이전 시간에는 웹서버와 통신해서 파일로 저장하는 것을 다루었습니다.
이전글 > [Python] 파이썬 웹 크롤링 봇 만들기 -2- First Scraper
이번에는 실전 예제로, Coindesk 사이트를 크롤링 해보겠습니다.
Feedparser
뉴스 사이트와 같은 곳에서 RSS feed 를 제공해주고 있는 곳이 있습니다.
- RSS feed 란? RSS(Really Simple Syndication) 같은 새 기사들의 제목만, 또는 새 기사들 전체를 뽑아서 하나의 파일로 만들어 놓은것.
Coindesk의 RSS 주소는 https://www.coindesk.com/feed/ 입니다.
웹브라우저에서 위의 링크를 열어보면 아래와 같은 문자열만 나옵니다.

Python 에서 이런 형태의 Text를 처리해주는 라이브러리가 있습니다. 심지어 Requests 로 웹페이지를 요청 할 필요 가 없습니다. 이유는 아래에서 보여드리겠습니다.
import feedparser
url = "https://www.coindesk.com/feed/"
feedparser.parse(url)
위의 코드를 Jupyter notebook 에서 바로 출력하면 아래와 같은 결과가 나옵니다.
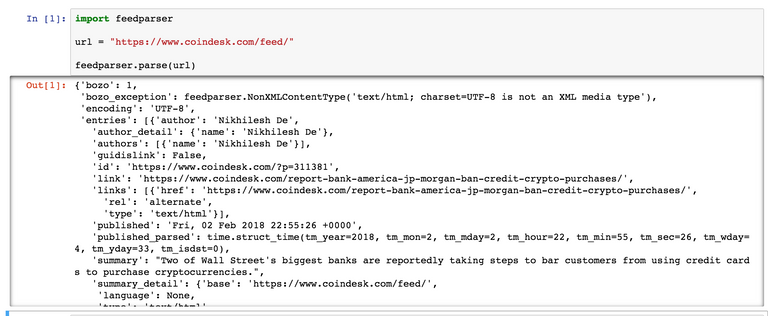
만약 아래와 같은 에러가 발생하면, 이것은 feedparser 라이브러리가 설치되지 않아서 생기는 문제입니다.
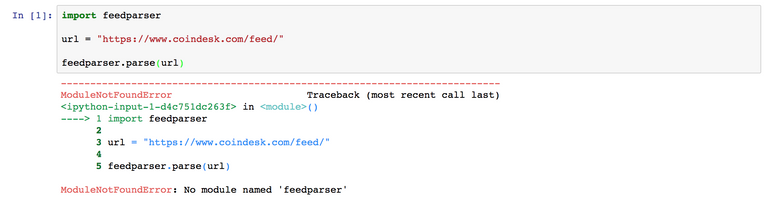
!pip install feedparser
Jupyter notebook에서는 "!+명령어" 로 Shell 명령어를 바로 실행시킬 수 있습니다. 편리하죠!
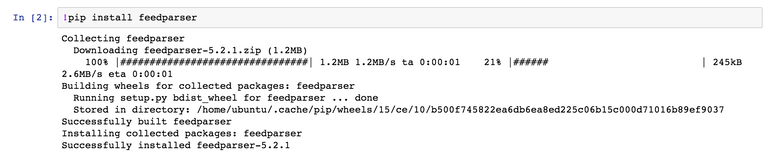
Coindesk
이제 출력결과를 feed 객체에 넣고 들여다 보겠습니다.
feed = feedparser.parse("https://www.coindesk.com/feed/") #url 객체 대신 직접 넣어도 됩니다.
feed
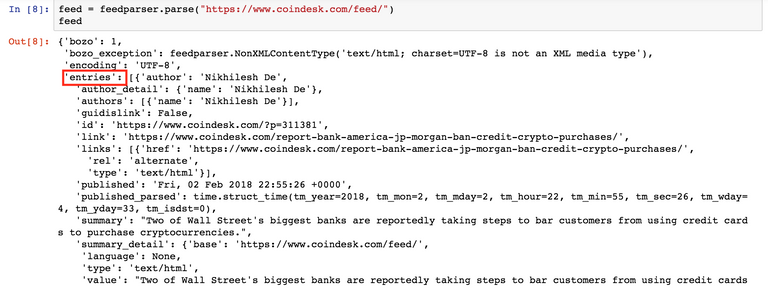
feed 결과는 Python Dictionary 객체로 저장되어 있습니다. 'entries' 키안에 우리가 원하는 Coindesk의 새글들에 대한 정보가 담겨 있습니다. 보통 entries 키에 새글에 대한 정보가 담겨져 있습니다. Coindesk가 아닌 다른 뉴스사이트에서도 그대로 사용하여 도 비슷한 결과를 가져올 수 있습니다.
len(feed['entries'])
# 출력결과는 20 입니다.
Coindesk의 feed에서 제공하는 새 글(post) 정보는 총 20개입니다. 다른 뉴스사이트에서는 제공하는 entries 개수가 다를 수 있습니다.
feed['entriees][0] # 첫번째 Post 를 호출해봅니다.
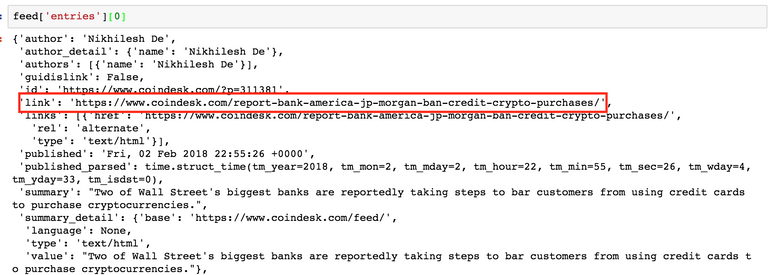
entries의 link 키가 해당 글의 URL 주소입니다. 그 위에 id 도 있는데, 보통 뉴스사이트에서는 link에 해당 뉴스의 링크가 들어가져 있습니다.
이제 entries 에 있는 모든 url 들을 가져와 보겠습니다.
import feedparser
feed = feedparser.parse("https://www.coindesk.com/feed/")
coindesk_urls = [] #coindesk url들을 가져와서 저장시켜줄 객체
for entry in feed['entries']:
coindesk_url.append(entry['link']) #coindesk_url list에 entries에 들어 있는 link 의 string들을 추가한다.
이제 출력 결과를 살펴보면, 짜잔~ Coindesk의 메인페이지에 보이는 최신 뉴스들(20개)의 url들을 가져왔습니다.

이번 스터디 마지막과정이 새 글 알림을 Telegram으로 보내는 것인데요, 새글인지 아닌지를 확인하는 과정은 마지막에 구현하기로 하고, 지금은 feedparser로 가져온 결과를 파일로 저장만 해보겠습니다.
for url in coindesk_url:
with open("coindesk_news.txt", "a", encoding="utf8") as f:
f.write(url+"\n")
아무런 에러 메시지가 나오지 않았다면 성공한 것입니다.
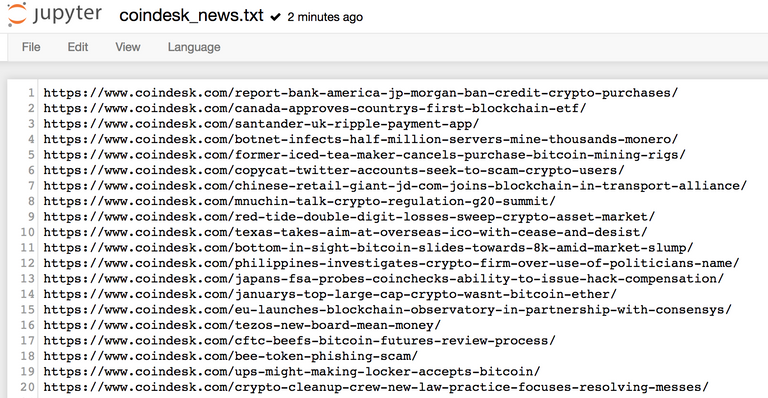
Jupyter notebook 메인화면으로가서 현재 실행하고 있는 노트북 파일과 동일한 폴더에 coindesk_news.txt 파일이 생성되어 있습니다.
Jupyter notebook에서 바로 파일을 열어보면 아래와 같은 결과가 나올 것입니다.
다음주에는 Coindesk 뉴스의 본문을 추출해보는 과정을 해보도록 하겠습니다.