
It's been six days since I've announced my Public Hivemind SQL service proposal. Meanwhile, I've been thinking about the best possible scenarios to expose Hivemind's internal database.
After advising some of my DevOps friends, the initial technical plan started shaping up.
PostgreSQL user accounts for each person/project
Instead of using one big anonymous, public account I'm considering to create a different database user for each personality/project. PostgreSQL can scale millions of users in a single server.
The rationale behind creating a user for each consumer is to understand user behavior and network saturation. The user creation process will be a simple web application that you can log in with Steemconnect and grab your credentials.
Maybe requiring at least N+ SP in the account might be helpful to incentivize powering up. I don't see anything huge on that limit, something like a minimum 100 SP limit looks fair.
Connection pooling and load balancing
PgBouncer, is a lightweight connection pooler for the PostgreSQL, will be used for the connection pooling. HaProxy will route the requests from pgBouncer to replica sets. Routing will be round-robin in general, however, on special cases, we may have exceptions.
For example, let's say @steempeak wanted to use this DB and started using extensively, then I might have a choice to allocate one replica instance to @steempeak while other users sharing other replica instances.
Initial cluster
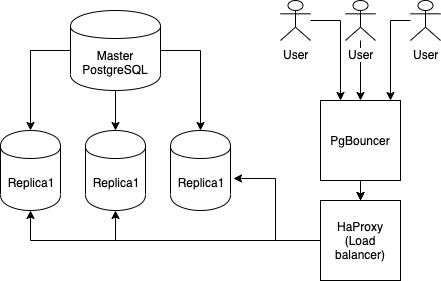
The initial cluster is designed like this. I will start with one master and three replica instances where clients routed through PgBouncer and HaProxy.
All replicas will be read-only while the master instance will be feeding the replicas as new blocks produced in the STEEM network. Of course, this is not a %100 high-availability setup, however, I think it's a good setup to start with and experiment.
Vote for the proposal
So far, the proposal gained around 9m SP support. This is huge but it's not enough. It needs around 12.8+ M SP support to pass the gtg's refund proposal and start getting funds.
The funding window will start in three days. If you feel this project might be helpful for the ecosystem, consider casting a proposal vote.
Vote via Steemconnect
Vote via steemproposals.com
If people are keen on seeing stats from Hivemind they should vote for this proposal!
Thanks! :)
Pleasure. I hope you reach the target and there is new data to look at :)
You love a good pretty report.
Posted using Partiko iOS
!giphy take+my+money
Posted using Partiko iOS
giphy is supported by witness untersatz!
Good thinking about having individual accounts. 🙏 it gets funded. @alliedforces curate
Posted using Partiko iOS
Keep up the great work!
@enginewitty and @untersatz.The #spreadlovenotwar curation campaign is under the guidance of witnesses You got some love from a member of @thealliance family!
Will vote it if I remember.
Here's the Peak Link BTW:
https://steempeak.com/me/proposals/emrebeyler
Thanks! I can remember it for you if you want. Free service 😇
Hi, I introduced your proposal to steemcoinpan (it is one of steem-engine nitrous community)
https://steempeak.com/@jacobyu/sps-2019-10-27
I hope your proposal will get fund.
Thank you!
Hi@jacobyu,
Thanks! Yes, it will be a free service. I wont charge anything. SPS will provide the funds that I need for the project. :)
Sound good.
I voted your proposal.
How much time do we have to vote your proposal?
Funding time starts in 2 days, however it’s also possible to vote after that. This proposal is valid for one year.