We discussed Hive as a database. When it comes to decentralized text storage, Hive is rather unique.
In an era where data is so important, we are residing in a world where the flow is controlled. Web 2.0 is structured in a way where a handful of companies control most of the data. Access to the database, especially to write, is only granted with permission.
This is evident in the fact that accounts are controlled by the companies behind the platform. Banning is still fairly common. This can come without warning. What makes the situation worse is that, once this happens, not only can the database not be written to but older information is no longer accessible.
One is completely cut off.
Here is where Web 3.0 offers a different solution.
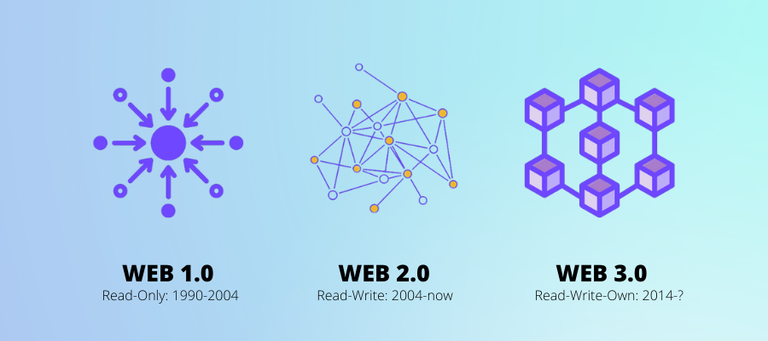
Data In An AI Era
We all have seen images similar to the one above.
This depicts the progress the Internet went through. Initially we were dealing with something static. This was the read era. With the advent of social media, comment sections, and forums, we entered read-write. now, with Web 3.0, tokenization leads to ownership.
It is something that is important for a variety of reason.
To start, in a digital era, cancelling an account is akin to killing someone's digital life. Their entire online existence, whatever that might be, is gone in an instant. All connections, works, and years of engagement is gone.
It is as if the person (digital) never existed.
Then we also have the atypical freedom necessary to combat not only censorship but tyranny. There are many parts of the world where speaking freely could get one imprisoned, or worse. Independent journalists around the world can face some harsh conditions for reporting on things such as genocide or corruption.
In my view, as important as these are, they pale in comparison to what we are entering.
With the progress into artificial intelligence, it is crucial that we start to consider the need to have data that is not under the control of the major entities. There is a reason why Big Tech is dominating the sector. Naturally, the requirement for massive compute is one of the reasons. However, it is also essential to have a massive amount of data. Companies like X, Google, and Facebook (Meta) have this.
Most starts ups and smaller entities are left out in the cold on this one.
Here is where Hive could offer an alternative. Actually, anything that is posted to permissionless blockchains are part of this battle.
Hive's Capacity
What is the capacity of Hive as a database?
This is something that is a major question throughout the entire blockchain spectrum. When it comes to scaling, we are finding an area that most have concern about.
Hive is no exception.
Fortunately, this was a concept since the blockchain went live. Steps are repeatedly being taken to ensure we can handle a larger amount of data. This is going to be vital because all the capacity is eventually going to be needed. The creation of data is not slowing down.
In other words, all the bandwidth that is out there will be utilized.
So what can Hive handle?
We gained some insight from the most recent core developer call.
The team is testing out the capabilities of larger blocks to be prepared. For now, we are still using 64K block sizes, with plenty of room to spare. This is not likely to always be the case.
When the blockchain was designed, the max size was set at 2MB. There were tests done occasionally to see how it would perform. Recently, more were done with a focus on how the Hive application Framework (HAF) would perform.
This is from the transcript:
And we needed to make sure that it could also handle those larger box and Bartek told me today that the test they've done so far seemed to indicate we're not going to have a problem there either so that's. And I mean without even any making any, I think any adjustments to half itself in just the code as it currently is operating was able to operate live sync with two megabyte size blocks being sent out in the test net situation. I think that's extremely positive.
So what does this mean for capacity? Here is how it was explained:
You know, we'll still be doing some more testing but I think we're on the right track there so we have lots of headroom I mean just to put that in perspective, a two megabyte block is about 30 times larger than current blocks so that's if we're not filling up our normal blocks right now at 64 K we have plenty of headroom on that on that side now.
According to Blocktrades, we are dealing with a 30x increase. This is a significant jump. Whether there is a 1:1 correlation in throughput is unknown to me. However, the point is clear: we have plenty of room to add more data to the chain with the buffer of larger block sizes.
For now, there is no need to alter the size since we are still operating without issue as is. The key is that, when needed, the capacity is there.
Of course, when it comes to network efficiency, there is a lot more than just storage space. Nevertheless, this is a simple metric telling me we have a lot more room.
The AI Race
It is hard to dispute there is an AI arms race taking place.
Each week, it seems as if a new technology player has another announcement or upgrade that advances things. While this could slow down, it seems we entered a new era of development.
This is putting everyone at a crossroads.
The question of how we best proceed is being discussed. Some feel this technology is too powerful to allow in the hands of anyone. This leads to the conclusion that closed models are best. On the flip side, some believe that it is too powerful to have in the hands of any one government or corporation. The view here is nobody can be trusted to this degree.
For me, I believe having as much out there is the best defense. We know that corporations and governments can become corrupted (if not already). Big Tech has given us no reason to trust them based upon the last few decades. Naturally, the same is true of governments.
Hive is a miniscule player in the online world. That said, it does have a powerful characteristic: a decentralized, permissionless text database without any direct transaction fees.
It seems, in this era, that is becoming more important.
As we progress forward, it is uncertain when we will need the additional capacity but it is good to know it is there when we need it.
According to the numbers we have, a 30x increase in throughput size is possible.
Posted Using InLeo Alpha
64kB * 32 = 2MBbut that is just a block size limit. What was actually tested is 180 to 200 times more traffic than we normally have on mainnet. And whole stack at that. The python script prepares transactions, signs them with BeeKeeper, sends them to API node (which was also block producer), then that communicates with HAF node that consumes incoming blocks and fills up database - all on single computer. That's way more work than a server with a node would be doing in normal environment.Before that, the
silent beeguy that prepared the script (can you imagine working on Hive and not even having Hive account? most people on the team are like that 😡) accidentally tested old AH RocksDB, because he forgot that test-tools add it to configuration by default (it didn't make much difference in performance with or without it). Before first test on HAF was done, the expectation was that it will break on first big block due to size of SQL code produced by serializer to be processed in single SQL transaction. Turned out that not only serializer does not dish out as much data as assumed, PostgreSQL can handle orders of magnitude more (according to its documentation). That was very positive surprise.Because in normal environment you'd not have all the work of whole network done on single computer, the test is not fully reflecting our limitations (we can do more). I also have some objections on the transaction mix the script produces. It dishes out 3-4k transactions per block and not very consistently due to all the extra work. That's why in the meantime I've made colony plugin that can skip most of the extra work and because of being run inside the node, can be smart about its production rate. We've run tests with it too, although not with HAF yet, since the plugin is not yet merged into
develop, which makes it harder to include in HAF build stack. Because it skips some steps (f.e. it is not limited by API) and is easier to configure than script (and was actually configured to reflect transaction mix closer to that of mainnet), during test it consistently filled 2MB blocks with around 7250 transactions per block. This is where we run into some limitations. First, the p2p plugin has a one-minute deep limit per peer that does not allow for more than 1000 transactions per second. Of course we've continued testing with that limit increased hundredfold (and also separately with 4 concurrent nodes with colony enabled to see if it will work without touching the limit, if we just spread the load between multiple peers, which is what you'd expect in normal network setting). There is some other limit in p2p still that I didn't have time to identify, because we've also tested with 30k transactions per block (you can fit that many when those are minimal transactions "signed" with accounts that use open authority, that is, require no signature - only useful to test influence of number of transactions, won't ever happen in real life). It works as long as it is all on single node, but when colony is run on one node and the other node is a witness, the p2p communication (even after limit per peer was increased) is still choking somewhere.At the moment I'm pretty confident that not only the 2MB blocks are no challenge, we can still increase performance (and then use that buffer to implement some aggressive memory optimizations, so in the end we will work at around the same pace but with less RAM consumed). The question is if we actually decide to do it, and if so, whether there will be enough human resources to complete the task. I've recently added a meta issue with my wish list for hived (@taskmaster4450 it contains bonds, although not quite like you've described them 😉).
Thanks for the write up. I only went based upon what Blocktrades said with the 30x, not presuming that it was a 1:1 increase in the throughput. Obviously, block size is only one factor and, as you detailed, there are many more being worked upon.
It is good that you have the 180x on the traffic during testing. That is very positive. Scaling is something that so many are focused upon, often after bottlenecks. It is good to see what is going on before Hive is full.
I will take a look at the wish list, especially the bonds. Perhaps another article will result.
What a nice write-up by you @taskmaster4450
I have come to know that Web 2.0 is structured in a way where a handful of companies control most of the data which occurs because of the fact that accounts are controlled by the companies behind the platform.
I have also known that in a digital era, cancelling an account is akin to killing someone's digital life and also that With the progress into artificial intelligence, it is crucial that we start to consider the need to have data that is not under the control of the major entities. Well hive wasn't left out as well as you said that The team is testing out the capabilities of larger blocks to be prepared.
This was a nice thoughtful write-up, I really Appreciate your efforts in this article
It's awesome to see the Hive blockchain getting future proofed, but we need to start filling up those 64 kb blocks.
Reading that we are only using a small amount of our max block size is very encouraging. The results of the testing is important and shows that we can handle it. That is perfect for this bull run. If we get more users and activity, this will help with the additional traffic.
And as layer 2 solutions grow on Hive, I would imagine some of what is being put on layer 1 now will move to layer 2, which would free up space on layer 1 as well.
Certainly that could be the case. Not everything has to go on the main chain.
Let's keep growing, the future is great. Let's keep adding more data and apps.
Hive surely has many possibilities and I think in web3 and its progress meter on, there are more things to grab and we might see it happen.
Lets think of the time it took from web1 to web3 and with it the added infrastructure that was kept to be building on. Data played the central part of it and how it is handled and used to build database to help the ecosystem grow.
Such reshapes create a better blockchain technology and I hope it prospers too with it.
Hive has the infrastructure supporting such an incremental scale and I think that we will put that to test in the following period considering the latest developments. And here I speak about VSC Network which will allow new types of use cases, dapps and businesses to be created.
There are many who are focused upon it. Scaling is something that many on the main team have put forth as their major area of concentration.
I did not think we'd even be able to deal with the 65KB limit we have now.
Interesting to see that 2MB is even being considered.
I think it is a backburner type thing. It is there when needed and will be thoroughly tested but will not be rolled out until it is required. If not filling up 64KB, why push the other is my view.
RC cost of transactions can go up a lot. Congestion just puts a bomb under the price of Hive/HP :)
It does. That is the ultimate buy demand that HIVE has. And this can keep expanding.
30x increase!
An easy-to-remember brief description of Hive: decentralized, permissionless, and feeless.
In throughput, it is actually more as the first comment details.
Key take away is the fact that hive is the only text database for web 3 at the moment. I have searched and not found any other web 3 platform pushing social media like hive. With this in mind i have started my research to make some projects with hive to solve problems in my personal and work life
!BBH I am always rooting for Hive. Leave the centralized tyranny eating our dust.
Your Content Is Awesome so I just sent 1 $BBH(2/5)@taskmaster4450! (Bitcoin Backed Hive) to your account on behalf of @fiberfrau.
It is nice to know we have the capacity to grow and add more and more data.
So much better to have it available whether or not we need it yet.
Discord Server.This post has been manually curated by @steemflow from Indiaunited community. Join us on our
Do you know that you can earn a passive income by delegating to @indiaunited. We share more than 100 % of the curation rewards with the delegators in the form of IUC tokens. HP delegators and IUC token holders also get upto 20% additional vote weight.
Here are some handy links for delegations: 100HP, 250HP, 500HP, 1000HP.
100% of the rewards from this comment goes to the curator for their manual curation efforts. Please encourage the curator @steemflow by upvoting this comment and support the community by voting the posts made by @indiaunited.
Data is now a priority especially in this present age. Whether we have data or not we will need it