Introduction
While preparing some future posts, I found myself collecting data from a few different APIs. Each script had its own API-fetching function, but much of the fetching logic overlapped. In one case, the script needed to pull data from two servers, which led me to realize the need for a flexible and reusable solution — one that could handle all scenarios using the same code.
So in this post I'll explain a JavaScript Class I developed and highlight its main components. I published the code to GitHub here, and I added a couple of working examples to showcase the Classe's usage. The initial examples are:
Fetch the title and cover image of a Hive blog post (using the 'POST' method);
Fetch Gods Unchained game data: list of game modes, list of Sealed games and list of games for a specific player and game mode.
I'll be adding more usage examples as I post more articles that make use of data obtained from (mostly) the Gods Unchained APIs.
Main features
I started with a simple logic with the objective of handling multiple servers and multiple endpoints for 'GET' requests. I wanted to dynamically create the URL and any necessary connection components (headers, connection method, parameters) from settings that could be different for each particular request. So I organized everything in an object that includes all the servers, endpoint configurations, and any other settings required for the connection.
Since each individual request needs to have its own parameter values, I needed a way to assign values on the fly. After considering a few alternatives, wrapping everything in a Class with getters felt like the cleanest solution.
Then, I started building additional features: I added error handling / retry logic and rate limit controls. Finally, I introduced code to enable fetching data using 'POST' requests to support the Hive API. All in all, this Class incorporates the following features:
Asynchronous request queue to manage simple, one-off tasks
Unified handling of both GET and POST requests
Support for multiple servers and customizable endpoints
HTTP error detection and handling
Support for custom headers when necessary, including authentication keys
Per-server rate limiting using a token bucket algorithm
Automatic retries with exponential backoff on failure
Calculation of the 5-seconds rolling request rate, per server
Doesn't require any external modules
Supports TypeScript
There is at least one useful feature I left out: there is no coordination of rate limits across multiple concurrent processes targeting the same server. My understanding is that this would require something like Inter-Process-Communication (IPC) or a proxy server, but that is beyond the scope of this solution.
Code highlights
As a template of sorts, here is the configuration for the CoinGecko server, including two endpoints:
this.APIendpoints = {
'https://api.coingecko.com': {
rateLimit: 5,
rateHistory: [],
currentTokens: 5,
method: 'GET',
headers: { 'x-cg-demo-api-key': CGapiKey },
endpoints: {
current_coin_price: {
pathname: `api/v3/simple/price`,
searchParams: {
get ids() { return self.params.ids },
get vs_currencies() { return self.params.vs_curr }
}
},
historical_coin_price: {
get pathname() {return `api/v3/coins/${self.params.coin}/history`},
searchParams: {
get date() { return self.params.date },
localization: false,
}
}
}
},
The API request is submitted like:
const priceGODSdate = await apiManager.fetchAPIData('historical_coin_price', { coin: 'gods-unchained', date: dmy });
So without touching the fetch function, you can fetch data for any coin you need and in the case of historical prices, any date as well. The getters are resolved when the URL is 'assembled', in this function:
// Build the URL for each request
#buildURL = (targetEndpoint) => {
for (const [baseURL, params] of Object.entries(this.APIendpoints)) {
if (params.endpoints[targetEndpoint]) {
const url = new URL(baseURL);
url.pathname = params.endpoints[targetEndpoint].pathname;
for (const [key, value] of Object.entries(params.endpoints[targetEndpoint].searchParams)) {
if (value) url.searchParams.append(key, value);
}
//console.warn(url.href);
//process.exit(0); // for debugging
return url;
}
}
console.error(`FATAL: Endpoint ${targetEndpoint} not found.`);
process.exit(1);
}
Similarly structured functions build the headers and the body, when those settings are present for the endpoint. This allows handling both 'GET' and 'POST' requests implicitly - the presence of the necessary keys in the configuration object this.APIendpoints determines what gets added to the HTTPS request. This solution also accommodates 'POST' requests - including those that mix 'body' and URL parameters.
I suppose this implementation could be even more flexible for certain cases, but the current version already goes beyond my requirements when using the tool - for example, it allows both 'POST' and 'GET' requests to the same server in different endpoints, which I currently have no need for. If some future situation cannot be handled by the current code, I will try and make the necessary modifications to handle new cases. In the meantime, if you know a typical case that is not currently being handled correctly, please do reach out in the comments.
The server's rate limits are respected using a bucket algorithm that refills every second. This may still allow for burst requests in some situations, which some servers may not like. But for my use cases that doesn't seem to be a problem, and I am using asynchronous queueing that waits for a request to be completed before sending the next one. So I don't think a more sophisticated algorithm is necessary. The pause mechanism consists of waiting for an event emitted every time the tokens are replenished.
// Rate limiting via token bucket algorithm
#refillBuckets = () => {
this.bucketsID = setInterval(() => {
for (const params of Object.values(this.APIendpoints)) {
params.rateHistory.push(params.rateLimit - params.currentTokens); // Just for calculating and reporting the request rate
if (params.rateHistory.length > 5) params.rateHistory.shift(); // Remove oldest count
params.currentTokens = params.rateLimit;
}
this.refillEmitter.emit('refill');
}, 1000);
}
#waitForRefill = () => {
return new Promise(resolve => {
this.refillEmitter.once('refill', resolve);
});
};
This rate-limiting function also records the data needed to calculate the rolling 5-second request rate. The rate is calculated on demand when requested via this next function. The time interval can be adjusted by simply changing the '5' in the previous function to any number you prefer.
// Calculate and expose the request rate for a given endpoint / server
requestRateFor(targetEndpoint) {
for (const params of Object.values(this.APIendpoints)) {
if (params.endpoints[targetEndpoint]) {
const rollingRequestRate = params.rateHistory.reduce((sum, count) => sum + count, 0) /
params.rateHistory.length;
return rollingRequestRate.toFixed(1); // Trim to 1 decimal place
}
}
console.error(`FATAL: Endpoint ${targetEndpoint} not found.`);
process.exit(1);
}
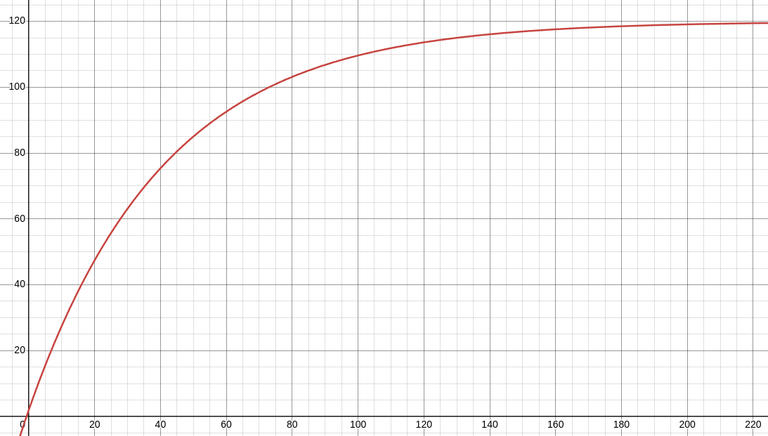
The error handling and timeout logic is pretty standard, so I'm skipping that. The final component I would like to highlight is the formula to calculate the delay (in seconds) between retries, while making the delay asymptotically approach a maximum of 120 seconds. This helps throttle repeated requests after failures without overloading the system or introducing excessive delays.
// Exponential backing off function to calculate the delay between API requests
#expDecayDelay = (retry) => {
const delay = 2 + (120 - 2) * (1 - Math.pow(1.5, -0.06 * retry));
return Math.round(delay);
}
Below is a graphical representation of the delay formula, which produces a saturating exponential curve. The delay increases rapidly during the first few retries, allowing for quick recovery from transient errors. But then it levels off near the maximum - if a connection problem persists beyond the first few retries, further increasing the delay doesn't offer much of a benefit.
I'm using this code for my own stuff and I'm happy to share it, hoping someone else would find it useful, too. Let me know if you're using it!
And as always, thanks for reading!

The rewards earned on this comment will go directly to the people( @agrante ) sharing the post on Reddit as long as they are registered with @poshtoken. Sign up at https://hiveposh.com. Otherwise, rewards go to the author of the blog post.
It's great to build programs to solve personal problems or automate problems and it's even cooler to share them! Great post
Thanks!
!PIZZA
$PIZZA slices delivered:
(1/5) @agrante tipped @gabrielr29
Moon is coming - April 19th, 2025