
Training deep neural networks regularly is a never-ending challenge in artificial intelligence(AI) projects. If training can be overwhelming for simple machine learning scenarios, can you imagine the efforts for systems such as self-driving vehicles that need to perform a large variety of tasks in real time in constantly-changing environments? Recently, Alphabet’s subsidiaries Waymo and DeepMind partnered to find a more efficient process to train self-driving vehicles algorithms and their work took them back to one of the cornerstones of our history as species: evolution.
Self-driving vehicles can be categorized as some of the most complex AI systems ever built. They need to operate safely in highly populated cities, they work in incomplete environments in which unknown factors appear real time, they need to perform a large number of intelligence tasks cohesively as a single system and the list of challenges never seems to end. Implementing training strategies for models in operating in such complex environments can be nothing short of a nightmare. Not surprisingly, self-driving vehicles have forced AI researchers to reimagine the traditional approaches to training deep neural networks and come up with innovative alternatives.
From Traditional to Evolutionary Training
In general, the current generation of deep neural networks learn by trial and error. A traditional machine learning systems starts by being trained on a specific dataset and then is presented with a task relevant to that data and it needs to grade how well it can perform the task. This process is conducted numerous times and the network accumulates knowledge by continually adjusting the grades. The levels of adjustments are commonly known as the “learning rate” and the goal of the model is to regularly increase that metric without killing the performance of the network.
Applying traditional training processes in self-driving vehicles architectures doesn’t seem like a great fit. Any self-driving vehicle can contain hundreds of models that are operating concurrently and interacting with virtually unknown information. Waymo has been experimenting with AutoML techniques to improve the design of neural networks and their time to market. Still, training remains a challenge. The typical approach to address training in a complex system such as a self-driving vehicle would be to continually monitor all models and periodically eliminate the weakest performers, freeing resources to train new networks from scratch with new random hyperparameters. While effective, this type of process remains very labor intensive. Self-driving vehicles models require better training processes and the answer might be in evolution.
Population Based Training
Evolutionary Epistemology is a naturalistic approach to epistemology, which that applies the concepts of biological evolution to the growth of human knowledge. Conceptually, evolutionary epistemology argues that units of knowledge evolve by trial-error learning and natural selection. Recently, DeepMind applied this idea of evolutionary knowledge to deep neural networks formulating a training technique known as population-based training(PBT). As a training method, PBT combines the advancements of two of the most popular approaches to hyperparameter optimization: random search and hand-tuning.
In random search scenarios, a population of models are trained independently in parallel and at the end of training the highest performing model is selected. Typically, this means that only a small fraction of the population will be trained with good hyperparameters while the rest will be trained with bad ones, wasting computer resources.
The hand-hunting approach is based on sequential optimization processes. ) Sequential optimization requires multiple training runs to be completed (potentially with early stopping), after which new hyperparameters are selected and the model is retrained from scratch with the new hyperparameters. This is an inherently sequential process and leads to long hyperparameter optimization times, though uses minimal computational resources.
PBT uses a similar approach to random search by randomly sampling hyperparameters and weight initializations. Differently from the traditional approach, PBT runs each training asynchronously and evaluates its performance periodically. If a model in the population is under-performing, it will leverage the rest of the model population and replacing itself with a more optimal model. At the same time, PBT explores new hyperparameters by modifying the better model’s hyperparameters, before training is continued. The PBT process allows hyperparameters to be optimized online, and the computational resources to be focused on the hyperparameter and weight space that has most chance of producing good results. The result is a hyperparameter tuning method that while very simple, results in faster learning, lower computational resources, and often better solutions.
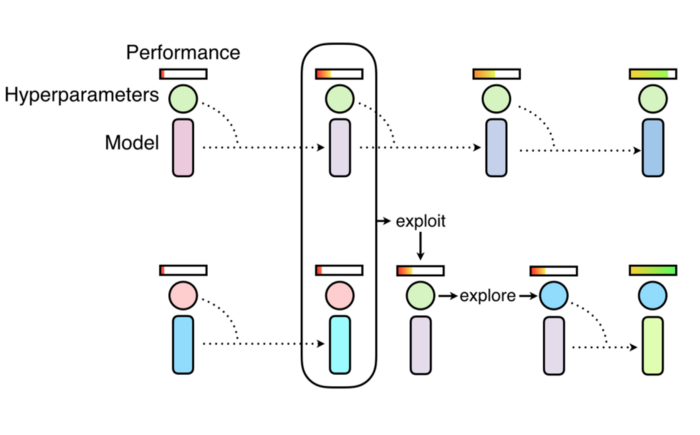
The following animation shows how PBT works in terms of knowledge building. The goal of PBT is to discover the most efficient training regime for a deep neural networks. PBT launches periodic competitions between models with different hyperparameter configurations. The losers of each competition are removed from the training pool and the process repeats itself with the winner models.
PBT at Waymo
PBT-based training seems like an interesting choice for the training of self-driving vehicle models. DeepMind and Waymo collaborated on using PBT on diverse scenarios including the training of a deep neural network that generates boxes around pedestrians, bicyclists, and motorcyclists detected by our sensors–named a “region proposal network.” The aim was to investigate whether PBT could improve a neural net’s ability to detect pedestrians along two measures: recall (the fraction of pedestrians identified by the neural net over total number of pedestrians in the scene) and precision (the fraction of detected pedestrians that are actually pedestrians, and not spurious “false positives”).
The initial experiments showed PBT’s efficiency to distribute resources according to the performance of the best neural networks. In the aforementioned experiment, PBT models were able to achieve higher precision by reducing false positives by 24% compared to its hand-tuned equivalent, while maintaining a high recall rate. PBT also used about half of the computational resources consumed by traditional training processes. The results do not come without some concerns. Some data showed that PBT’s relentless optimization are not a good fit for neural networks that perform better over long periods of time.
Self-driving vehicles can be considered one of the toughest environments for any deep learning method. The application of evolutionary knowledge techniques such as PBT to heterogenous learning tasks like autonomous driving is extremenly fascinating. After the initial experiments, Waymo has expanded the test of PBT to different scenarios that can enable the creation of more capable self-driving vehicles.
Originally written by Jesus Rodriguez
Congratulations @didi2708! You received a personal award!
You can view your badges on your Steem Board and compare to others on the Steem Ranking
Vote for @Steemitboard as a witness to get one more award and increased upvotes!