안녕하세요, 첫 글을 씁니다.
이 공간은 아마도, 제가 공부하는 내용(딥러닝, 뉴로사이언스, 이미지 처리 등등)을 정리하고 기록해두기 위한 용도로 사용될 것 같습니다. 물론 비슷한 공부를 하시는 분들과 토론하며 이해를 넓히는 활동도 언제나 환영입니다.
B. Deng et al., “Peephole: predicting network performance before training,” arXiv:1712.03351, Dec 2017.
본 글은 위 논문에 대한 소개입니다.
딥러닝을 하는 사람들의 끝나지 않는 고민, 그것은 ‘네트워크 구조를 도대체 어떻게 만들어야 최상의 성능을 낼 수 있을까’일 것입니다. 이 글에서 소개하려고 하는 논문 또한 같은 고민에서 출발합니다. 특히 이 논문에서는 이미지에 대해 좋은 성능을 보이는 CNN (convolutional neural network)에 중점을 두고 이야기 하고 있습니다.
딥러닝에 대한 기초지식이 없으신 분들에게는 이 글이 다소 어렵게 느껴질 수도 있으니 아래링크의 글들을 먼저 읽으시기를 권합니다. 이 글은 논문의 흐름을 그대로 따라가고 있지만 이해를 돕기 위해 논문 내용에서 일부 추가 혹은 생략한 부분도 있습니다.
CNN의 기본 개념 및 레이어 종류: http://aikorea.org/cs231n/convolutional-networks/ RNN의 기본 개념: http://aikorea.org/blog/rnn-tutorial-1/
최근의 딥러닝 열풍은 ImageNet 데이터베이스를 이용한 ILSVRC 챌린지에서 시작되었다고 할 수 있습니다. 이 챌린지는 2010년에 처음 시작되었는데, 그 때 우승한 팀은 NET-UIUC라는 팀으로 descriptor coding과 SVM (support vector machine)을 사용해 0.72의 정답률(top-5 기준)을 보였습니다.
하지만 딥러닝이 적용되면서 이 정답률은 무섭게 올라가기 시작했습니다. 작년 챌린지에서 1등한 WMW팀의 정답률은 무려 0.977을 기록했죠. ImageNet 데이터베이스를 만들면서 측정한 사람의 정답률이 약 0.949에 지나지 않는다는 것을 감안하면, 이미 이미지 분류에서 딥러닝은 사람의 한계를 뛰어넘었다고 볼 수 있을 것입니다.
그런데 이 눈부신 발전의 주역은 다름 아닌 “더 나은 네트워크 구조”였습니다. AlexNet을 시작으로 VGG, GoogLeNet, ResNet 같은 딥러닝 네트워크들이 새롭게 제안되면서 그 때마다 이미지 분류의 정확도를 유의미하게 향상시켜 온 것입니다.
“improving network design has never been an easy journey”
하지만 도입에서도 얘기했듯이 어떤 문제에 알맞는 네트워크를 디자인한다는 것은 결코, 절대로 쉬운 일이 아닙니다.
첫째로, 결정해야할 것들이 너무 많습니다. CNN을 예로 들어 얘기하자면, 어떤 종류의 레이어를 어떤 순서로 몇 개 배치할지, 각 레이어의 커널 사이즈와 필터 개수는 어떻게 할 지, 학습율은 어떻게 결정할 지 등등. 더욱이 좋은 네트워크를 디자인 했던 기존 연구자들은 그 동안의 수많은 연구 경험을 통해 얻은 통찰력에 기반해 온 경우가 많기 때문에, 네트워크 디자인에 대한 명확한 가이드라인도 얻기 힘듭니다.
둘째로, 네트워크가 제대로 디자인 되었는지를 알기 위해서는 이 네트워크를 학습시키고 테스트하는 과정을 거쳐야 합니다. 그런데 이 과정은 통상 짧게는 몇 시간, 길게는 몇 주 정도의 시간이 걸립니다. 가뜩이나 결정해야 할 것도 많은데 (즉, 결과를 확인해봐야 하는 샘플 수도 많은데) 결과 확인까지 이렇게 오랜 시간이 걸린다면, 최적의 네트워크 구조를 디자인하는 데 걸리는 시간은 기하급수적으로 늘어나게 됩니다.
이 논문에서 제안하는 방법은 위와 같은 문제점을 어느 정도 해결하고, 특히 학습-테스트 과정을 거치지 않고도 디자인한 네트워크의 성능을 알 수 있도록 해줍니다. 기본 아이디어는 간단합니다. LSTM (long short-term memory) 의 입력으로 네트워크 구조를 넣고 출력으로 그 네트워크의 성능을 받는 것입니다.
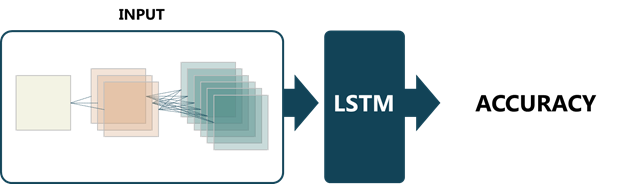
그림 1. 본 논문의 기본 아이디어

그림 2. 기존 연구와의 비교
기존 연구와의 가장 큰 차이점은 네트워크 구조 그 자체에 대한 특징 값만 가지고 네트워크 성능을 예측한다는 점입니다. 기존 연구의 경우, 정확도 곡선(x축은 학습 에폭이나 다른 파라미터 값이 될 것입니다)의 일부 값을 가지고 나머지 부분을 예측하는 식이었다면, 이 논문은 네트워크의 특징 값을 가지고 학습 에폭에 따른 정확도 곡선을 전부 예측해냅니다.
이를 구현하기 위해서는 1) 네트워크 구조를 LSTM에 넣을 수 있는 입력 형태로 어떻게 변환할 것인지 2) 학습 데이터를 어떻게 얻을 것인지가 먼저 해결되어야 합니다.
먼저, 네트워크 구조를 입력 형태로 변환시키기 위해서 ULC (unified layer code)라는 것을 만들었습니다. CNN은 특정 역할을 수행하는 레이어들이 겹쳐져 있는 모양입니다. 따라서, 어떤 레이어 하나에 대한 정보가 들어있는 데이터 덩어리가 순서대로 나열되어 있는 형태로도 CNN을 표현할 수 있습니다.
ULC에서는 레이어의 종류마다 라벨을 하나씩 지정하고 거기에 커널 크기와 채널 개수를 더해서 레이어에 대한 정보를 담은 벡터를 정의합니다. 특이한 부분은 채널 개수를 실수 값 그대로 사용하지 않고 입력으로 받은 채널 개수와 출력으로 내보내는 채널 개수의 비율로 표현합니다. 즉, 입력으로 받은 데이터의 채널이 32였고 현재 컨볼루션 레이어가 가지고 있는 필터 개수가 64라면 ULC 상에서는 채널 개수에 대한 값이 2로 저장됩니다. 또 커널이나 채널이 없는 경우에는 모두 1로 표기합니다.
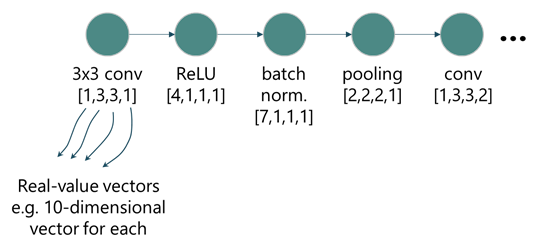
그림 3. 네트워크 구조를 실수 입력 값으로 변환하는 과정
ULC를 이용한 코딩을 거치면 CNN은 위 그림과 같이 레이어 종류, 커널 폭, 커널 높이, 채널 개수 비율의 네 가지 값을 가지는 데이터 덩어리들이 겹겹이 쌓여 있는 형태가 됩니다. 하지만 이런 불연속적인 저차원 벡터는 학습에 별로 적합한 형태가 아닙니다. 따라서 layer embedding이라는 과정을 통해 실수 값을 가지는 보다 고차원의 벡터로 변환합니다.
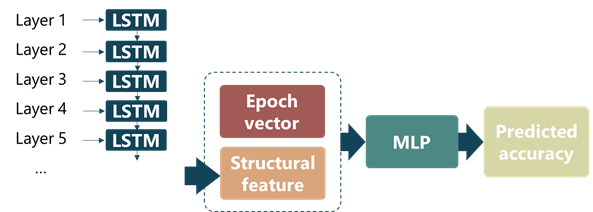
이렇게 얻어진 네트워크 구조에 대한 값들은 차례대로 LSTM에 입력으로 들어가게 되고, 네트워크 구조의 특징 값은 마지막 레이어까지 통과한 LSTM의 hidden state의 값으로 결정됩니다. 이 특징 값은 학습 에폭을 나타내는 epoch vector와 합쳐져서 MLP (multi-layer perceptron)에 입력으로 들어가고 이 MLP가 최종적으로 네트워크의 성능을 출력하게 됩니다.
여기까지 네트워크 구조를 어떻게 입력 형태로 바꾸고 이로부터 어떻게 출력을 얻어내는지 전체 과정에 대해서 살펴 보았습니다. 이제 LSTM과 MLP를 학습시키기 위한 학습 데이터를 구하는 방법에 대해 알아보겠습니다.
학습 데이터를 구하는 것이 따로 논의할 만한 문젯거리가 되는 이유는, 앞에서도 얘기했듯이 CNN을 디자인하기 위해서 결정해야 할 것이 아주 많기 때문입니다. 즉, 우리가 입력으로 받는 데이터의 범위가 아주 넓기 때문입니다. 이런 입력에 대해 정확한 출력을 얻기 위해서는 우리가 가지고 있는 학습 데이터 역시 가능한 한 넓은 범위에 고루 분포해 있어야 합니다.
이 논문에서는 위의 문제를 조금 다른 방향에서 풀어 나갑니다. 넓은 범위의 학습 데이터를 만드는 대신, 입력으로 많이 들어올 법한 영역에서 학습 데이터를 뽑습니다. 일반적으로 CNN을 디자인 할 때, 구조가 비슷한 레이어들의 덩어리를 여러 개 쌓는 방식으로 접근한다는 점에 착안한 것이죠. 이 접근 방식의 유효함은 기존 연구에서도 어느 정도 증명된 바 있습니다.
이를 위해서 네트워크 블록이라는 개념을 정의하고 여기에 최대 10개의 레이어, 그 중에서도 컨볼루션 레이어는 최대 3개까지만 들어가도록 제한합니다. 최종적인 네트워크 구조는 미리 정의된 CNN의 스켈레톤 구조를 랜덤하게 생성된 네트워크 블록들이 채우는 형식으로 정의됩니다.
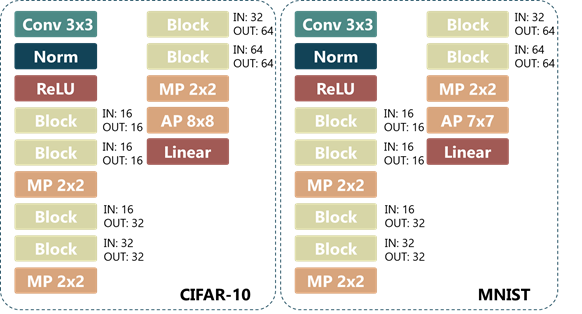
네트워크 블록 내부를 결정하는 것은 마르코프 체인(Markov chain)을 기반으로 합니다. 즉, 직전 레이어의 성질만을 고려해서 다음 레이어를 결정하게 됩니다. 레이어를 쌓을 때는 convolution – batch normalization – activation – pooling 과 유사한 순서로 진행하는 것이 유리하다고 알려져 있습니다. 따라서 저자들은 이런 경험적 사실을 토대로 어떤 한 종류의 레이어 다음에 어떤 종류의 레이어가 따라올 지 그 확률을 정의한 전이 행렬을 만듭니다.
네트워크 블록은 처음에 컨볼루션 레이어로 시작해 위의 전이 행렬을 기반으로 레이어를 쌓아갑니다. 이 때, 컨볼루션 레이어 직후마다 0.6의 확률로 batch normalization이 들어갑니다. 그리고 커널 크기, 채널개수와 같은 레이어의 파라미터들은 랜덤하게 결정됩니다.
그림 5에서 잠깐 나왔지만 제안한 방법에 대한 검증은 CIFAR-10과 MNIST, 두 개의 데이터베이스에 대해서 이루어집니다. 위의 방법으로 CIFAR-10에 대해서는 학습과 테스트 데이터를 약 800개씩, MNIST에 대해서는 약 400개씩 만들어서 진행했습니다. 여기에서는 검증 결과에 대해 다루지 않겠지만 기존의 방법 대비 MSE (mean-square-error), Kendall’s tau, 결정계수 측면에서 더 좋은 결과를 얻었습니다. 특히 특징 분석을 통해 LSTM을 이용해 얻은 특징이 네트워크의 성능에 대한 지표가 될 수 있음을 보였습니다.
그럼에도 불구하고 몇 가지 지적할 만한 점은 눈에 띕니다.
저자들도 논문에서 언급했듯이 네트워크의 성능에 영향을 미치는 다른 파라미터에 대한 고려가 없다는 점이 가장 아쉽습니다만, 이 부분은 추후 보완해 갈 계획이라고 합니다.
그리고 테스트 데이터에서도 네트워크 스켈레톤의 구조를 통일시켜버렸는데, 제안하는 방법의 신뢰도를 정확하게 측정하기 위해서는 보다 다양한 형태의 테스트 데이터를 사용했어야 하지 않나 싶습니다. 또, 학습 에폭에 따른 성능 변화는 사실 어느 정도 뻔한 내용인데, 굳이 학습 에폭에 대한 정확도 곡선을 가지고 할 필요가 있었나 하는 생각도 듭니다.
안녕하세요, 재미있는 논문 소개글 잘 읽었습니다. GRU로의 응용 결과도 궁금해지네요.
아참, 이런말 드리긴 조금 어렵긴 한데, arxiv라고 할지라도 저작권 이슈는 한번 신경쓰셔야 합니다. arxiv에 올려진 논문들은 대체로 arxiv가 Non-exclusive license to distribute (독점적이지 않은 배포권)을 가집니다. 오픈 억세스 저널과는 다릅니다.
https://arxiv.org/licenses/nonexclusive-distrib/1.0/license.html
arxiv에 논문이 있더라도 저작권 자체는 저자에게 있는 경우가 대다수이기 때문에, CC (여기에서 CC-NC 등은 제외)가 잘 걸려있는지, 아니면 배포권만 양도된 것인지 확인하지 않으면 추후 문제가 생길 여지가 있습니다. 특히 컴퓨터사이언스 분야에서는 저자들이 arxiv에 먼저 올리고 저널이나 학회에 등록하는 경우가 많은데, 이 경우, 저자의 저작권이 저널 측에 copyright transfer가 되면 분쟁 소지가 생길 가능성이 있습니다. 특히 스팀잇 같이 영리와 관련되고 일주일 뒤 수정 삭제가 어려운 플랫폼에서는요.
제가 노파심에서 드리는 말이니, 한번쯤 고민해보셔도 괜찮을 것 같습니다. 좋은 해석 잘 읽었습니다.
감사합니다. 글 내용은 제가 논문을 읽고 요약, 정리한 것이고 해당 논문의 그림이나 표 등의 자료도 사용하지 않았기 때문에 저작권 문제는 없는 것으로 이해하고 있습니다. 혹시 문제가 되는 부분 있으면 알려주시면 감사하겠습니다.
네. 신경 많이 쓰신 것 알고 있습니다. 정성들여 작성하신 것에 깜짝 놀랐던걸요.
제 짧은 지식에 의하면 (제가 틀릴 수도 있습니다), 논문의 핵심 아이디어나 전개 방식을 차용하여 어떤 글을 작성하는 경우에 2차적 저작물에 해당할 수 있고, (물론 2차적 저작물도 그에 대한 저작권이 생기지만, 제 짧은 지식에 의하면 원저작자가 더 앞서는 것으로 압니다.)
CC가 걸려있지 않은 경우, 그리고 저널이나 학회 억셉 전에 아직 정식으로 copyright transfer 되지 않은 경우에도, 보상이 가시적으로 보이지 않는 일반적인 SNS와 다르게, 이 곳에서 공정이용(fair use)으로서 이용이 가능한지에 대해서는 사실 사람들마다 의견이 분분할 수도 있을 것 같아 드렸던 말이었습니다. (Reddit의 ML포럼 같은 곳과 여기는 성격상 좀 차이가 있어 보이기도 하고, 학회나 저널에서는 우수한 연구 결과를 저작권을 바탕으로 자신들이 직접 먼저 홍보하고 싶어할 수도 있으니까요. 시기 상의 문제이기도 한데, 사실 저도 잘 모르겠습니다. 그렇다고 페이퍼의 핵심적인 내용을 공유할 수없는 것이냐. 하면 그것도 아닌 것 같고요.) 저널이나 학회는 특히 이러한 이슈에 민감하니까요... (저는 이러한 이슈를 생각하면 골치가 아파, 저 스스로는 그냥 CC 위주로 적는게 낫겠다고 판단하고 있기는 합니다.)
충분한 검토를 거치셨고, 그 판단 하에 저작권 문제가 없는 것으로 이해하고 계시다면, 제가 오히려 괜한 걱정을 끼친 것 같습니다. 더불어 디테일한 내용을 봐서 좋았던 만큼, 꾸준히 좋은 지식 나눔글을 보고 싶은 마음에, 노파심에서 말씀드린 것이니 혹여나 기분 상하셨다면 사과의 말씀 올립니다.
아닙니다. 저도 여러모로 조심하려고 하고 있는데 다시 한 번 상기시켜주셔서 감사합니다.
멋진 글 감사드립니다. Markov-Chain을 사용해서 코인 트레이딩에 있어서의 알고리즘을 를 구현해보고자 하는데, 여러가지로 좋은 참조를 하게 되네요.
읽어주셔서 감사합니다.
저의 관심 분야인 딥러닝 관련 포스팅을 스팀에서 볼 수 있으니 반갑네요! 좋은 글 많이 부탁드립니다 :)
감사합니다. 흥미로운 논문이 있으면 종종 리뷰하려고 계획하고 있습니다.
좋은 글 감사합니다. 이런 전문 지식글 너무 좋습니다. 보팅 및 팔로우 하고 갑니다. 맞팔 부탁드립니다. ^^
감사합니다. 맞팔 했습니다.
좋은 리뷰 감사합니다. 학습 전에 성능을 예측할 수 있다는 사실은 상당히 흥미롭네요.
감사합니다. 제대로 정립만 된다면 현장에도 큰 도움이 될 연구 내용인 것 같습니다.
좋은 글 잘 보고 갑니다. 최전선의 흥미로운 진행방향을 일부나마 살펴볼 수 있어 너무나도 좋습니다. 앞으로도 리뷰 글 계속 기대하겠습니다. ^^
감사합니다.
앞으로도 좋은 포스팅 기대하겠습니다!
2018년 소망 릴레이의 다음 주자로 지목되셨습니다 :) https://steemit.com/kr/@justfinance/2018-3 글 참조해주세요!
감사합니다. 기회 봐서 조만간 써보도록 하겠습니다.