¡Hola a todos y bienvenidos a este nuevo post! El día de hoy vengo hablar sobre arte e inteligencia artificial y quiero compartirles las obras de arte que he creado utilizando la inteligencia artificial Stable Diffusion, acompañadas de una pequeña historia de como se me ocurrieron estas ideas.
Aquí les muestro uno de mis resultados favoritos.
Escribí: A beautiful anime girl painted as a 3d videogame model".

One of my favorite results - Image generated with Stable Diffusion
No solo podrás ver algunas creaciones, sino que también aprenderás a utilizar esta herramienta y podrás crear tus propias obras de arte.
Disclaimer: Todas las imágenes aquí mostradas son generadas por inteligencia artificial desde el código, así que no tengo una fuente directa para las mismas, más que el cuaderno de código donde las generé.
¿Qué es Stable Diffusion?
Stable Diffusion es un modelo de generación de imágenes a partir de una entrada texto que ha sido posible gracias al esfuerzo y colaboración de los ingenieros de CompVis, Stability AI y LAION. Este modelo es capaz de generar imágenes de 512x512 pixeles.
En primer lugar les quiero mostrar la siguiente imagen, una vez yo leí el libro "Verónika decide Morir" de b, un libro que me me gustó mucho así como su moraleja, el personaje de Verónika me fascinó mucho, aunque como es un libro, su apariencia solo queda a la imaginación. Era una chica agraciada, con ojos verdes y cabello castaño y debido a las circunstancias termina en un sanatorio, así que debería llevar ropa de psiquiátrico y le gustaba tocar el piano, así que generé la siguiente imagen.

No coincide con la descripción de Verónika, pero así es como la imaginé yo, elegí un estilo de anime, porque es más fácil para generar caras. Hice varios intento, aquí les muestro otro que me gustó:

Source: - Image generated with Stable Diffusion (Link)
Como verán, la imagen tiene algunas fallas jajajaj, comenzando que tiene tres brazos, y el rostro no se ve bien, pero me gustó esta generación.
Continuando, en estos días haciendo un paseo en automóvil, iba en el asiento trasero y miro por la ventana. Ví a una de las chicas más hermosas que he visto, su rostro me enamoró al instante, pero como iba en auto, fue tan rápido que no me dio chance ni de pensar. Recuerdo que tenía un sombrero, shorts y una camisa vintage. Así que le pasé estas características a Stable Difussion para ver el resultado. Obtuve los siguiente:

Source: - Image generated with Stable Diffusion (Link)
Lo sé, un poco creepy, pero refleja justamente lo que me sucedió, fue un encuentro tan rápido que no recuerdo su rostro, pero si recuerdo que era muy hermosa y estaba vestida así. Sí lo sé, suena raro, lo que hice, pero quería refrescar mi memoria. También generé la siguiente imagen.

Luego quise generar personajes de mis juegos favoritos, Mario Bros, Sonic the Hedgehog y Crash Bandicoot. También Ace Attorney. Así que solo escribí Mario, Sonic, Crash Bandicoot, respectivamente, y obtuve los siguientes resultados, muy graciosos.. esto demuestra cuanto sabe la IA de videojuegos sin muchos detalles 😆

Source: - Image generated with Stable Diffusion (Link)
Después quise generar un paisaje bonito, pintado como un arte conceptual, así que obtuve el siguiente resultado:

Source: - Image generated with Stable Diffusion (Link)
Este me gustó mucho ya que obtuve justamnte lo que quería, quería un cielo azul, como si fuera un fondo de un videojuego. También lo intenté con un escenario nocturno con montañas y estrellas y obtuve lo siguiente:

Source: - Image generated with Stable Diffusion (Link)
Luego opté por una imagen realista, colorida de una mujer mirando hacia al frente. Escribí el siguiente prompt:
"A full body beautiful girl posing facing front with beautiful blue eyes, blonde hair painted as digital art with a lot of details, colors, lights and shadows"
Obtuve lo siguiente:

Source: - Image generated with Stable Diffusion (Link)
Como pueden observar, escribí una descripción más detallada y obtuve un resultado más bonito, me encantó. Siguiendo el miso prompt, volví a ejecutar el código y obtuve la siguiente imagen.

Source: - Image generated with Stable Diffusion (Link)
Por último, quería ver una chica pelirroja con ojos azules, dibujada con un estilo de arte digital y con detalles y obtuve lo siguiente:

Source: - Image generated with Stable Diffusion (Link)
¿Cómo funciona Stable Diffusion?
Para ello utilizan algo conocido como los modelos de Difusión, una nueva arquitectura de red neuronal capaz de generar imágenes partiendo de ruido (noise) en donde cada iteración permite sintetizar una imagen cada vez más detallada de acuerdo a la entrada de texto (prompt).
Stable Diffusion utiliza el modelo CLIP ViT-L/14 como codificador de textos. Recordando que CLIP es un modelo creado originalmente por OpenAI capaz de interpretar o predecir que es lo que se muestra en una imagen (Image Captioning). Así que permtió un vínculo o una traducción entre imágenes y texto.
Por otra parte, este modelo fue entrenado con el conjunto de datos LAION-5B, es decir, un dataset con 5 mil millones de fotos etiquetadas por CLIP. (5,85 mil millones de pares de imagen-texto), convirtiendose en el dataset de imágenes-texto más grande abierto públicamente, a la disposición de cualquier persona.
Este conjunto de datos fue posible gracias al equipo de Hugging face, Doodlebot, Stability AI y the-eye.eu ya que proveyeron los recursos de cómputo necesarios para poder crearlo y almacenarlo.
¿Tengo los derechos sobre mis creaciones?
Stable Diffusion es un modelo que ha sido publicado como código abierto (Open Source), así que puedes usar, copiar, distribuir el código, siempre que se distribuya con su licencia. Por otra parte, los resultados generados se pueden utilizar para fines comerciales o **personales **sin ninguna restricción.Cito desde el sitio web de Dream Studio:
The public domain is not a unified concept across legal jurisdictions, thus the specific affirmation you make when using the DreamStudio Beta and the Stable Diffusion services is that of the CC0 1.0 Universal Public Domain Dedication [available at https://creativecommons.org/publicdomain/zero/1.0/]
Pueden crear arte para videojuegos, para las redes sociales, para stock de fotos, escalar una imagen con otra herramienta y convertirlas en merchandising, hacer camisetas, etc. Las posibilidades son infinitas.
My advices for the prompt:
- Mientras más adjetivos uses, mejor. Una descripción detallada ayuda a obtener un mejor resultado.
- Les recomiendo que las descripciones sean en inglés, ya que, aunque estos largos modelos de lenguaje son entrenados para aprender múltiples idiomas, la mayoría de los ejemplos están en inglés.
- No intentes crear contenido NSFW, el modelo tiene filtros para evitar contenido inapropiado, sexual o violento. (Don't be evil).
I tell you some words I used to get these results, you may try it,too.
1. A concept art of [...]
De este modo obtendrán un arte conceptual, con hermosos fondos así como los de los videojuegos. Muy útil para crear escenarios.
2. [...] painted as digital art
Quería obtener un acabado como las hermosas obras que veo en Twitter, de este modo obtendrán un acabado detallado y moderno.
3. [...] painted as a videogame 3d model
De este modo el personaje dibujado tendrá un toque tridimensional, respetando las sombras y la iluminación que le otorgan un mayor estética.
4. [...] with a lot of colors, lights and shadows
Para obtener una acabado con iluminación y sombreado que le otorgan realismo.
¡Así es, esta inteligencia artificial es muy genial! ¿Te gustaría probarla? ¡Puedes hacerlo!
Opción #1
Existen varias opciones para usar Stable Diffusion, la primera de ellas es abrir el siguiente cuaderno de código en Google Colaboratory, aquí podrás utilizar la API de Stable Diffusion gracias a Stability AI y Dream Studio.https://colab.research.google.com/github/stability-ai/stability-sdk/blob/main/nbs/demo_colab.ipynb
Antes de ejecutar el código deberán crear una cuenta en Dream Studio a través del siguiente enlace.
Nota: Para usar esta API de Dream Studio tendrás 100 generaciones gratuitas. Sin embargo, no estoy seguro si estas generaciones se reiniciarán cada mes.
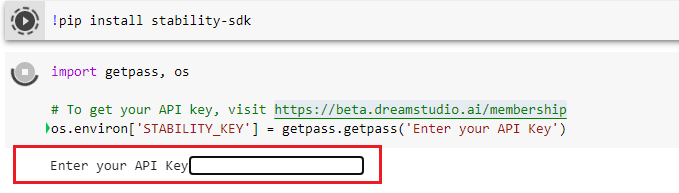
Al ejecutar la celda #2 del notebook, se mostrará una entrada de datos, allí tendrás que pegar la API Key que obtendrás en el enlace anterior: https://beta.dreamstudio.ai/membership
El código es muy sencillo, solo hay que ejecutar todas las celdas y solo deben sustituir la parte donde dice prompt="houston, we are a 'go' for launch!", su texto debe ir dentro de las comillas.
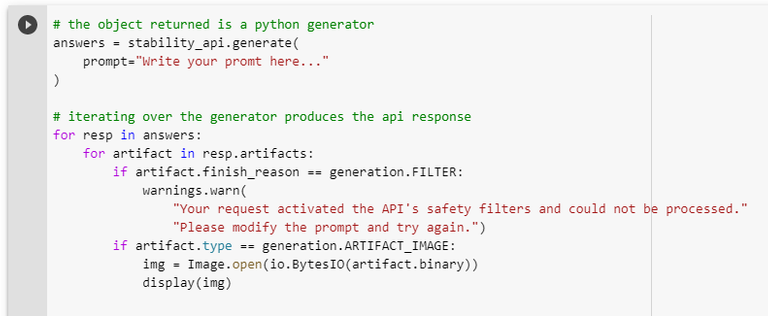
Deben sustituir el texto por defecto por la descripción de lo que les gustaría ver imagen. Por ejemplo, "A concept art of a landscape with a beautiful blue sky"
Opción #2
Puedes acceder al siguiente cuaderno de código de Google Colaboratory, elaborado por el equipo de HuggingFace 🤗. Este cuaderno tiene un mayor de nivel de dificutad ya que implmenta el modelo Stable Difussion utilizando la bibliotecadiffusers de HuggingFace 🤗.
https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_diffusion.ipynb
Para ejecutar este cuaderno de código, primero tendrán que crear una cuenta en Hugging Face: https://huggingface.co/join, luego tendrás que ir a las configuraciones de tu cuenta (Settings) y tendrás que copiar y pegar tu API Key de Hugging Face.
Ejecutas las celdas de código, se te pide que inicies sesión, colocas tus credenciales y luego se te pedirá que ingreses tu API Key, aquí tendrás que ejecutar varias celdas para generar una imagen, así que es un poco más complejo de utilizar. Pero de igual forma solo escribirías tu prompt, tu entrada y observaríass los resultados.
Ustedes se preguntarán ¿Esta IA "roba" o copia las obras de otros artistas? Este modelo fue creado con billones de imágenes públicas extraídas de Internet. En mi opinión, esta IA no copia el trabajo de artistas, ya que genera contenido nuevo partiendo de lo que "vio", o fue entrenado. Es como tomar inspiración o referencias de otros artistas, pero el contenido es totalmente diferente. Además, es una tecnología, no es un ente con intención de vender contenido de otros. Este dataset fue creado con fines académicos.
Como artistas, si quieren saber si su arte fue utilizado para alimentar este gigantesco dataset y modelo de inteligencia artíficial pueden utilizar el siguiente buscador: https://rom1504.github.io/clip-retrieval/
Artistas, su trabajo sigue siendo muy apreciado, ya que pueden crear obras totalmente personalizadas, la IA genera cosas bonitas, pero todavía comete sus fallos, en cuanto a pose, colores y tiene dificultades para algunos rostros. Ustedes estudiaron anatomía, iluminación y sombreado, así que no se preocupen, no serán reemplazados, sino que tendrán una herramienta para ayudarlos.
Los invito a crear una publicación mostrándonos sus propias creaciones usando Stable Diffusion. Me etiquetan y yo paso por sus posts 😉
Espero que les haya gustado esta publicación ¿Cual de todas las imágenes les gustó más? Déjenmelo saber en los comentarios 🤗
Ansioso por ver sus creaciones ¡Saludos y espero verlos pronto!
English
Hello everyone and welcome to this new post! Today I come to talk about art and artificial intelligence and I want to share with you the artworks I have created using Stable Diffusion artificial intelligence, accompanied by a little story of how I came up with these ideas.
Here is one of my favorite results.
I wrote: A beautiful anime girl painted as a 3d videogame model".
One of my favorite results - Image generated with Stable Diffusion
Not only will you get to see some creations, but you will also learn how to use this tool and be able to create your own works of art.
What is Stable Diffusion
?Stable Diffusion is a model for generating images from text input that has been possible thanks to the effort and collaboration of CompVis, Stability AI and LAION engineers. This model is capable of generating 512x512 pixel images.
First of all I want to show you the following image, once I read the book "Veronika decides to die" by b, a book that I liked a lot as well as its moral, the character of Veronika fascinated me a lot, although as it is a book, her appearance is only left to the imagination. She was a graceful girl, with green eyes and brown hair and due to circumstances she ends up in a sanatorium, so she should wear psychiatric clothes and she liked to play the piano, so I generated the following image.
It doesn't match Veronika's description, but that's how I imagined her, I chose an anime style, because it's easier to generate faces. I made several attempts, here I show you another one that I liked:
Source: - Image generated with Stable Diffusion (Link)
As you can see, the image has some flaws hahahahah, starting that it has three arms, and the face does not look good, but I liked this generation.
Continuing, these days doing a car ride, I was in the back seat and I look out the window. I saw one of the most beautiful girls I've ever seen, her face made me fall in love instantly, but since I was in a car, it was so fast that I didn't even have a chance to think. I remember she was wearing a hat, shorts and a vintage shirt. So I passed these features to Stable Difussion to see the result. I got the following:
Source: - Image generated with Stable Diffusion (Link)
I know, a bit creepy, but it reflects just what happened to me, it was such a quick encounter that I don't remember her face, but I do remember that she was very beautiful and dressed like that. Yes I know, it sounds weird, what I did, but I wanted to refresh my memory. I also generated the following image.
Then I wanted to generate characters from my favorite games, Mario Bros, Sonic the Hedgehog and Crash Bandicoot. Also Ace Attorney. So I just typed Mario, Sonic, Crash Bandicoot, respectively, and got the following results, very funny.. this shows how much the AI knows about video games without a lot of details 😆
Source: - Image generated with Stable Diffusion (Link)
Then I wanted to generate a nice landscape, painted as a concept art, so I got the following result:
Source: - Image generated with Stable Diffusion (Link)
I really liked this one as I got just what I wanted, I wanted a blue sky, as if it was a video game background. I also tried it with a night scenery with mountains and stars and got the following:
Source: - Image generated with Stable Diffusion (Link)
I then opted for a realistic, colorful image of a woman looking straight ahead. I typed the following prompt: "A full body beautiful girl posing facing front with beautiful blue eyes, blonde hair painted as digital art with a lot of details, colors, lights and shadows" I got the following:
Source: - Image generated with Stable Diffusion (Link)
As you can see, I wrote a more detailed description and got a nicer result, I loved it. Following the same prompt, I ran the code again and got the following image.
Source: - Image generated with Stable Diffusion (Link)
Finally, I wanted to see a red-haired girl with blue eyes, drawn in a digital art style with details and I got the following:
Source: - Image generated with Stable Diffusion (Link)
How does Stable Diffusion work?
They use something known as Diffusion models, a new neural network architecture capable of generating images from noise where each iteration allows synthesizing a more and more detailed image according to the text input (prompt).
Stable Diffusion uses the CLIP ViT-L/14 model as a text encoder. Recalling that CLIP is a model originally created by OpenAI capable of interpreting or predicting what is displayed in an image (Image Captioning). So it allowed a link or a translation between images and text.
Moreover, this model was trained with the LAION-5B dataset, i.e. a dataset with 5 billion photos tagged by CLIP (5.85 billion image-text pairs), making it the largest publicly open image-text dataset available to anyone.
This dataset was made possible by the team at Hugging face, Doodlebot, Stability AI and the-eye.eu as they provided the computational resources needed to create and store it.
Do I have the rights to my creations?
Stable Diffusion is a model that has been published as Open Source, so you can use, copy, distribute the code, as long as it is distributed under its license. Moreover, the generated results can be used for commercial or **personal purposes without any restrictions.I quote from the Dream Studio website:
The public domain is not a unified concept across legal jurisdictions, thus the specific affirmation you make when using the DreamStudio Beta and the Stable Diffusion services is that of the CC0 1.0 Universal Public Domain Dedication [available at https://creativecommons.org/publicdomain/zero/1.0/]
They can create art for video games, for social networks, for stock photos, scale an image with another tool and turn it into merchandising, make T-shirts, etc. The possibilities are endless.
My advices for the prompt:
- The more adjectives you use, the better. A detailed description helps to get a better result.
- I recommend that the descriptions be in English, because, although these long language models are trained to learn multiple languages, most of the examples are in English.
- Don't try to create NSFW content, the model has filters to avoid inappropriate, sexual or violent content (Don't be evil).
I tell you some words I used to get these results, you may try it,too.
1. A concept art of [...].
This way you will get a concept art, with beautiful backgrounds just like in video games. Very useful for creating scenarios.
2. [...] painted as digital art
I wanted to get a finish like the beautiful artwork I see on Twitter, this way you will get a detailed and modern finish.
3. [...] painted as a videogame 3d model
In this way the drawn character will have a three-dimensional touch, respecting the shadows and lighting that give it a greater aesthetic.
4. [...] with a lot of colors, lights and shadows.
To obtain a finish with lighting and shading that give it realism.
That's right, this artificial intelligence is really cool! Would you like to try it, you can!
Option #1
There are several options to use Stable Diffusion, the first one is to open the following codebook on Google Colaboratory, here you can use the Stable Diffusion API thanks to Stability AI and Dream Studio.https://colab.research.google.com/github/stability-ai/stability-sdk/blob/main/nbs/demo_colab.ipynb
Before running the code you will need to create an account in Dream Studio through the following link.
Note: To use this Dream Studio API you will get 100 free generations. However, I am not sure if these generations will be reset every month.
When you run cell #2 of the notebook, it will show a data entry, there you will have to paste the API Key that you will get from the link above: https://beta.dreamstudio.ai/membership
The code is very simple, just run all the cells and just replace the part where it says prompt="houston, we are a 'go' for launch!", your text must be inside the quotes.
You must replace the default text with the description of what you would like to see in the image. For example, "A concept art of a landscape with a beautiful blue sky".
Option #2
You can access the following Google Colaboratory codebook, put together by the HuggingFace 🤗 team. This notebook has a higher level of difficulty as it implements the Stable Difussion model using the ```diffusers`` library from HuggingFace 🤗.https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_diffusion.ipynb
To run this codebook, you will first need to create an account on Hugging Face: https://huggingface.co/join, then you will need to go to your account settings (Settings) and you will need to copy and paste your Hugging Face API Key.
You run the code cells, you are prompted to log in, put in your credentials and then you will be prompted to enter your API Key, here you will have to run several cells to generate an image, so it is a little more complex to use. But still you would just type your prompt, your input and observe the results.
You may ask Does this AI "steal" or copy the works of other artists? This model was created with billions of public images extracted from the Internet. In my opinion, this AI does not copy the work of artists, as it generates new content from what it "saw", or was trained. It is like taking inspiration or references from other artists, but the content is totally different. Moreover, it is a technology, it is not an entity with the intention of selling other people's content. This dataset was created for academic purposes.
As artists, if you want to know if your art was used to feed this gigantic dataset and artificial intelligence model you can use the following search engine: https://rom1504.github.io/clip-retrieval/
Artists, your work is still very much appreciated, as you can create fully customized works, the AI generates beautiful things, but it still makes its faults, in terms of posing, colors and has difficulties for some faces. You studied anatomy, lighting and shading, so don't worry, you will not be replaced, but you will have a tool to help you.
I invite you to create a post showing us your own creations using Stable Diffusion. Tag me and I'll go through your posts 😉.
I hope you liked this post Which of all the images did you like the most? Let me know in the comments 🤗
Anxious to see your creations. Bye and hope to see you soon!
Translated with www.DeepL.com/Translator (free version)
Useful links:
Stability AI SDK Github: https://github.com/Stability-AI/stability-sdk
Stable Diffusion Model Card: https://huggingface.co/CompVis/stable-diffusion
Stable Diffusion License: https://github.com/CompVis/stable-diffusion/blob/main/LICENSE
Live video by Dot CSV: En donde podrás profundizar mucho más sobre el modelo Stable Diffusion.
Citation:
@InProceedings{Rombach_2022_CVPR,
author = {Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj"orn},
title = {High-Resolution Image Synthesis With Latent Diffusion Models},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022},
pages = {10684-10695}
}
Me gustó la chica misteriosa, y se ve muy interesante esta aplicación, la chica de los tres brazos me pareció graciosa tuve que hacer una pausa y ver de nuevo porque pensé que era mi imaginación jajajaja espero que sigas puliendo tus habilidades y logres mejorar tus técnicas! :)
¡Hola Hazel! Gusto en verte por aquí, me alegra que te haya gustado la publicación 😁😁
Jajajaj, si la chica salió con 3 brazos 😅
Un abrazo! 🤗
Saludos
Que éxito
Wooow muy lindo tu arte amigo. te felicito.
Muchas gracias, me alegra que hayas pasado por aquí y te haya gustado 🙏
¡Saludos! 😄😄
Congratulations @luis96xd! You have completed the following achievement on the Hive blockchain and have been rewarded with new badge(s):
Your next target is to reach 400 comments.
You can view your badges on your board and compare yourself to others in the Ranking
If you no longer want to receive notifications, reply to this comment with the word
STOPTo support your work, I also upvoted your post!
Check out the last post from @hivebuzz:
Support the HiveBuzz project. Vote for our proposal!
The rewards earned on this comment will go directly to the people sharing the post on Twitter as long as they are registered with @poshtoken. Sign up at https://hiveposh.com.