MinorFS 1.0
In the distance part I wrote a project in Perl, it was way back in the time that Perl was the language of choice for many things in the same way Python is today. The project was called MinorFS, and it was meant as a kind of glue project for allowing least authority system development. In Linux there are least authority features, be it in a rather static way, using security kernel extensions such as SELinux and AppArmor. At the programming language level there are least authority languages, called object-capability languages that provide the handles for true dynamic least authority. One amazing little language I had been playing with at that time was the e-language, that ran on top of the JVM, and implemented a feature of persitent processes through storage that, running in user space, was pretty much unprotected from attacks from below.
With my project minorfs, I primaraly created a bit of glue by implementing a user space filesystem that could bridge the cap between E and AppArmor. For more info on the project, after 15 years it seems the images are gone, but here is an article I wrote about MinorFS for Linux Journal.
MinorFS was actually two separate user space file-systems. The first, CapFS was a file-system where all files and directories had two valid names, a base name and a secure name, where the base name would show up in directory listings, and the secure name could be extracted from a file or directory by getting an extended attribute.
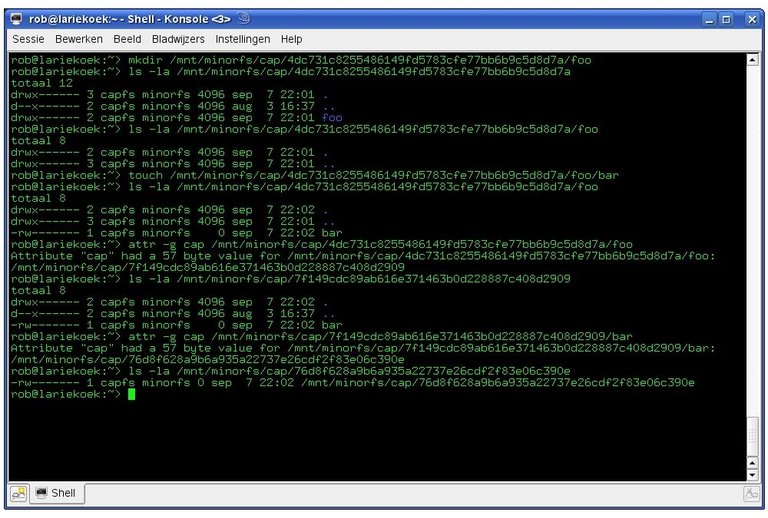
The second file-system was ViewFS and always contained two symbolic links into CapFS that were different for something that I referred to as a pseudo persistent process, in simplified terms being the n'th instance of something executable.
For e-language code this meant that if the persistent state was serialized to disk under the capfs dir linked to by ViewFS, then no other process running as the same user would have access to that data UNLESS the E program was to explicitly delegate a secure name (aka sparse capability or password capability in capability theory).
The initial version of MinorFS used an sql database to store the mapping between secure names and base names.
Erasure Encoding for CA key recovery.
Completely unrelated to caps or MinorFS, at some point in time I had to write code for a collection of offline certificate authority nodes running headless on Raspberry Pi boards, for access to a VPN.
All operations worked through files on an USB stick and leds. The normal operations of the CA's is irrelevant for this post, but there was one feature that I think is.
Because a CA ran on a Raspbery Pi with the key stored on a no longer non-destructively removable micro-sd card, the CA hardware was expected to fail. And given that the model was that of a non hierarchical infrastructure, there was no master CA and there were no slaves.
So how did I handle node failure?
Every CA RPi, next to its own private key got an erassure encoding shard of each of the other CA RPi-s. With erasure encoding you create what is basicly akin to a RAID disk array on a really tiny scale.
The CA RPi-s wouldn't just give up their shards, first an intent file had to be signed by more than half of the CAs. So the CA owner of the broken CA had to visit a shitload of other CA owners twice in order to initialize his replacement
CA RPi.
It wasn't a perfect system, by far, but it tought me how to work with erassure encoding, and tought me to apreciate erassure encoding for distributed redundancy.
CarvFS
Another (so far) unrelated denelopment was related to computer forensics. With MinorFS I had learned to apreciate the power of user space file-systems for system design.
CarvFS was another user space file-system meant for computer forensics, that allowed users and forensic tools to adress chunks of a bigger data unit as directories and files with location and size tokens forming the file and directory names.
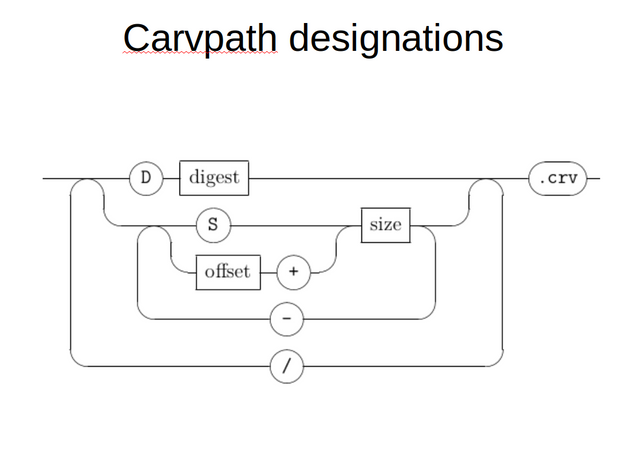
Most of CarvFS wasn't about hashing, but a tiny part was. If a fle or directory is made up of fragment descriptions, highly fragmented files can end up having names that are longer than the maximum file or directory name for the operating system. So to overcome this, MinorFS would automaticly convert potentially too long carvpaths to the hash of the carvpath, and store the back mapping in an sqlite database as we did in MinorFs.
MinorFS 2.0 (the concepts)
At some point in time I set out to create a from scratch version of MinorFS using a hashing algoritm for decomposition and authorization. What was more, I wanted to extent the usability beyond the object capability language realm, and address the problem of trojans with the rewrite. I did a talk on the subject during the OHM2013.

OHM2013 was one of a four-anual series of security/hacking festifals that used to get organized in The Netherlands. It was a great festifal, but with a bit of a sad tone to it as I learned that the person who had introduced me to capability bases security and who had set me on the path that had led to MinorFS, Hugh Daniel had died not that long before the festifal date.
The talks were recorder, but unfortunately the recordings from the tent I gave my talk in were lost, thus my talk isn't available online, but my slides are.

RumpelTree
Then things happened in my life, and I got the opportunity to get myself another M.Sc. An M.Sc in computer forensics. As a result, I had to scale down my MinorFS 2.0 activities. I ended up capturing the core hash based decomposition and atenuation algoritm in both a C++ and a Python
The great thing about the RumpelTree algoritm compared to the original CapFs implementation, apart from the fact that the sqlite database is no longer needed, is that it's a pure hash-based algoritm, and the data is encrypted with an AES key that is derived from the sparse-capability used to access the file.
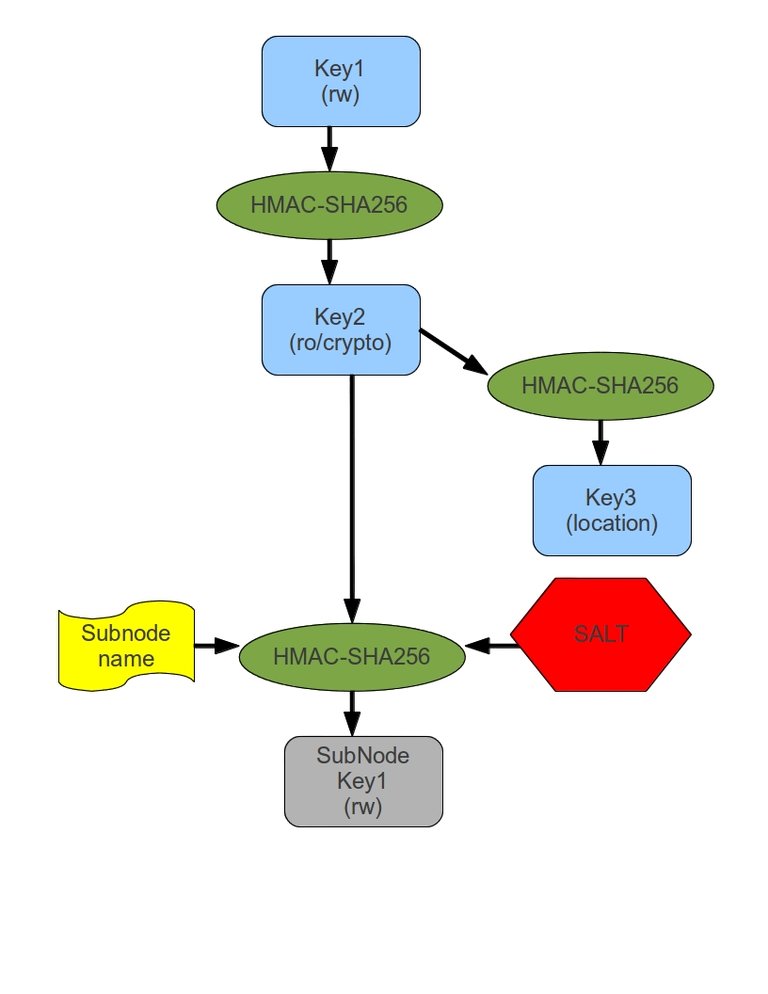
A quick walkthrough. Before we can reason about a file-system based on the abouve image, Let's first consider how we can create an initial root for a file-system that runs on top of some other file-system.
Let's start off with a simple json structure
{
"type" : "dir",
"dir" : []
}
Now we take a master password and hash it to a 32 byte key that we will use as key1. We take this key and we hash it again to get key2. Then we take key2 and we hash it again to get key3.
Now we take key2 and chop it into two 16 byte keys, we take the JSON and we encrypt it with AES-128 using the two 16 byte keys as AES key and IV respectively. After encrypting it, we take key3 and convert it to an alphanumeric value. For example using base32 encoding, or we could use base64 with some substitutions. We add some nesting to avoid directories with way too many files, so we end up with something like:
- JMU/JAZ/JOKCR5K3PW3AOYRL4TDZXYG2YMPFQ3U5XF6TKZJDE3VXBA
We write our encrypted JSON to this file and now we have a file system root for a capfs-like filesystem.
Now we need to remember the root sparse-cap somehow. We take key1 and encode it to something alphanumeric. We can prefix the result so we can distinguish betweenrw sparse-caps and read-only sparse-caps. So we end up with something like:
- rw-DHGYBBHFMNQNRNHRZXZUXE5LO4CTVB2JQTTMXFQLNULDEBIEBZIA
Now if we wanted to create a subdirectory, what would happen?
mkdir /mnt/capfs/rw-DHGYBBHFMNQNRNHRZXZUXE5LO4CTVB2JQTTMXFQLNULDEBIEBZIA/foo
The capfs implementation will take the sparse-cap, see it is meant to be a rw cap, decode it, hash it two times to get key2 and key3 again, check to see the location designated by key3 actually exists, open the file, decrypt it using key2, see that it is a directory and that foo doesn't exist, take key2, the name "foo", and a secret that only the file-system nodes know to create a new key1' for foo, hash that key twice to get key2' and key3', encrypt a new empty-dir json, encrypt it and store it in the new position, then add the string "foo" to the initial dir object (there are some race condition issues here that we will ignore because it falls outside of the scope of this blog post), and re-encrypt and write the updated directory json to the underlying storage.
MattockFS
In the years that I could't work on big projects because I wasn doing my computer forensics M.Sc, the knowledge and ideas didn't completely go to waste. During my research project where I looked into page cache efficiency in computer forensic disk image sprocessing at scale, I ended up writing a proof of concept piece of computer forensics architecture that again used a user space file-system, mattockfs, and part of this user-space file-system used a least-authority setup in order to provide a forensic computing module with least-authority access to the framework, even if different modules ran as the same user.
Basicly MinorFS combined features from CarvFS with ideas from MinorFS in order to implement API as a file-system concepts. For more info, have a look at this old blog post or have a look at my paper.
Part of my research included looking at the concept of opertunistic hashing in forensic frameworks, and to research this, I looked into many hashing algoritms. For my research I came to the conclusion that SHA1 and BLAKE2 together formed an ideal combination for computer forensics. SHA1 for compatibility with legacy forensic white and black lists, and BLAKE2 (BLAKE2bp to be exact)
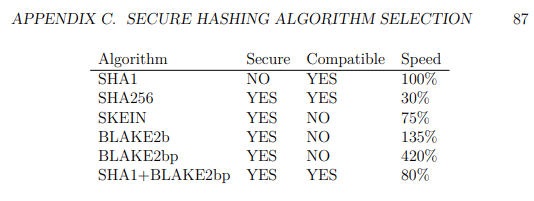
Since doing my M.Sc research, BLAKE2 has become my go-to hashing algo for most of my work, in forensics combined with SHA1, and outside of forensics on its self.
BLAKE2 is also the hashing algoritm used by libsodium, and amazing crypto library that takes a securety by default approach that works great when doing crypto in projects.
Ragnarok Conspiracy
Next to a tech geek, I'm also a self-published author of speculative fiction and sci-fi. For my novel Ragnarok Conspiracy I looked into the idea of a quantum computing blockchain heist.
In the novel, Wietse Dijkstra, a scientist that made a major discovery in the field of quantum physics in the 1990s got abducted and got hidden from the world for many decades by an unscrupulous organization that forced him to use his discoveries to create quantum computing technology aimed at industrial espionage.
Over the cause of multiple decades, this organization grows to secretly be the most powerfull entity in the world. In an attempt to expose his abductors, Wietse gets hold of the private laptop of one of his guards, and quantum-slices through all signatures and public keys he can find on the laptop to find the matching private keys that he puts back onto the laptop, disabling its boot capability in the hope some repair man outside of of the organization. He hides some quantum computing hardware in the laptop, hoping he can expose his abductors and the industrial espionage.

Unknown to Wietse, most of the crypto material on the laptop were blockchain data, so when the repair person where the laptop ends up ends up being a dating site scammer and hacker, the data on the laptop, before eventually exposing his abductors in a more dramatic way than Wietse could ever have imagined (The Copyright Wars), this doesn't happen before a massive quantum blockchain heist creates a domino effect that colapses the worlds monitary systems.
After having completed my novel, and having published it on what used to be the STEEM blockchain, before publishing it on regular ebook channels, an actual blockchain heist happened on the exact blockchain that I had published my fiction on.
After some readers of my fiction pointed me to Quantum Resistant Ledger I started reading up on QRL and on hash-based signing algoritms, and I started noticing the massive overlap between these algoritms and the work I had been doing with hash based algoritms, both in capability security and in computer forensics.
CoinZdense
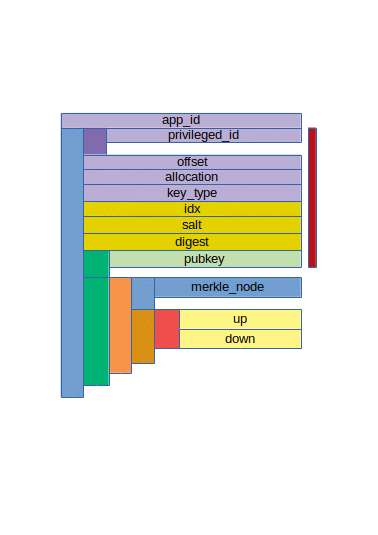
So with that my new and ambitious project CoinZdense was born. I looked into hash based signatures and found that there were some subjects that needed adressing. Next to the problem solved by QRL for coin-only blockchains, Web 3.0 and utility blockchains that have any type of user abstraction, the problem is deeper and wider than what can be solves with the road that QRL took. Where for coin-only chains quantum-safe key-reuse is a nice feature, but the reall killer feature of quantum resistance lies in resistence against peer to peer attack resistance. Imagine you create a transaction on a lagged chain, and as you don't care much about the transaction taking long, you set relatively low fees. Now the attacker with a huge quantum computer slices through your signature in some time T, creats a new transaction with your USOs and sets fees equal to half the value of your USOs. If the slicing happens fast enough, there is a chance that the attacker's transaction will make it to a block before yours does.
Utility chains and Web 3.0 chains will often have a problem that can materialize way before the peer to peer scenario becomes viable. For chains where key-reuse is not just a nice feature but an actual fundamental part of the architecture, signatures and public keys are just sitting there waiting for someone to have a big enough quantum computer to slice through them and retreive private keys. It won't matter if T is 1 minute, an hour, a day or six months, the attacker will have all the time of the world because the keypair isn't going anywhere.
Further, the setup that QRL uses wouldn't scale enough, because reuse on a social chain like HIVE where every thumbs up, every comment and every mark-as-read will be signed with the same key, making reuse something that happend dozens to hundreds of times a day. In case of trading bots likely many orders of magnitude more.
Finaly, key-management on blockchains are very far from least-authority. There sometimes are some static attentuated keys, such as the OWNER/ACTIVE/POSING setup in HIVE.
In CoinZDense I try to address all these things.
I'm especialy exited about the concept of index-space as a resource, that I'm really exploring with this project. Interesing enough it's also a subject where CarvFS CarvPath annotation might come back in.
Just like with my M.Sc though, my time isn't exactly abundant right now. I'm stuck in a slow and tedious and expensive divorce, and someone really special in my life is trying to restart her life with a new business in her country of birth and spending time on projects that don't assist me financially is something I can't affort that much right now. That means that without sponsors both my tech efforts and my fiction are running on a pilot light right now much of the time.
My priorities right now are:
- Work on my tech projects IF the work is at least partially sponsored
- Do work that helps me pay my legal bills and helps me prepare for restarting my life after my divorce is finaly final
- Anything I can do without spending money to help this special person get her business sorted.
- Unpaid unsponsored work on my tech projects
- My fiction
My current set of tech projects
Right now there are three related and interdependant tech project shtat I'm working on. One I already discusse abouve is the CoinZdense project, seem my talk from two years ago.
A second project is the aiohivebot library. This library aims to be an async python library for writing HIVE bots, L2 nodes and middleware.
A third project is the HIVE archeology bot, a HIVE bot for private usage that allows its owner to vote on (and reward) posts that are beyond their initial 7 day voting window.
The idea of working on all these three projects at the same time is that aiohivebot could provide a lib that is already usable for HIVE devs, while allowing to experiment with L2 hash-based signing and POLA subkey management by piggybagging hash based signatures onto ECDSA signed transactions with custom_json operations and JSON meta data on user account info, like its done in the HIVE CoinZdense Disaster Recovery tools did.
A least-authority quantum-resistant distributed filesystem with subkey management features ?
Even if my time is already quite short for working on these three projects, I'm still considering adding a 4th project. Given that the HIVE archeology bot is the simplest of the simplest bot, it might not be the best showcase or test of CoinZdense and aiohivebot suitability. A real L2 node, however simple, should be a much better demonstration.
I was thinking about this, and I was thinking about my old projects, MinorFS, RumpelTree, CarvFS and MattockFS. And I was thinking about my prior experience with errasure encoding based system and security design.
Then I remembered a talk me and a brilliant criminal lawyer co-presented in 2015, and one particular slide.

With MinorFS I wasn't the only one who wrote a least-authority file-system. Zooko, to paraphrase Sabina Hossenfelder's catchphrase "Yes, That guy again", the same Zooko from BLAKE2, had written a quite different type of least authority file-system, Tahoe-LAFS, where indeed LAFS stands for Least Authority File System. I remember discussing on the amazing cap-talk mailing list back in 2008 if there could be possibilities to use MinorFS and Tahoe-LAFS together. I don't remember the details, but it unfortuantely didn't lead to action back then.
When preparing for my talk, I checked up with Zooko about Tahoe-LAFS, he pointed me to RAIC.
So what if I could make a relatively simple L2 for HIVE using aiohivebot and coinZdense that provides the user with the concept of a distributed and redundant least authority file-system akin to an intersection of MinorFS and Tahoe-LAFS, if possible (currently a chalenge) with support for CarvPath based decomposition.
The idea would NOT be to create anything for big storage, no videos, nothing the size that would even justify puting relevant data off-chain away from L1. L1 already has redundance, it just doesn't have least auhority or confidentiality for that matter.
Just HIVE for now, but just "for now"
Right now I'm focusing on the Python version of CoinZdense and all my other efforts are currently focuses on HIVE. This is however not the end station, at least not for CoinZdense.
I've been the main developer of the aioflureedb async Python library for FlureeDB,plus the Fluree Schema Scenario Tool TDD tool for FlureeDB, and I think FlureeDB, a blockchain bases graph database written in Clojure, would actually be an exelent piece of technology for a sidechain project.
Like HIVE, FlureeDB is a blockchain project for what key reuse is truly a valuable spec for an underlying signing algoritm, and as such just like HIVE, FlureeDB could benefit a lot from a (slow) move towards hash based signatures.
I could most definetely see great value at adding FlureeDB to the mix, but for now, while I am focusing on Python, FlureeDB will need to most definetely wait. It is important to realize though that I have no intent to keep limiting my CoinZdense related development to just targeting HIVE. HIVE is just currently everything I can remotely consider to have time for.
I'm still learing Clojure at the moment and wouldn't consider myself anywhere close to the level a programmer in Clojure that I am in C++ and Python, so there are multipe reasons to put FlureeDB back on my list of blockchain technology to adress with CoinZdense, but primary is the limited time I can affort to spent on everything.
And FlureeDB isn't the only one on my list, though it and HIVE are the only ones where I did a bit of a deep dive into the code and ecosystem so far.
I really need to look into Agoric, Rune and Atom and their ecosystems are still on my radar, though I'm not sure right now I'll ever manage to get to the point where I would be working on exploring any of these for CoinZdense pigyback proof of concepts like the one I'm working on with my current three projects for HIVE.
The trust model
One important note about the trust model for what I am considering building. I shall be using the RumpelTree trust model combined with that of the RPi CA setup as I discussed early in this post. When I commit a shard of my data to a node, the node sees the data, it may not seel all of the data, it sees the unencrypted erasure encoding shard. When I decompose a directory node, the node not only sees but even creates the access token (sparse capability) for that sub directory or file.
Should a L2 mostly be 'just an index' ?
So far I have nothing concrete, just a lot of ideas in my head about how to make things fit. The main goal for this 4th project in the collection would be to test and demonstrate the suitability of the python-CoinZdense/aiohivebot combination not just for simple bots like hive-archeology but also for creating L2 nodes on HIVE.
Then I though about what it would take to implement this base least authority filesystem idea as a L2 for HIVE. CoinZdense would do all of the heavy lifting for subkey management. It would also elevate the confidenciality aspect to post-quantum level. The HIVE L1 would take care of the actual storage of data in the form of custom_json and custom_binary, remember we are not trying to implement a video storage L2. So in the end , most of it would be thinking out the best erasure encoding sharding model that uses an algoritm close to the RumpelTree concept, code linking the monitoring of CoinZdense signed custom json operations for the L2, and a public API.
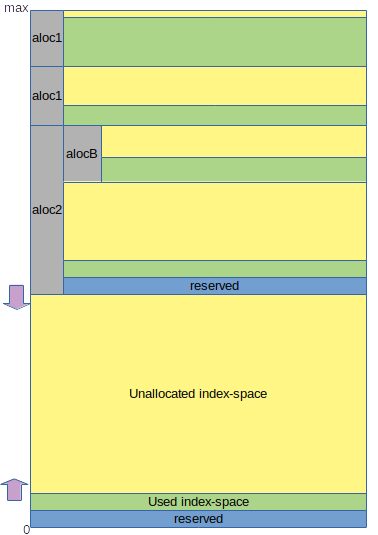
But as far as storage in concerned, with the AES encrypted shards of data in custom_binary or custom_json, with user specific anchors and CoinZdense pubkeys in json_metadata of the account, the actual on-node storage needed seems to just exist of indices pointing to L2 blocks, transactions and opps.
In fact, it pretty much seems to me when I think about it that non-index storage on L2 nodes, at least if the data isn't also on L1, might actualy be an anti-pattern.
So my genuine question to the community and to other devs on here: Should an L2 just be logic and indices? That is, a side chain ofcource should be a side chain that is clear, we don't want to reprocess a huge chunk of the blocks
from the L1 to initialize a new L2 node, but in the end, shout an L2 in terms of storage just be a chain backed index of data on the L1?
But what about an incentive model?
Even with no high storage needs for L2 nodes, running any kind of node just for the fun of it might not be the best of models. Right now I have no incentive model for my idea of a least authority filesystem as an L2 for HIVE. To be fair, incentive models aren't really my cup of tea. I'm not a psychologist, just a book nerd and a tech geek. I absolutely realize that in this day and age, some kind of incentive model would be needed to get people tu run an L2 node.
Because of CoinZdense that I hope to keep blockchain agnostic, I'm hesitant to attach myself too strong to the HIVE blockchain by creating a DHF proposal for development, as it gives of a signal to other chains that CoinZdense is a HIVE project while I hope it not to be, even if its the first ecosystem I am targeting.
For running the code however, a DHF proposal might be usefull if there is no other incentive model we could use.
If I think it through, what I think is missing from HIVE, what is realy missing is a mechnism for L2s to latch on to the RC economy of the L1.
This is absolutely a discussion I would love to see happening.
Can I add this to my list of projects?
As I wrote, I currently have priorities that make it hard for me to work on my existing three projects even now, so should I really be adding a 4th project to the list?
I'll be honest: without people helping me out, either with coding, or by helping partially make my work on these four project give me some financial returns, I don't think I should.
If you want me to work on this idea, next to my other three related main projects, please check out the posibilities to contribute either with donations or check out my merch on demand.
I recently applied for enabling sponsors on my github account to, but that one is still pending.

I hope this page has shown you all a glimpse of my experience and skills, so it should be clear I have the capacity to do these projects, and I would love to do them just for the love of tech, and I will, but at a pace that is frustrating low right now. There is a huge difference between a 4 hours a week project done for the love of tech and a 20 hours a week project that has reliable sponsoring.
So without sponsoring, I should probably not add the idea of a MinorFS/TAHOE-LAFS small-storage L2 for hive as a demonstator. It would be a really interesting test for both aiohivebot and coinZdense, but there is only so much fragmentation that is possible in a few hours a week. But then, maybe this idea, this 4th project, is exactly what my other three projects need to find sponsors for the project.
Quantum computing isn't close to the point where it becomes too late to really act for utility chains and Web 3.0 chains, so my lack of time resources might not be a problem yet. So it makes sense for me to work more on aiohivebot now untill I'm at the point where I can piggyback CoinZdense experiments onto it, and integrate these in a rewrite to aiohivebot of my hive archeology bot.
But again, a personal use bot isn't a L2 and isn't even middleware, its just a personal use bot, so there is only so much the bot would demonstrate.
Regardless of everything though, I would really love some feedbacks on my ideas in this post. So please drop me a response.
For those who don't knopw yet, Ragnarok Conspiracy, my post-cryptocalyptical scifi novel, next to being available on HIVE, is also available for free on most e-book channels as promotional material for my projects. Unfortunatly Amazon is the only channel where I failed to make it free, but you can sideload the mobi file from smashwords. I'm also posting chapters from my earlier book, the novelette Orussian Quarantine on youtube.
So please go and enjoy my fiction, let it resonate as to why my tech projects have value, and if you can spare it, get some merch, use one of the ways to sponsor my projects, or just help me out by liking my content and spreading the word.
You have worked hard to build this project and it is now the responsibility of all of us to support you.
I have been thinking if it is possible to have a separate cloud storage DAPP Chain be developed on HIVE to compete with Sia, Akash, StackOS etc. It will work similar to HIVE-Engine or @vsc.network with easy login for those who already have HIVE accounts.
Congratulations @pibara! You have completed the following achievement on the Hive blockchain And have been rewarded with New badge(s)
Your next payout target is 4000 HP.
The unit is Hive Power equivalent because post and comment rewards can be split into HP and HBD
You can view your badges on your board and compare yourself to others in the Ranking
If you no longer want to receive notifications, reply to this comment with the word
STOPThank you for your witness vote!
Have a !BEER on me!
To Opt-Out of my witness beer program just comment STOP below