WIth the release of Deepseek, the markets were shook to the core. Stocks such as Nvidia were slaughtered, a massive sell off fueled by the belief that billions of dollars were being wasted on GPUs. Many across the AI world started conversing about this, whether this was the "ChatGPT destroyer".
LIke many beliefs, things were greatly misplaced. None of this is true. In fact, the opposite has far greater probability.
We have to start with the fact that this move by Deepseek was not unexpected. It is actually in keeping with the trend already established by other AI models. The amount of compute required to train a GPT2 level model is vastly lower than what was used originally.
With the advancement of processors, algorithms, and data labeling, we are seeing things compressed. Basically, being a year behind is roughly the norm.
The only thing Deepseek did was accelerate the step forward with regards to the efficiency. By some metrics, this model was already surpassed by OpenThinker.
In this realm, if you do not like something, wait a few weeks...it is bound to change.
Image generated by Grok

Deepseek Improvements Only Pushes The Need For More Data Centers
As stated, these improvements will only require more GPUs. Hence, the development of a lot of data centers is required.
How is this the case if things are getting more efficient?
The answer to this stems from Jevon's Paradox. Essentially, it boils down to the idea that as something is improvement, more of it is used, not less. The computing world is full of examples. We see this with semiconductors, cloud compute, and, eventually, generative AI.
Right now, we see training compute get the attention. This is what Deepseek was all about. It used less compute along with requiring less training examples than the LLMs. OpenThinker took this to another level, knocking the examples from 800K to 144K.
What gets overlooked in all this is the amount of compute that will be needed in the future for inference. Each time something is prompted, compute is necessary. While training can utilize vast amounts of compute, as more people use the products tied to these models, the inference will explode.
We are going to see the costs associated with this dropping over time. Here is what OpenAI o3-mini looks like.
Source

As stated, we are dealing with a trend here. This is how things have changed over the past few years.
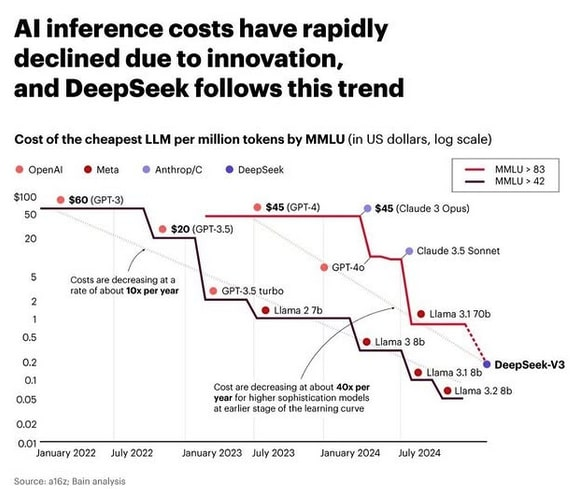
To put it in basic terms. mass adoption cannot occur with the token prices for the o3-mini. These numbers have to drop a great deal more.
This is exactly what is going to happen over the next few years.
The move by Deepseek will bot be the last one we see. A lot of changes will occur as both LLM and SLM advance.
It is the nature of technological evolution.
Posted Using INLEO
Someone told me that DeepSeek uses compression and decompression of data strategy to save resources somehow.
That could be. I didnt look at it closely. From people I do follow (and trust) on this stuff, they said there were architecture designs that resulted in greater efficiency.
What has happened to me with DeepSeek is that I have lowered its rating as I have used it more in-depth. The positive thing about its irruption is that, as you have expressed here, it drives forward innovation and the generation of more cutting-edge solutions. I have been doing some programming comparing the performance of DeepSeek and ChatGPT and the latter has been more efficient. However, I note that it is a particular experience without so much computing demand involved. I have been busy and just with your post I know about OT. I will try it ASAP. Thanks.
Congratulations @taskmaster4450le! You have completed the following achievement on the Hive blockchain And have been rewarded with New badge(s)
Your next target is to reach 3800 posts.
You can view your badges on your board and compare yourself to others in the Ranking
If you no longer want to receive notifications, reply to this comment with the word
STOPI think this competition will drive continuous improvements so ultimately the demand for resources will continue to rise.
The architectural designs of the past, I have always liked them, as they were made with a lot of talent. Very good publication.
https://inleo.io/threads/view/omarrojas/re-leothreads-2dhu6dxuw?referral=omarrojas