Easy storage and retrieval of information or documents, I agree, is very ineffective when managed by a file / folder type of means. But, before shooting headlong into blockchain or AI, most use cases can be effectievly handled with less exotic tooling, like a document management system (database in front of the information / documents) or a NoSQL front.
Blockchains strengths lie in being trustless. For information or document retrieval, it may work at small volumes, but not when it reaches any significant level, even for a small business - compared to a Doc management system or key-value store (NoSQL). And it boils down to being ACID compliant within milliseconds and plus quick recovery, which blockchains are not. A whole host of problems arise without data, or documents, being ACID.
AI... better for creation in areas like marketing, while not so good for discrete, repeatable, auditable, provable and legally compliant proof of record.
So, what makes documents, information easy to find or discover? Part of that answer is it has to be fast. So far, I haven't seen an indexing solution that out performs a database or key-value store. So why not use them? And AI... no. I'm not bashing AI, in fact it has a ton of uses, but for discrete document or info storing and retrieval, especially for financial applications, there's long proven, effective ways that serves us well.
So, why can't people find "stuff"? They simply don't use a tool and insist they should just be able to throw information any dam where they please. Then, some magical, all access bot, should scoop it up and add it to a neural network, train it at $1,000 an hour so you can hire a "prompt artist" to concoct magical phrases to extract a semblance of the data, dripping in a trendy designer layout... uh, yea.. right.
This is the part where you chuff, bow out your chest, cross your arms and screech, "OK, smarty pants... how would YOU do it?" TO which one simply replies "Settle down... Francis..." and show examples:
Any piece of info, receipt, user manual, article I store into document management. It could be an image, hyperlink, pdf, audio, video, etc and tag it by group, type and description. One place to store and look for any and all types of info, like this showing some of my crypto notes

But that's not the trick - the trick is... you have to be able to handle EVERYTHING, which is not a problem as I also store calendar appointments, stock tickers, receipts, legal docs, tax filings, maintenance schedules, programming notes, health info, home and garden, employment records, retirement rules, computer specs, ...
Here's just a few of those categories that store computer info (helps when I build rigs out)
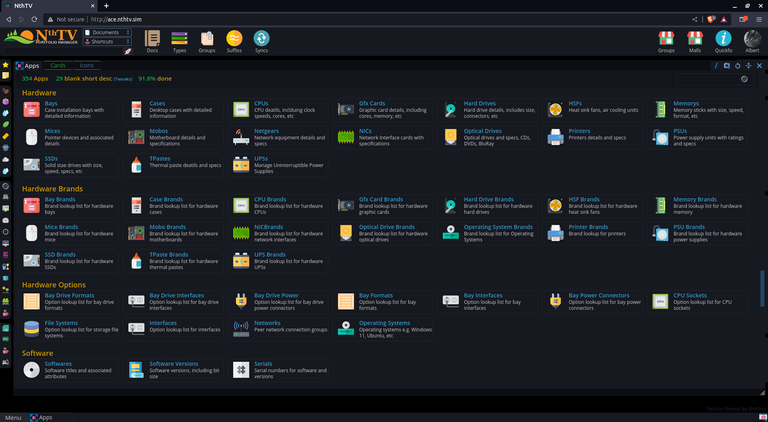
Just thought to shine light on some old skool software that's hellish performant and strong like bull. Me.. luddite? Nah, I'm adding AI interface to it currently... after all, it's go to be everything...
There are plenty of DMSes, none of them do the job well enough at this point.
This is why I mentioned "pseudo" blockchain. It doesn't have to be a blockchain, just resemble components of it. No company wants their data immutable.
I don't think you understand the complexity of the problem at scale. We are talking about globally distributed organizations, handling hundreds of millions of documents yearly, localized legal models, external collaboration, multiple repositories, complex user access models and then, automation based on the changing information within the documentation. It isn't simple storage and retrieval.
However, what does work is using a database or key value store similar to what you are using (based on your screenshots) as the "blockchain" of references. Then it doesn't matter where the information is actually stored, as they are all linked to the timeline backbone, including the versions, which at an interface level can appear as a single document.
This allows people to throw information wherever they want and as long as it is appropriately labelled at that point (done automatically or user-defined), it will be allowed to join into the stream.
"One place" just doesn't work at enterprise level for so many reasons. One of them is of course that human data hygiene is terrible. One of the others is just the practicality across quite different tech stack needs based on department usecases.
Enjoying the solution ideas. And if you don't mind me with additional foods for thought...
References are fine within an entity, as there's control and knowledge over it's availability and existence. But linking in any other case, I'm gunna balk.
It's all good and fine when all linked systems are up and behaving, but one broken or unavailable reference can degrade validity quick. If every document or info isn't available 100% perfectly all the time 24x7x365, else there's that inevitable finger pointing shootout scene, when there's data that needs to be produced and it's either incomplete or late. Other people's / department's / company's systems ALWAYS go down when you need them most - that I learned from trading... nah, it's always been true.
However, federate it into "one place" and you have reproducable results and control over the data, even if transient. 100 million documents.. decent sized, doable.
I prolly sound jaded, but having been called into meetings and seeing Bob blaming remote Jane blaming remote Sally, ad infinitum, gets old fast. I've personally witnessed it in airlines, electrical grid systems, all the way down to daycare, schooling, local govts...
None of the DMs do the job well enough? At 100 million documents I wouldn't suggest a third party solution - coder up.. way cheaper, faster and functionality out the wazoo.
One place just doesn't work for a global corporation, as there are localized laws that prevent it.
I am sure it does. I have gone into these companies too, and trained them on solutions that do work at scale :)