this post we use docker compose for an easier setup. By default everything will be contained in one directory for easier management.
Hive Node Setup for the Smart, the Dumb, and the Lazy.Recently @gtg also published a good post. You might want to check that out. It is a good post specially for the exchanges:
Requirements
- Ubuntu 22
- Storage:
- 1TB: for running a proper node with all the blockchain data
- recommended for seed nodes and witness nodes
- 50GB: for pruned node
- This node won't keep any blockchain data
- e.g. use case would be having trusted source of state data like balances
- To run "pruned" node you must add
block-log-split = 0(orblock-log-split = 1for one million blocks in storage) in config.ini
- To run "pruned" node you must add
- RAM: 4-64GB
- You can get away with less ram by putting shared_memory on disk
- I would recommend at least 8GB of RAM - Feel free to experiment
- Otherwise you need at least 24GB of RAM dedicated for SHM (shared_memory)
- 32GB "should" be fine in this case - have not tested
- With more plugins your SHM might grow and you might need more RAM
- SHM on disk is totally fine (NVME/SSD)
Docker
Docker installation is simple:
curl -fsSL https://get.docker.com -o get-docker.sh
sudo sh get-docker.sh
Optional security step:
You might want to run hived and docker under a non-root user which is recommended.
# Create a non-root user - I name it "myuser"
adduser myuser
# Allow the user to run docker
addgroup myuser docker
# Switch to the user
su - myuser
While on the security topic, you might want to disable the password login on your server and use ssh keys and also install fail2ban for additional security. You can do that after setting up hived with the help of internet.
Hived
git clone https://gitlab.com/mahdiyari/hived_docker
cd hived_docker
cp .env.example .env
Now edit .env file accordingly. You set the hived version and the hived arguments there.
nano .env
P2P sync
For a p2p sync set ARGUMENTS="" in the .env file (which is done by default).
# Start hived in the background
docker compose up -d
Replay
The p2p sync should be fast enough for most people and I would recommend just doing that but if you already have a block_log you can try replaying.
The newer hived (not released yet - v1.27.7) by default will use splitted block logs instead of the legacy single block_log file. So even if you put one block_log, it will split it first and you should pay attention to your storage space in this case as 1TB might not be enough. To keep using the single block_log, you have to edit the config.ini before replaying.
By default the config.ini will be in the following location:
nano datadir/config.ini
Add block-log-split = -1 to keep block_log a single file.
You need ARGUMENTS="--replay" in the .env file. Then:
docker compose up -d
I recommend the P2P sync if you already don't have a block_log as the download speed of the block_log will probably be too slow to justify it over the P2P sync.
Docker commands
Docker commands that might be useful:
# see last 100 lines of logs
docker compose logs -f --tail 100
# stop and remove the container
# DO NOT force shut down hived
docker compose down
Witness node
To run as a witness you need to do additional steps. Generate a pair of keys and put the private key in your config.ini and add the public key to your hive account.
The secure option for generating keys would be something offline like the cli_wallet or some other wallet. But you could also use something like https://hivetasks.com/key-generator to generate random keys then copy one of the corresponding private and public keys. The website is safe at the time of writing. For this example I picked the generated posting key. It doesn't matter. You just need a pair of matching keys:
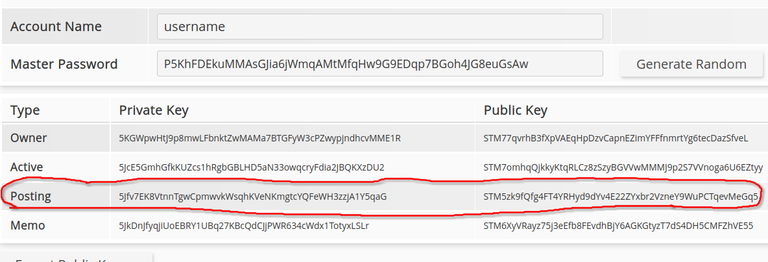
datadir/config.ini
witness="username"
private-key=5Jfv7EK8VtnnTgwCpmwvkWsqhKVeNKmgtcYQFeWH3zzjA1Y5qaG
Then you can use https://hive.ausbit.dev/witness to register a new witness or update an already existing one. You would need to login first to the website then refresh.
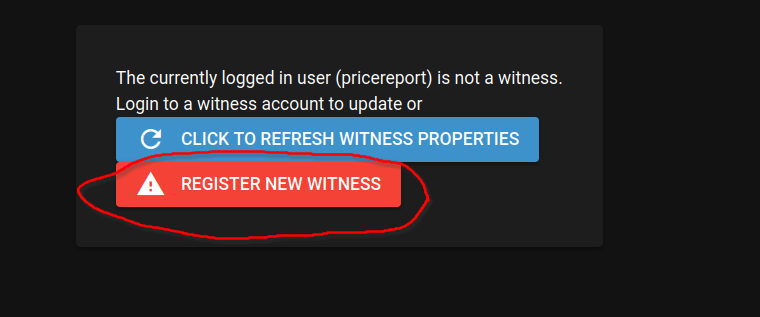
Then we put the public pair of our signing key in there and broadcast the the transaction:
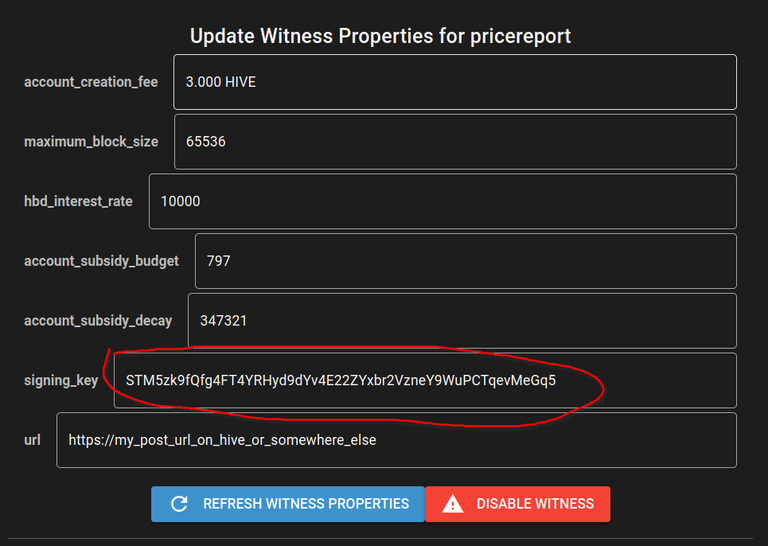
Scroll down and:
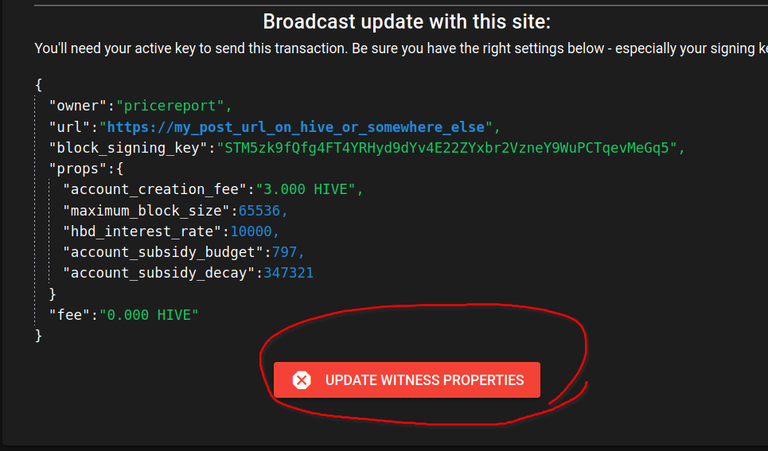
You can ask your technical questions in the official hive discord (which you can find on hive.io bottom of the page) or #witness or #dev channel on https://openhive.chat/
For future hived updates, you would just need to edit the hived version in the .env file and be good to go.
*The first image is taken from pixabay.com
About system requirements: not sure how much ram is needed but I run node on machine with 4 gigabytes (maybe 32 gigabytes is for building hive from source. Also if you have limited disk space - you can run smth like "pruned" node in bitcoin - don't store all block log at all or store only 1milion last blocks. To run "pruned" node you must add "block-log-split = 0" (or "block-log-split = 1" for one milion blocks in storage) in config.ini. Massive sync from 0 takes like 1-2 days nowadays. It should be possible to run node on raspberry pi with external ssd like 50gigs, not tested this thought raspberry pi is ARM not sure if this will work smoothly. But for full block_log it takes like 1TB.
I edited the requirements with more info.
4TB of NVMe or SSD is kind of high...
This post is about just a hived node. Which is a witness/seed node. The screenshot covers HAF and Hivemind too. Those are separate software that offer more APIs to the interfaces like peakd and ecency.
Great! So I can get away with a 1TB hard drive to run the witness node?
Yes
You are right. It should be possible to run hived on lower end machines with pruned block_log.
I should have probably mentioned that as well. Thanks.
I remember not being able to run hived with 8gb of ram but I think that was building from the source. I didn't think about it that much as with this one I was aiming for seed nodes and I don't think running a public seed node without the block_log would be that beneficial. But for other uses, it is valid.
What internet speed does one need to have to run a node?
Speed generally doesn't matter that much other than the initial sync that you need to download the blockchain basically (~500gb). I did check one of my nodes and the data usage is around 250GB a month after the initial sync. Maximum block size is 64KB and that happens once every 3 seconds. So you should be fine on any speed.
Definitely don't generate keys using an online service. Maybe it does the right thing and never sends the keys to the server where it's hosted, but that kind of behavior might change over time, i.e. the server might get hacked, etc. Instead, the CLI wallet can be used to generate the keys locally.
Hmm, does this mean that when block_log is split into parts, it takes up much more space?
It doesn't consume the original block_log when generating the parts. So you end up with 2 full block_logs. Hence more space usage while splitting.
With docker setting up witness node looks pretty easy. But which hosting you can recommend to use their VPS for running witness node?
Also is there any option to run hive-engine witness node in docker?
Any hosting that you can find that is cheaper and meets the requirements. I have seen people use Hetzner (you'll get in trouble if they find out you are running anything crypto related), OVH, and scaleways.
I don't know about hive-engine. Try asking in their discord or check their repositories.
Hmm maybe you are right and in hive-engine discord it'll be really right answer about their witness node.
That's the reason that some hostings against to use their infrastructure for cryptography related things 🤷🏼♂️
And here I have another one trouble that if I'd like to order VPS I'll need possibility to pay for if from my country (since troubles with Visa MasterCard etc) or they need to accept crypto payments. But it's more problem of course now..
Also can you explain how to install cli wallet and how to install it?
I think it'll be enough link to this service or short description of it.
You can try ordering from the providers in your own country.
The binaries are available here for cli_wallet https://gtg.openhive.network/get/bin/ or you can build it yourself from the hive repository.
Thank you I'll try to look how to work with cli_wallet more detail!
Thank you for sharing such valuable content.
Is it only one terrabyte of storage? I thought it has to be more?
Also, is an Azure VM a viable option?
I would imagine Azure being very expensive but sure if it meets the requirements.
I used to run a node on AWS. Cost about $300/mo, so yes possible but VERY expensive.
I have a $150 credit every month from VS subscription, so was thinking of using that...
many, many providers that are out there, or colocate your own server with a provider.It might be possible to get it to fit within that price range using reserve: https://azure.microsoft.com/en-us/pricing/calculator/. I tend to avoid hyperscalers unless I need something that can scale quickly or to deploy to a bunch of regions easily or if I'm using a cloud native feature(aka lambdas). But whole lot cheaper to grab a dedicated server from one of the
So I got to docker compose up -d step on Azure VM and it seems like I need to adjust my network settings I got the following error:
unable to get image 'hiveio/hive:1.27.7rc16': permission denied while trying to connect to the Docker daemon socket at unix:///var/run/docker.sock: Get "http://%2Fvar%2Frun%2Fdocker.sock/v1.47/images/hiveio/hive:1.27.7rc16/json": dial unix /var/run/docker.sock: connect: permission denied
Oh disregard this, I need to run with elevated permissions :)
just add "sudo" in front of docker compose
Few comments/corrections:
docker composeis unnecessary when you run just one application container.Docker is pretty much deprecated nowadays as it have a better, mature successor: Podman (a.k.a. "libpod") https://podman.io/
Ubuntu (redundant Debian derivative) is unnecessary and unjustifiable. Since it have no technical reasons to exist, it is better to use Debian instead.
hivedv1.27.7have been (already) tagged/released on 2024-12-14: https://github.com/openhive-network/hive/releaseshived requires certain parameters to be applied when you run the container and with the help of compose yaml files you get to just start the container with a very short command. There is nothing wrong with other ways of running a container.
Debian should be fine but Ubuntu 22 is the recommended OS for Hive apps.
That's just a bad release naming. The latest unstable version of hived currently is 1.27.7rc16 so the logical next stable release should have been 1.27.7. Once there is a stable release I can edit the post.
What do you mean by "bad release naming"? Project obviously follows semantic versioning
: https://semver.org/ https://en.wikipedia.org/wiki/Software_versioning
In the same source you sent:
RC comes before the stable release
You can't have 1.0.0 then release 1.0.0-rc.1
The latest release of hived is 1.27.7rc16 (https://gitlab.syncad.com/hive/hive/-/tags) and you can't release that after releasing 1.27.7
RC: Release Candidate
1.27.7rc16 means it is a candidate to become 1.27.7
And no. hived does not follow semver.
I see, apparently developers made a mistake with tagging
1.27.7At least versioning pattern seems to suggest that there could have been an intent to use semver..., and they did not correct it by properly incrementing minor release number... Indeed it is a violation of versioning best practice. (I reported this issue as https://gitlab.syncad.com/hive/hive/-/issues/740)
Regarding "Ubuntu 22 is the recommended OS for Hive apps", host OS does not matter if you run Docker container anyway. Recommendation is obviously misguided, but at least it have some validity as notion that application builds from source in that environment (and that Ubuntu 22 is used as development environment by some active developers).
Bad news: developer demonstrated ill attitude and refused to acknowledge versioning issue... :(
!PIZZA
Thankyou for sharing this
For registering a new witness do you need to generate new posting keys or can you use your account posting key? And how long does it take to see the new witness on PeakD or other witness list after registering it?
You need a pair of keys. Public and private. For security it is better to generate a new pair. It will show up instantly but the information will be updated after producing a block.
I added private key to the config and public key to the witness registration. I see the transaction being submitted but witness is not showing up in the list. Do I need more than a posting key for the witness registration script? I am submitting with an active key from KeyChain.
You now need to get votes. You are an active witness.
Hive.Pizza upvoted this post.
$PIZZA slices delivered:
(8/10) @danzocal tipped @mahdiyari
Please vote for pizza.witness!
Thanks for this guide
It looks like my price feed isn't working. Any ideas what it might be? I kind of assumed it was related to the recent Hive Engine issues or too few blocks signed, but I see that other nodes have price feed working with only 3 blocks signed also.
Price feed is something that you publish as a transaction. There are scripts that do that for you.
I use this script https://github.com/Jolly-Pirate/pricefeed
Thank you! Price feed is fixed and working now :)