In my post a week ago over here I have been giving you an update on Hive-Engine light nodes, snapshots and some other developments regarding engine nodes.
In this post I will be talking about engine node snapshots, which play a substantial role in the operation of the Hive-Engine sidechain.
Creating Snapshots
I am providing a snapshot service for engine nodes since approx. a year now. What it basically does is create a snapshot (backup) of an engine node once a day, so it can be used to set up new nodes or restore faulty or forked nodes. A few months ago I have additionally added snapshots for light nodes, which are created every 12 hours.
The backup is basically done by creating a dump of the whole mongo database. More specifically a cron job executes a shell script once a day (or twice for light nodes), which:
- Stops the node
- Checks for divergence
- Deletes old snapshots
- Creates the mongo dump
- Checks for success
- Uploads to file server
- Restarts the node
If you are curious, here is the full script for creating the backups:
#!/bin/bash
# directory of engine node
nodedir="/home/user/steemsmartcontracts"
# file server directory containing snapshots
snapshotdir="/var/www/html/snapshots"
# for creating snapshot before moving to file server
tmpdir="/tmp/snap"
cd "${nodedir}"
# check if node is running
isrunning=`pm2 status | grep online`
if [[ -z "$isrunning" ]]; then
echo "Node is not running"
exit 1
fi
echo "Node is running"
# unregister node (if witness enabled) and stop
node witness_action.js unregister
pm2 stop app
sleep 15
# check if node is in valid state (not divergent)
node find_divergent_block.js -n https://api.primersion.com >> find_divergent_block.log
isok=`tail -1 find_divergent_block.log`
if [[ "$isok" != "ok" ]]; then
echo "Node is divergent"
exit 1
fi
echo "Node is all good and not divergent"
# delete snapshots older than 1 day
find "${snapshotdir}/" -mtime +0 -type f -delete
sleep 30
# dump database
now=`date +"%m-%d-%Y"`
start_epoch=`date +%s`
block=`cat config.json | grep startHiveBlock | grep -Eo '[0-9]*'`
mongodump --db hsc --gzip --archive="${tmpdir}/hsc_${now}_b${block}.archive"
# check if dump was completed successfully
issuccess=`tail -10 daily-snapshot.log | grep "done dumping hsc.chain"`
if [[ "$issuccess" != *"done dumping hsc.chain"* ]]; then
echo "mongodump not successful"
exit 1
fi
echo "mongodump was successful"
sleep 30
# move to fileserver
mv "${tmpdir}/hsc_${now}_b${block}.archive" "${snapshotdir}/hsc_${now}_b${block}.archive"
chown www-data:www-data "${snapshotdir}/hsc_${now}_b${block}.archive"
# start node
pm2 start app.js --no-treekill --kill-timeout 10000 --no-autorestart
# register node once sycned (if witness enabled)
node witness_action.js register
Additionally since 3 months the script records the snapshot size after every creation. To better analyze the resulting data I have created a simple python program, which reads the data created by the script (in a csv file) and creates a chart using matplotlib. This is a part of the script:
import matplotlib.pyplot as plt
times = [] # timestamps when snapshots were created
sizes = [] # sizes of the snapshots
diffs = [] # size difference of two successive snapshots
plt.plot(times, sizes)
plt.title(f'hive-engine snapshot size {f}')
plt.xlabel('Time')
plt.ylabel('Size in MB')
plt.legend()
plt.show()
plt.bar(times[1:], diffs)
plt.title(f'daily increase of snapshot size {f}')
plt.xlabel('Time')
plt.ylabel('Increase in MB')
plt.show()
Full node snaphots
The following image shows the size of full node snapshots of the last few months and right now we are at almost 60GB for the snapshot already:
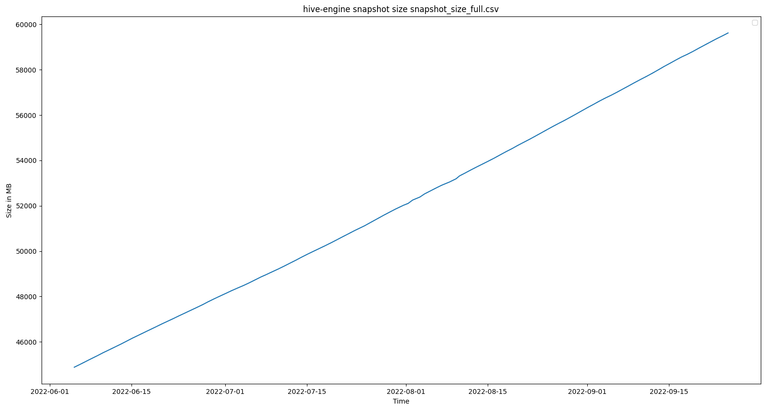
This pretty much shows that the size of snapshots is growing at approx. the same rate every single day. It also shows that it is getting increasingly more difficulty (expensive) to run engine full nodes. The daily increase in the snapshot size is seen pretty good in the following bar chart:
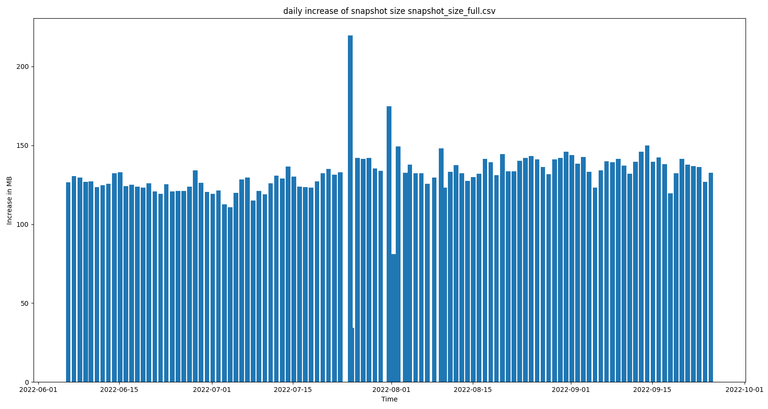
The few outliers in the chart above occurred when the snapshot script failed a few times and the snapshot was created a bit earlier / later than usual.
Light node snapshots
One of the biggest benefits of light nodes is that they only store part of the full transaction / block history, which drastically decreases the storage requirements. Compared to full nodes a light node with 30 days of history requires less than 10% of the storage. We can see the size of light node snapshots (with 30 day history) in the following chart, which is currently at around 4.5GB:

The initial straight line results from the 30 day history still being built up gradually. The size of the light node snapshot fluctuates a bit, depending on the number of transactions that are performed on the engine sidechain, but stays approximately at the same level. The fluctuation can be seen pretty good in the following chart:
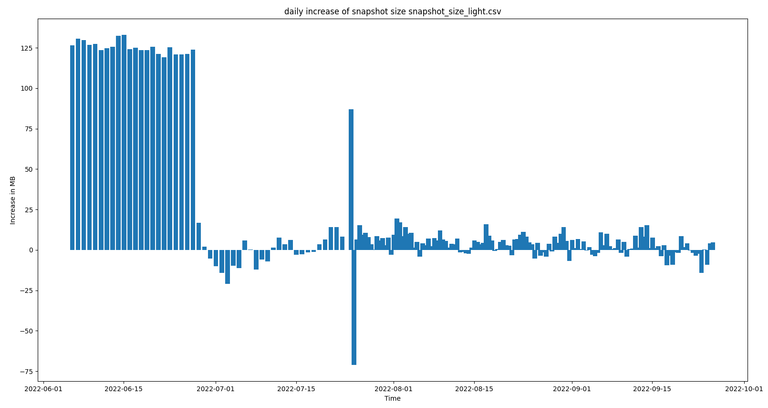
Again the outliers occurred when the snapshot script failed and the snapshot was created earlier / later than usual and the first part results from the history still being built up
I will continue to monitor the snapshot sizes and provide you with an update again in a few months or if anything interesting is coming up in the charts / data.
If you have any questions regarding the above or Hive-Engine nodes, please let me know.
Nearly 60 gig is incredible. It's a good thing that mongo can unzip it in place rather than having to unzip it first and then read it to save the storage. It's already costing a pretty penny to host a fullnode for engine, even if we don't count the bandwidth to get the data out:
Yeah unfortunately.. hopefully the
restore_partial.jsimproves this (if not setting up a new node), but never actually had to use it myself.One other option would be to restore from your local machine, but I guess that's a lot slower.
I've used restore partial a few times after divergence due to random reasons while experimenting, and it works beautifully. Setting up the new one is 100% where the problem lies for now. Hopefully we find more performance tweaks to improve that, or what I'd prefer, make syncing from a hived node faster so there's no need for snapshots.
The campaign aims to onboard new application developers to grow our ecosystem. If you missed the presentation, you can watch it on YouTube.
You cast your vote for the proposal on Peakd, Ecency, or using HiveSigner.
Thank you!Dear @primersion,May I ask you to review and support the Dev Marketing Proposal (https://peakd.com/me/proposals/232) we presented on Conference Day 1 at HiveFest?
Yay! 🤗
Your content has been boosted with Ecency Points
Use Ecency daily to boost your growth on platform!
Support Ecency
Vote for new Proposal
Delegate HP and earn more, by @primersion.
Congratulations @primersion! You have completed the following achievement on the Hive blockchain and have been rewarded with new badge(s):
Your next payout target is 8000 HP.
The unit is Hive Power equivalent because post and comment rewards can be split into HP and HBD
You can view your badges on your board and compare yourself to others in the Ranking
If you no longer want to receive notifications, reply to this comment with the word
STOPCheck out the last post from @hivebuzz:
Support the HiveBuzz project. Vote for our proposal!