
- Introduction to Deep Learning in the Context of Artificial Intelligence
Deep learning is a subfield of artificial intelligence (AI) that focuses on building and training neural networks, which are a type of machine learning algorithm that are inspired by the structure and function of the human brain. Deep learning algorithms are designed to learn from data and improve their performance at a specific task over time, without being explicitly programmed to do so.
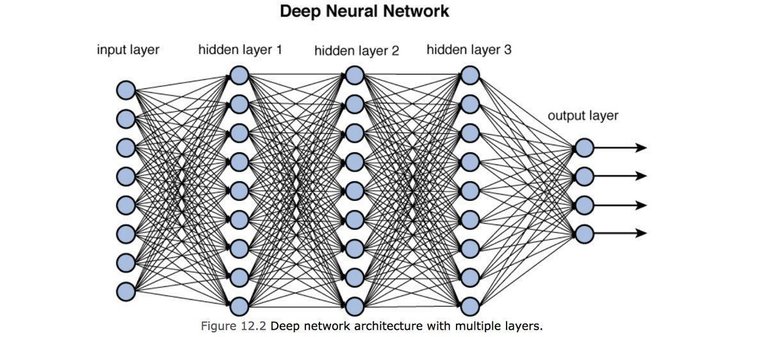
The term "deep" in deep learning refers to the number of layers in a neural network, which can be quite large, sometimes numbering in the hundreds or even thousands. These layers allow the neural network to learn increasingly abstract and complex representations of the input data, enabling it to recognize patterns and make predictions with a high degree of accuracy.
Deep learning has been used to achieve state-of-the-art results in a wide range of applications, including image and speech recognition, natural language processing, and even games like Go and chess. Some of the most well-known deep learning models include convolutional neural networks (CNNs) for image recognition, recurrent neural networks (RNNs) for natural language processing, and generative adversarial networks (GANs) for image and video synthesis.
Despite its many successes, deep learning is still an active area of research, with many open questions and challenges yet to be addressed. Deep learning is a powerful tool for solving many of the most challenging problems in artificial intelligence, and its continued development is likely to have a significant impact on many fields in the years to come.
- Differentiation between 'Deep Learning' and 'Machine Learning'
Deep learning and machine learning are both subfields of artificial intelligence that involve building and training models to make predictions or decisions based on input data. However, there are some important differences between the two approaches.
Machine learning (ML) is a broader category that includes a range of different techniques for building predictive models. In general, machine learning algorithms are designed to learn from data and improve their performance at a specific task over time, without being explicitly programmed to do so. This is achieved by presenting the algorithm with a large amount of labeled training data, which is used to adjust the weights of the model's parameters so that it can make accurate predictions on new, unseen data.
There are several different types of machine learning algorithms, including supervised learning, unsupervised learning, and reinforcement learning. In supervised learning, the training data includes both input features and corresponding labels or target values, which the model is trained to predict. In unsupervised learning, the model is given only the input features and must find patterns or structure in the data without any pre-specified targets. In reinforcement learning, the model learns to make decisions by interacting with an environment and receiving feedback in the form of rewards or penalties.
Deep learning (DL), on the other hand, is a specific type of machine learning that uses neural networks with many layers to learn increasingly abstract and complex representations of the input data. These neural networks are designed to mimic the structure and function of the human brain, and can be quite large, sometimes numbering in the hundreds or even thousands of layers.
The main advantage of deep learning over other machine learning techniques is its ability to automatically extract features from raw data, which can be incredibly useful in fields such as computer vision and natural language processing. In traditional machine learning approaches, these features would need to be manually engineered by experts, which can be a time-consuming and labor-intensive process. With deep learning, however, the neural network can automatically learn these features through the layers of the network, making it much easier to apply machine learning techniques to a wide range of problems.
Another important difference between deep learning and machine learning is the amount of data required for training. Deep learning models typically require large amounts of labeled data to achieve high performance, whereas some machine learning algorithms can be trained on smaller datasets.
In summary, machine learning is a broader category that includes a range of different techniques for building predictive models, while deep learning is a specific type of machine learning that uses neural networks with many layers to automatically extract features from raw data. While there are many similarities between the two approaches, there are also some important differences in terms of the types of problems they are best suited for and the amount of data required for training.
- The Basics - What are Neural Networks?
Neural networks are a fundamental component of deep learning, and are used to model the complex relationships between input and output data. A neural network is composed of interconnected nodes, or "neurons," that are arranged in layers, with each layer processing information from the previous layer. Neural networks are designed to learn from data and improve their performance at a specific task over time, without being explicitly programmed to do so.
The basic building block of a neural network is the neuron, which receives input from other neurons or directly from the input data. Each input is weighted by a specific value, which determines the strength of its influence on the neuron's output. The neuron then applies an activation function to the weighted sum of its inputs to produce an output value, which is sent to the next layer of the network. This process is repeated for each neuron in the network until the final output is produced.
There are many different types of neural networks, each with their own strengths and weaknesses. Some of the most commonly used types of neural networks in deep learning include:
Feedforward Neural Networks: These are the simplest type of neural network, and consist of an input layer, one or more hidden layers, and an output layer. They are commonly used for tasks like image and speech recognition.
Convolutional Neural Networks (CNNs): These are neural networks that are particularly well-suited to image and video recognition tasks. They use a technique called convolution to extract features from the input data, and are commonly used in fields like computer vision and autonomous driving.
Recurrent Neural Networks (RNNs): These are neural networks that are well-suited to processing sequential data, such as natural language text or time series data. They use loops to maintain a memory of previous inputs, and are commonly used in fields like natural language processing and speech recognition.
Long Short-Term Memory (LSTM) Networks: These are a type of RNN that are specifically designed to handle long-term dependencies between inputs. They are commonly used in applications like speech recognition and language modeling.
The training process for a neural network involves presenting the network with a large amount of labeled data and adjusting the weights of the connections between the neurons in the network in response to the errors made by the model. This process is known as backpropagation, and it allows the network to learn how to make better predictions over time. The weights of the neural network are adjusted through an optimization process that seeks to minimize the difference between the predicted output and the actual output.
One of the key advantages of neural networks in deep learning is their ability to automatically extract features from raw data, which can be incredibly useful in fields such as computer vision and natural language processing. In traditional machine learning approaches, these features would need to be manually engineered by experts, which can be a time-consuming and labor-intensive process. With neural networks, however, the layers of the network can automatically learn these features, making it much easier to apply machine learning techniques to a wide range of problems.
Despite their many advantages, neural networks also have some limitations and challenges. One of the biggest challenges is the need for large amounts of labeled data, which can be expensive and time-consuming to acquire. There is also ongoing research into how to improve the interpretability and explainability of neural networks, which can be important for building trust and understanding in applications like healthcare and finance.
Neural networks are a critical component of deep learning, and are used to model the complex relationships between input and output data. They allow deep learning algorithms to automatically extract features from raw data, making it easier to apply machine learning techniques to a wide range of problems. While there are many challenges and limitations associated with neural networks, their continued development is likely to have a significant impact on many fields in the years to come.
- Feedforward Neural Networks
Feedforward Neural Networks (FNNs) are the simplest and most widely used type of neural network, and are often used as a baseline model for more complex neural networks like Convolutional Neural Networks and Recurrent Neural Networks. FNNs are also known as multilayer perceptrons (MLPs).
The basic structure of an FNN is a set of connected layers of neurons, with no feedback connections between the layers. The input layer receives the input data, which is then passed through one or more hidden layers, each consisting of a set of neurons. The output of the final hidden layer is then passed through the output layer, which produces the final output of the network.
Each neuron in the network takes as input a weighted sum of the outputs of the neurons in the previous layer, and applies an activation function to produce an output value. The weights between the neurons in each layer are learned during the training process, using a backpropagation algorithm that adjusts the weights based on the error between the predicted output and the true output.
FNNs are often used for classification and regression tasks, where the goal is to map an input to a set of output values. They have been used in a wide range of applications, such as image recognition, speech recognition, and natural language processing.
One of the main advantages of FNNs is their simplicity and ease of implementation. They require relatively few parameters, making them easy to train and efficient to run on modern hardware. Additionally, their fully connected nature allows them to model complex nonlinear relationships between the input and output data.
However, FNNs also have some limitations. They are not well-suited to handling sequential data, which requires the memory of previous inputs, and may require large amounts of data to achieve high accuracy. Additionally, they may be prone to overfitting, where the model becomes too complex and performs well on the training data but poorly on new, unseen data.
- Convolutional Neural Networks
Convolutional Neural Networks (CNNs) are a type of neural network that are particularly well-suited to image and video recognition tasks. They are commonly used in fields like computer vision and autonomous driving.
CNNs work by using a technique called convolution to extract features from the input image. The convolution operation involves sliding a small window, or kernel, over the image and computing the dot product between the kernel and the image pixels within the window. This process is repeated for each location in the image, producing a new "feature map" that highlights areas of the image that are important for the task at hand.
The first layer of a CNN is typically a convolutional layer, which applies a set of learnable filters to the input image. These filters are designed to detect different types of features, such as edges or textures, and the output of the convolutional layer is a set of feature maps that highlight the presence of these features in the image.
After the convolutional layers, the output of the network is typically passed through one or more fully connected layers, which perform a classification or regression task based on the features extracted by the convolutional layers.
One of the key advantages of CNNs is their ability to automatically extract features from raw image data, which can be incredibly useful in fields such as object recognition and segmentation. In traditional machine learning approaches, these features would need to be manually engineered by experts, which can be a time-consuming and labor-intensive process. With CNNs, however, the filters in the convolutional layers can automatically learn these features, making it much easier to apply machine learning techniques to a wide range of image-based problems.
CNNs have also been shown to be highly effective at transfer learning, which involves using pre-trained models to improve the performance of a new model on a related task. By training a CNN on a large dataset like ImageNet, for example, the features learned by the network can be used to improve the performance of a new model on a different image recognition task.
- Recurrent Neural Networks (RNNs)
Recurrent Neural Networks (RNNs) are a type of neural network that are well-suited to processing sequential data, such as natural language text or time series data. They are commonly used in fields like natural language processing, speech recognition, and image captioning.
Unlike feedforward neural networks, which process each input independently, RNNs maintain a memory of previous inputs, allowing them to model the temporal dependencies between inputs. The basic building block of an RNN is the "hidden state," which is updated at each time step and represents the network's memory of previous inputs.
At each time step, the RNN takes as input the current input and the previous hidden state, and computes a new hidden state and output. The output is typically a prediction of the next element in the sequence, or a representation of the input sequence as a whole.
One of the key advantages of RNNs is their ability to handle variable-length input sequences, making them well-suited to tasks like speech recognition or natural language processing, where the length of the input can vary depending on the task. Additionally, because they can maintain a memory of previous inputs, RNNs can be used to generate sequences of data, such as text or music.
However, RNNs have some limitations, such as the "vanishing gradient" problem, which can make it difficult to train RNNs on long sequences. To address this problem, several variations of RNNs have been developed, such as Long Short-Term Memory (LSTM) networks and Gated Recurrent Units (GRUs), which use gating mechanisms to selectively update the hidden state, allowing them to better capture long-term dependencies.
Recurrent Neural Networks are a powerful tool for processing sequential data, and are widely used in fields like natural language processing and speech recognition. They maintain a memory of previous inputs, allowing them to model the temporal dependencies between inputs, and can handle variable-length input sequences. While they have some limitations, several variations of RNNs have been developed to address these limitations and improve their performance on long sequences.
- Long Short-Term Memory (LSTM) Networks
Long Short-Term Memory (LSTM) Networks are a type of Recurrent Neural Network (RNN) that are specifically designed to address the problem of modeling long-term dependencies in sequential data. They were introduced by Hochreiter and Schmidhuber in 1997 and have since become a widely used and popular neural network architecture for processing sequential data.
The key idea behind LSTM networks is to use a set of gated units, which selectively update the memory cell based on the current input and the previous state. The memory cell is a long-term storage unit that can retain information for a long time, and the gating mechanism allows the LSTM network to selectively store or forget information, depending on its relevance to the current task.
The LSTM network consists of several repeating blocks, each of which contains a memory cell, an input gate, an output gate, and a forget gate. The input gate controls how much of the current input should be added to the memory cell, while the output gate controls how much of the memory cell should be output. The forget gate controls how much of the previous memory should be retained in the current state, and how much should be forgotten.
During training, the LSTM network learns the optimal values for the weights and biases in each of these gates, allowing it to selectively store or forget information based on the task at hand. This makes LSTM networks particularly well-suited to handling long sequences of data, such as natural language text or time series data.
LSTM networks have been applied to a wide range of tasks, including speech recognition, language translation, and music composition. They have been shown to be particularly effective at handling complex sequential data, and have outperformed traditional RNNs on many benchmark tasks.
- Transfer Learning in the Context of Deep Learning
Transfer Learning is a machine learning technique that involves using pre-trained models to improve the performance of a new model on a related task. In the context of deep learning, transfer learning involves taking a pre-trained deep neural network, modifying it, and applying it to a new problem that is related to the original task.
The basic idea behind transfer learning is that the deep neural network has already learned to extract meaningful features from the input data, and these features can be useful for other related tasks. By using a pre-trained model, the new model can start with a set of features that are already optimized for the problem at hand, rather than having to learn these features from scratch.
There are several approaches to transfer learning in deep learning, including:
Fine-tuning: This involves taking a pre-trained model and "fine-tuning" it on a new task. This typically involves freezing the weights of the earlier layers in the model, and only training the weights of the later layers on the new task.
Feature extraction: This involves using the pre-trained model as a fixed feature extractor, and training a new model on top of these features to perform the new task. This approach is particularly useful when there is limited labeled data for the new task.
Multi-task learning: This involves training a single model on multiple related tasks, allowing the model to learn common features that are useful for all of the tasks. This approach can be particularly useful in settings where there is limited labeled data for each task.
Transfer learning has several advantages in the context of deep learning. First, it can greatly reduce the amount of labeled data required to train a new model, since the pre-trained model has already learned to extract meaningful features from the input data. Second, transfer learning can improve the generalization performance of the new model, since the pre-trained model has already learned to extract features that are useful for a wide range of tasks. Finally, transfer learning can save time and resources, since it avoids the need to train a new model from scratch.
However, there are also some limitations and challenges associated with transfer learning. One of the main challenges is selecting the appropriate pre-trained model for the new task, since different models may be better suited to different types of data or tasks. Additionally, the new task may require modifications to the pre-trained model, and there may be a risk of "overfitting" to the pre-trained model, rather than learning the features that are specific to the new task.
- The Benefits Associated with Deep Learning
Deep learning has several benefits that have made it a popular and powerful tool for a wide range of AI applications. Some of the key benefits of deep learning are:
Improved accuracy: Deep learning algorithms can learn to automatically extract features from raw data, making them highly effective at complex tasks like image and speech recognition. This can lead to significant improvements in accuracy compared to traditional machine learning methods.
Scalability: Deep learning algorithms are highly scalable and can be trained on massive datasets. This makes them well-suited to big data applications, where large amounts of data are available for training.
Flexibility: Deep learning algorithms can be applied to a wide range of tasks, from image and speech recognition to natural language processing and game playing. This makes them a versatile tool for solving a wide range of AI problems.
Automatic feature extraction: Deep learning algorithms can automatically learn to extract meaningful features from raw data, without the need for human expertise in feature engineering. This can save a significant amount of time and effort in developing AI systems.
Transfer learning: Deep learning algorithms can be used for transfer learning, allowing a pre-trained model to be fine-tuned or adapted for a new task. This can reduce the amount of data required for training, and improve the accuracy of the new model.
Real-time processing: Deep learning algorithms can be designed to process data in real-time, making them well-suited to applications like autonomous vehicles, where real-time decision-making is critical.
Overall, the benefits of deep learning make it a powerful tool for a wide range of AI applications, and its ability to automatically learn to extract meaningful features from raw data has the potential to revolutionize many fields. However, there are also challenges associated with deep learning, such as the need for large amounts of data and computing resources, and the potential for overfitting and other performance issues. Nonetheless, the benefits of deep learning have made it a popular and rapidly advancing field within AI research and development.
- The Risks Associated with Deep Learning
While deep learning has many potential benefits, there are also several risks and challenges associated with its use. Some of the main risks of deep learning include:
Overfitting: Deep learning models are highly flexible and can be prone to overfitting, where the model learns to fit the training data too closely and does not generalize well to new data. This can be particularly problematic when working with small datasets, or when training on noisy or unrepresentative data.
Lack of interpretability: Deep learning models can be difficult to interpret, making it hard to understand how the model is making its predictions. This can be particularly problematic in fields like medicine, where it is important to understand the reasoning behind a diagnosis or treatment recommendation.
Bias: Deep learning models can be biased, reflecting the biases in the training data. This can result in discrimination against certain groups, or inaccurate predictions for certain types of data.
Robustness to adversarial attacks: Deep learning models can be vulnerable to adversarial attacks, where an attacker intentionally modifies the input data to cause the model to make incorrect predictions. This can be particularly problematic in security-critical applications like self-driving cars.
Data privacy: Deep learning models can be trained on sensitive data, raising concerns about data privacy and security.
Computational requirements: Deep learning models can require significant computational resources, including high-performance computing systems and specialized hardware like GPUs. This can make it difficult or expensive to train and deploy deep learning models in some settings.
Overall, the risks associated with deep learning highlight the need for careful consideration and evaluation of its use in different applications. Researchers and developers must be mindful of the potential risks and take steps to mitigate them, such as carefully selecting training data, evaluating models for bias, and implementing security measures to protect sensitive data. By addressing these risks, deep learning has the potential to unlock many new and exciting applications in fields like healthcare, finance, and autonomous systems.
- Some Applications Employing Deep Learning in the Context of Artificial Intelligence
Deep learning has a wide range of applications across many different fields of artificial intelligence. Some of the key applications of deep learning include:
Computer vision: Deep learning is particularly well-suited to image and video recognition tasks, such as object detection, face recognition, and video analysis. Deep learning algorithms can automatically learn to extract features from raw image and video data, and can achieve state-of-the-art performance on many benchmarks.
Natural language processing: Deep learning is also widely used for natural language processing tasks, such as language translation, sentiment analysis, and speech recognition. Deep learning algorithms can learn to automatically extract features from text data, and can achieve high accuracy on many language-related tasks.
Autonomous systems: Deep learning is a key technology for developing autonomous systems, such as self-driving cars, drones, and robots. Deep learning algorithms can be used to process sensor data in real-time and make decisions in complex, dynamic environments.
Healthcare: Deep learning is increasingly being used in healthcare applications, such as medical image analysis, drug discovery, and disease diagnosis. Deep learning algorithms can analyze large volumes of medical data, including images and patient records, and can help doctors make more accurate diagnoses and treatment recommendations.
Finance: Deep learning is also being used in finance applications, such as fraud detection, stock market prediction, and credit risk assessment. Deep learning algorithms can analyze large volumes of financial data and identify patterns and trends that can help inform decision-making.
Gaming: Deep learning is being used in gaming applications, such as game playing and game design. Deep learning algorithms can learn to play games like chess and Go at a superhuman level, and can be used to generate new game content and experiences.
Overall, deep learning has many applications across a wide range of fields, and its ability to automatically learn to extract features from raw data has the potential to revolutionize many industries. By continuing to advance the state-of-the-art in deep learning, researchers and developers can unlock many new and exciting applications of artificial intelligence.
- Conclusion
Deep learning is a rapidly advancing field of artificial intelligence that has the potential to revolutionize many industries and applications. Deep learning algorithms can learn to automatically extract meaningful features from raw data, allowing them to achieve state-of-the-art performance on tasks like image and speech recognition, natural language processing, and autonomous systems.
While deep learning has many potential benefits, there are also risks and challenges associated with its use, such as overfitting, lack of interpretability, bias, adversarial attacks, and data privacy concerns. By addressing these challenges and continuing to advance the state-of-the-art in deep learning, researchers and developers can unlock many new and exciting applications of artificial intelligence, and help to create a more intelligent and connected world.
Posted Using LeoFinance Beta
That was actually interesting, I wanted studying data analytics and I understood I will come across ai systems.