Better late than never, here comes my report for the second week of the Particle Physics participative project on Hive organized by @lemouth and that you can follow on #citizenscience.
As you can see, most of my colleagues have submitted their reports for this second week already, things get busy and it has not been so straight forward to achieve results this week. I will explain later where I had some problems in case it is useful for the hivers to come (I am sure more people will join us!).
The guidelines I am following come from the blog entry: Citizen science on Hive - simulating top quark production at CERN’s Large Hadron Collider
If you want to know more, you have can read the following posts from @lemouth:
- Introduction: Towards a citizen science particle physics research project on Hive
- Week 1: Installing MG5_AMC software: Citizen science particle physics project on Hive - Let’s get started!
And if you want to refer to my first report, that includes how to install a Virtual Machine on a windows PC, you can go to Citizen Science project: Week 1 - Installing Linux in a Virtual Machine + software installation
And now, let´s go for the report of my first usage of the software package MG5_aMC (MadGraph5 and aMC)
Task 1 – Top-antitop quark production
First thing, we need to run MG5_aMC (refer to my first report). When opening it already tells us all the particles that can be used in the model. As the reference post for this entry indicates, the ~ after some of them refers to their antiparticle.
We are going to generate the process that we are going to be interested in, that is proton collisions leading to top-antitop creation:
generate p p > t t~
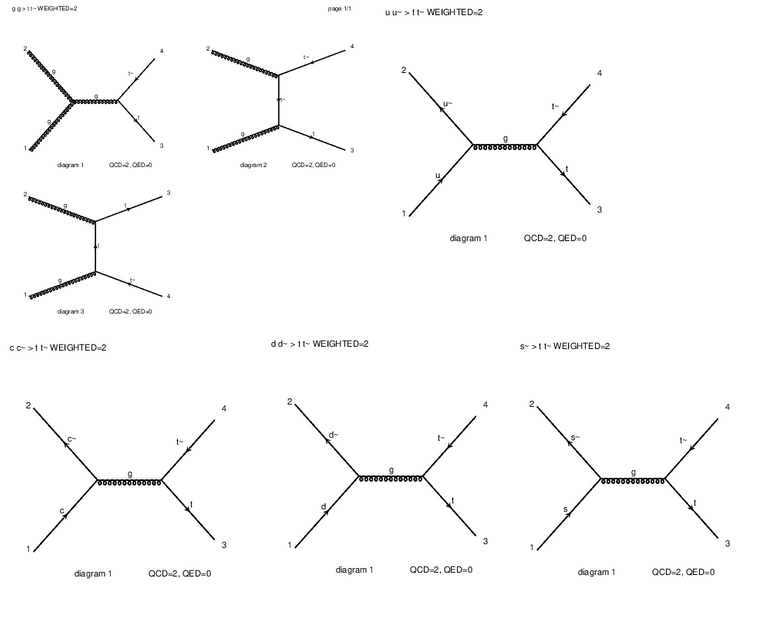
And we can see the related Feynman diagrams by typing:
display diagrams
Troubleshooting: Here I had the first of the issues I have encountered when trying to follow last week exercises. Just to remind you, I am running with Xubuntu 20.04, and I was getting the following alarm instead of any drawing:

So, apparently my computer was not finding some software important to show me what (in that moment I did not know) were postscript files. It was looking for an eps extension and... took me a while to discover what i needed.
The predefined software to open PDF and PS files in Xubuntu was not being picked by the system, so I had to navigate to the configuration file, create a backup (just in case) and modify the relevant line for *.eps files by changing None to atril (note that in other Operative Systems this will be different, in Ubuntu you will most probably use Okular by default)


Task 2 - Save our working directory
This step was straight forward, and surprisingly uneventful. I just took the name report2 for this computations -although we are going to reuse this in the future, maybe I should have been wiser! -.
output report2
And there it is, you can see it being saved in a new folder, in the same folder that hosts your MadGraph5:

Inside the Source folder you can see the Fortran code behind the diagrams we have to run, oh, this reminds me so much to the old university times 😅.
Task 3 - Computing!
We return now to MG5 and we have to launch our computations. For that we send the following commands (remember, you could have chosen a different name than report2)
launch report2
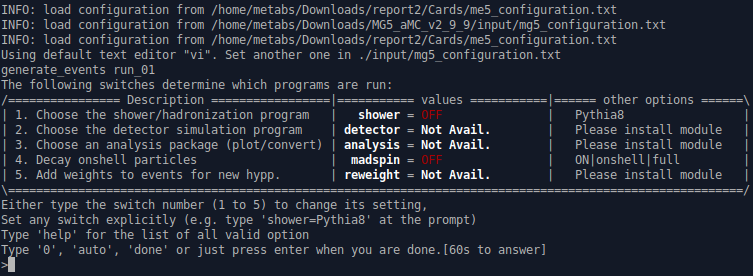
Then it is important to activate Pythia8 as a shower by typing 1 and madspin by typing 4. It is great to see how a comment by @servelle in @lemouth’s post led to an improvement of the original post. I really like this level of feedback.

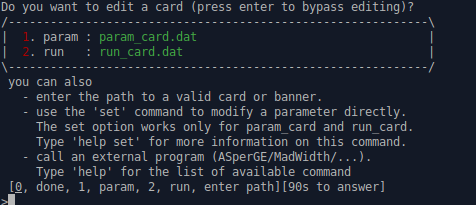
And we will get the following menu. We are going to edit number 2: run_card.dat to change the collider settings (this sounds so cool). Vim opened automatically in my case. There we need to edit:
True = use_syst ! Enable systematics studies
to be
False = use_syst ! Enable systematics studies
This process takes a while, and i have been having some issues, see below in Hard disk space troubleshooting.
Tiny troubleshooting: I have been running this operation several times, which has made me to remove everything and restart for several times. If you forget to activate Pythia8 and madspin you will see what appears in the image below. The important thing is not to panic, restart and not to forget to press 1 and 4 😅.
Hard disk troubleshooting: When I was running my simulation, after more than an hour computing I was getting all the time the following message:
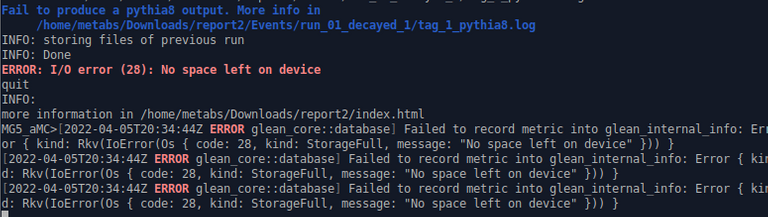
And, btw, if I was trying to restart the machine, it would not pass of the login menu. The solution to that problem was just to restart the machine to Xubuntu in recovery mode, open the root mode by console and delete the contents of the Event folder.
I was a bit puzzled, then I discovered that yes, the 10GB I assigned as maximum space were really over. I created my virtual disk as Dynamically allocated, but that does not mean it is infinite, you have to assign a maximum space, so guys, remember to take something bigger than 10GB.
Anyway, I thought, this may be easy, I just go to the disks properties and enlarge it to something bigger:
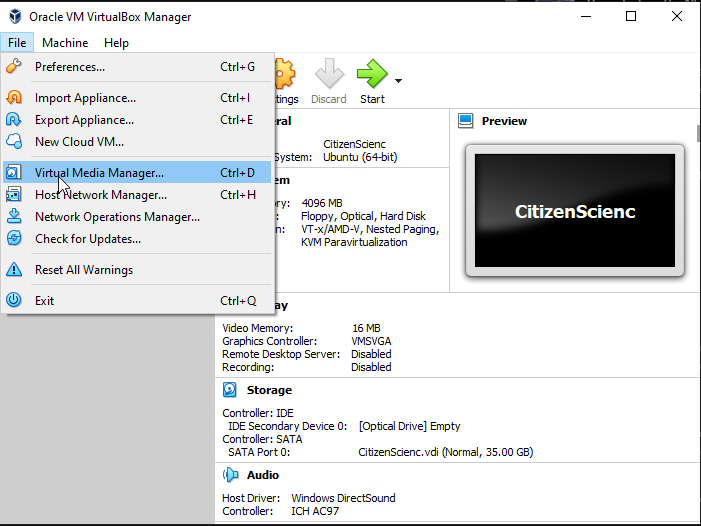
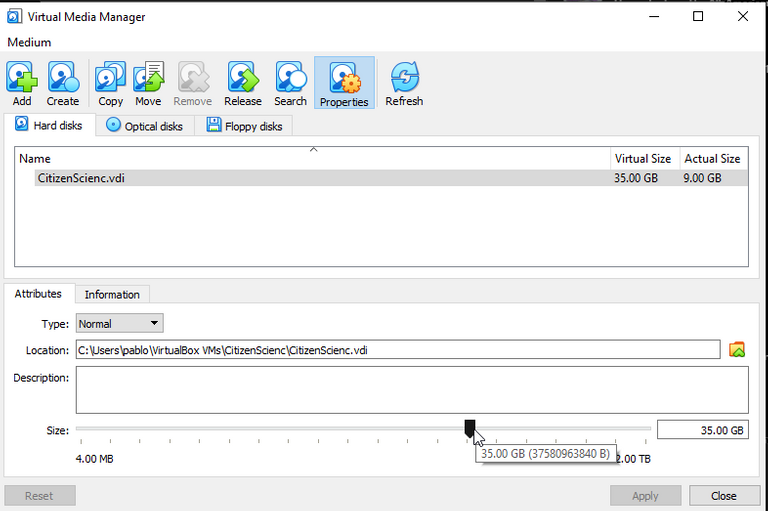
But, when running my simulations again, same problem. Still failing and telling me there is no space.
Uhm... the system was still recognizing my main partition as a 10GB disk. Now everything made sense, I may have enlarged the hard disk, but my partitions configuration was still of a partition of 10GB and probably a lot of unassigned, unformatted space. Two options were in front of me, starting from scratch and create a new Virtual Machine, running the first week report again or... try to change the configuration of my partitions. A quick check on the internet returns that if my partition and the free space are contiguous, I can risk it and enlarge my partition to the free space.
So, I did a copy of my hard disk, because remember this is just a file in our computer. Then I downloaded a bootable version of GParted. This is a software to change the size of your partitions in linux. However, you cannot change the partitions that you are running, that is why we run an external "CD" that contains a simple linux version with GParted ready to run.
You can find the bootable (this means that executes when you switch on your computer instead of your operative system) ISO image in the GParted webpage
In the configuration of the virtual machine, we can simulate introducing this Disk. We have to go to the settings and select the .iso we have just downloaded:
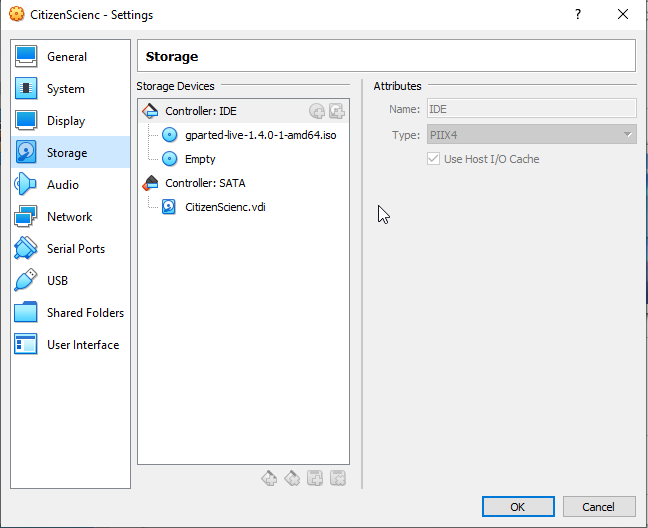
And now, when we launch our Virtual Machine, we see how our instead of Xubuntu, the GParted disk has started:
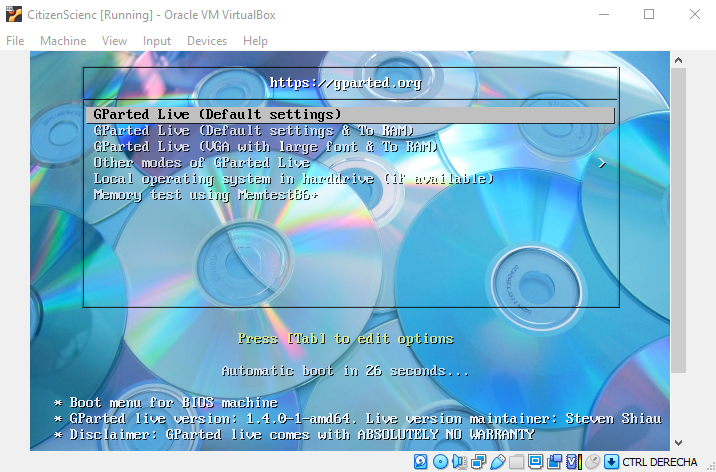
After following the start menu, selecting keyboard type and some basic questions, we can open GParted there and of course, I had a lot of empty space:
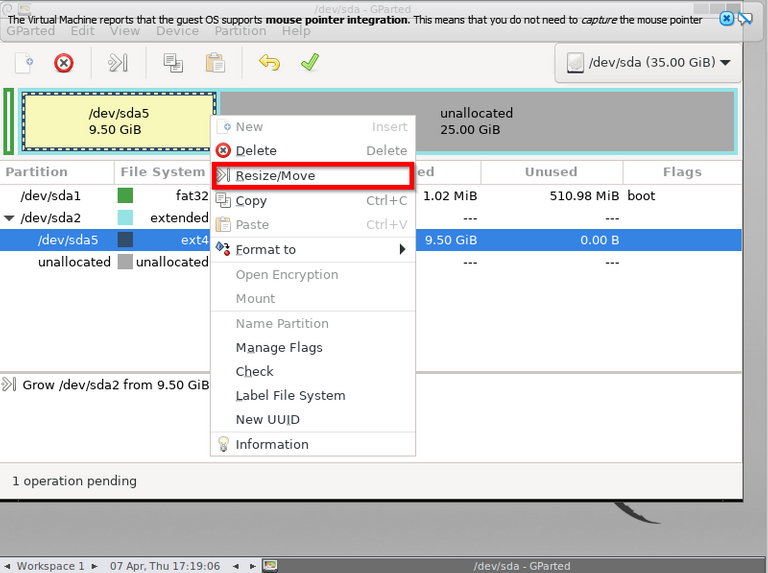
I have resized the partitions. Note you do this in two stages, first assigning the space to the partition and then enlarging the current one. You can see a good explanation on this link.
And finally, I "removed" the *.iso image and restarted my virtual machine to discover that everything looks fine there and that my hard disk has the proper size:
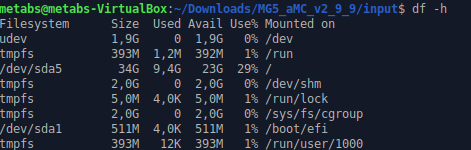
Process for doing this part has been fast, almost instantaneous, so I have saved a lot of time in comparison with the creation of a new VM and installing all the software. Thank you @lemouth for the support through this (normal and moral!).
Task 4 - Confirming our outputs look OK
Finally my computation finished. Feels like a great achievement after all the little steps to reach here. See that it indicates that with my resources this took around 2 hours, but I do not have a very powerful computer and I am using a virtual machine.
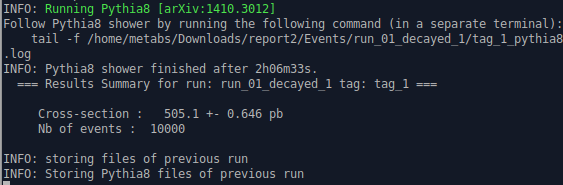
And in our project folder we have tag_1_pythia8_events.hepmc.gz, this file contains the information of our 10000 collisions and apparently our job will be to analyze it in the incoming weeks.
Wrap up
I started with last week assignment last Sunday and little technical problems have made this extend itself a bit more than expected. However, it has been a nice experience, like little riddles to solve. Now it is time to wait for the next instruction set to see what comes from the information we got from our collisions. Cannot wait!
I was definitely expecting for your report. When I saw it I was quite excited. Before reading it, I had two questions popping up from my mind:
It was cool to then read the report and see that "yes" was a good answer to both of these.
As for the last report you wrote, I really appreciated all the details you put, that I imagine will be useful for others reaching in the same problems (maybe in the future, if we have new people joining us; who knows...).
And now let me share my two comments. First of all, note that
report2as a name for the working directory is fine. We will use this one for a couple of episodes before starting to generate the real deal. There, it will be important to monitor what you generated closely. For this purpose, appropriate folder names definitely help. But here, we are still in a "tutorial mode" so that can still be a little disorganised.If I remember well, a large chunk of this 10GB is taken by the operating system. The simulation we performed should take more or less 1 GB. Do you mind confirming this? Thanks in advance!
PS: I was pleased to read you met Fortran at the university. This means that we may be of a similar age ;)
Thanks for the words! Definitelly this took a bit longer, I had to leave it for the weekend and the small issues and waiting times did not allow to feel I was working continuously on it. It is fun how it looks now that the problems were so small, once you know the answer everything is easy.
By the way, I have updated the original post for Report #1 to add a note on the HDD size and the need to install numpy.
Regarding the disk usage, I can confirm you that most of that space is the current basic installation of Xubuntu+basic packets (but python, fortran, C, make and so on are not so heavy), maybe close to 7GB. The MG5_aMC folder is only about 1.4GB and this weeks output below 1GB.
I started univeristy in the mid 2000s, there everyone thought Fortran was already too old school, just an excentricity. Later on, I had to pass mostly to Octave and Matlab and... a lot of easy solutions on Excel + VisualBasic (yes, I became that high level kind of people). Only this year is the moment I am modernizing myself and starting to use little python scripts. And python, that now looks omnipresent... was never in almost any conversation for us.
Btw, I need to find some time to try to write some of my normal posts, I want to update some of the topics I was covering the last months. But I also hope that the next episode of this project comes soon! I guess last week with so many days off... will not leave me so much time to write.
I would love to read again some of your normal posts too. There is however only 24 hours in a day and 7 days in a week, and there is not much we can do about it. However, don't worry, the next episode of the citizen science projet will be a bit lighter than the previous one, so that I won't take too much of your time ;) The reason is that we need to deal with the installation of another program (which may be super quick for some, but rather slow for others, depending on the system and how linux is mastered).
PS: I am definitely from the same generation as you, and I have experienced the same situation relative to programming. I was studying at the university during the end of the 1990s and the first half of the 2000s. Now, I am mostly dealing with codes in Python and C++. However, Fortran is still there a lot, in particular in the core of MG5aMC :)
Great Post!
!1UP
Thank you @luizeba! Hope there will be more to come, stay tuned to #citizenscience
!hivebits
The rewards earned on this comment will go directly to the person sharing the post on Twitter as long as they are registered with @poshtoken. Sign up at https://hiveposh.com.
Thanks for your contribution to the STEMsocial community. Feel free to join us on discord to get to know the rest of us!
Please consider delegating to the @stemsocial account (85% of the curation rewards are returned).
You may also include @stemsocial as a beneficiary of the rewards of this post to get a stronger support.
Congratulations @metabs! You have completed the following achievement on the Hive blockchain and have been rewarded with new badge(s):
Your next target is to reach 4750 upvotes.
You can view your badges on your board and compare yourself to others in the Ranking
If you no longer want to receive notifications, reply to this comment with the word
STOPCheck out the last post from @hivebuzz:
Support the HiveBuzz project. Vote for our proposal!
You have received a 1UP from @luizeba!
@stem-curator, @vyb-curator, @neoxag-curatorAnd they will bring !PIZZA 🍕
Learn more about our delegation service to earn daily rewards. Join the family on Discord.
This post has been manually curated by @bhattg from Indiaunited community. Join us on our Discord Server.
Do you know that you can earn a passive income by delegating to @indiaunited. We share 100 % of the curation rewards with the delegators.
Here are some handy links for delegations: 100HP, 250HP, 500HP, 1000HP.
Read our latest announcement post to get more information.
Please contribute to the community by upvoting this comment and posts made by @indiaunited.
Yay! 🤗
Your content has been boosted with Ecency Points, by @metabs.
Use Ecency daily to boost your growth on platform!
Support Ecency
Vote for new Proposal
Delegate HP and earn more