
Hello Aliens!
Today I'm going to show you some amazing improvements in the area of AI-based voice cloning. For an instance, if someone wanted to clone my voice, they need hours and hours of my voice recordings to clone it with previously existing techniques.
But the question today is, if we had even more advanced methods to do this, how big of a sound sample would we really need for this? Do we need a few hours? A few minutes? The answer is NO!! Not at all.
Let’s listen to a couple examples. Here's the Link from where you can check it out.
.png)
Isn't it incredible. The timbre of the voice is very similar, and it is able to synthesize sounds and consonants that have to be inferred because they were not heard in the original voice sample. This requires a certain kind of intelligence and quite a bit of that.
Model Overview
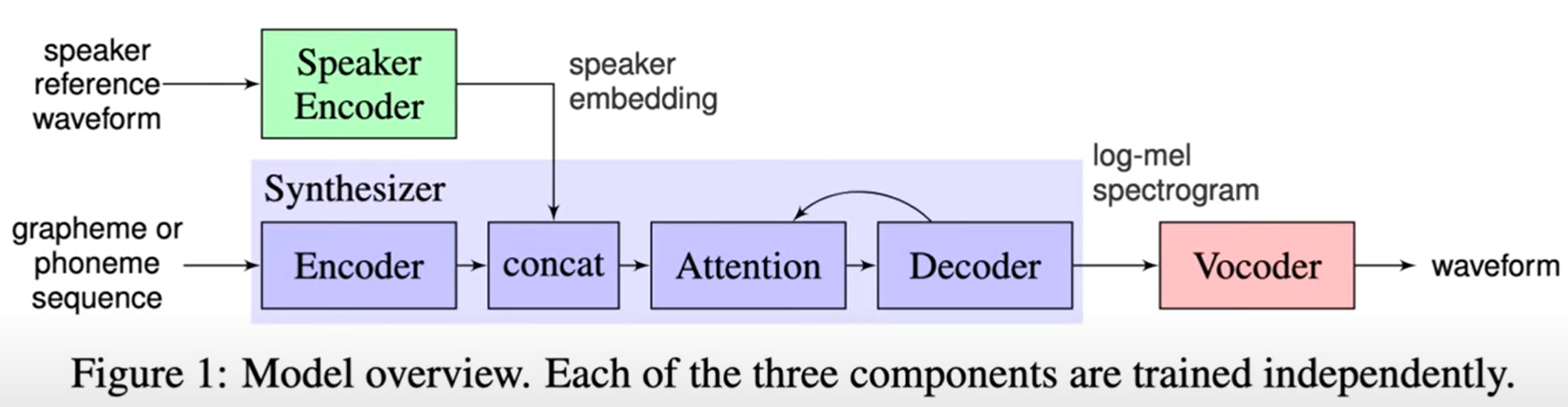.png)
So, while we are at that, how does this new system work? Well, it requires three components.
- One, the speaker encoder is a neural network that was trained on thousands and thousands of speakers and is meant to squeeze all this learned data into a compressed representation. In other words, it tries to learn the essence of human speech from many many speakers. To clarify, I will add that this system listens to thousands of people talking to learn the intricacies of human speech, but this training step needs to be done only once, and after that, it was allowed just 5 seconds of speech data from someone they haven’t heard of previously, and later, the synthesis takes place using this 5 seconds as an input.
.png)
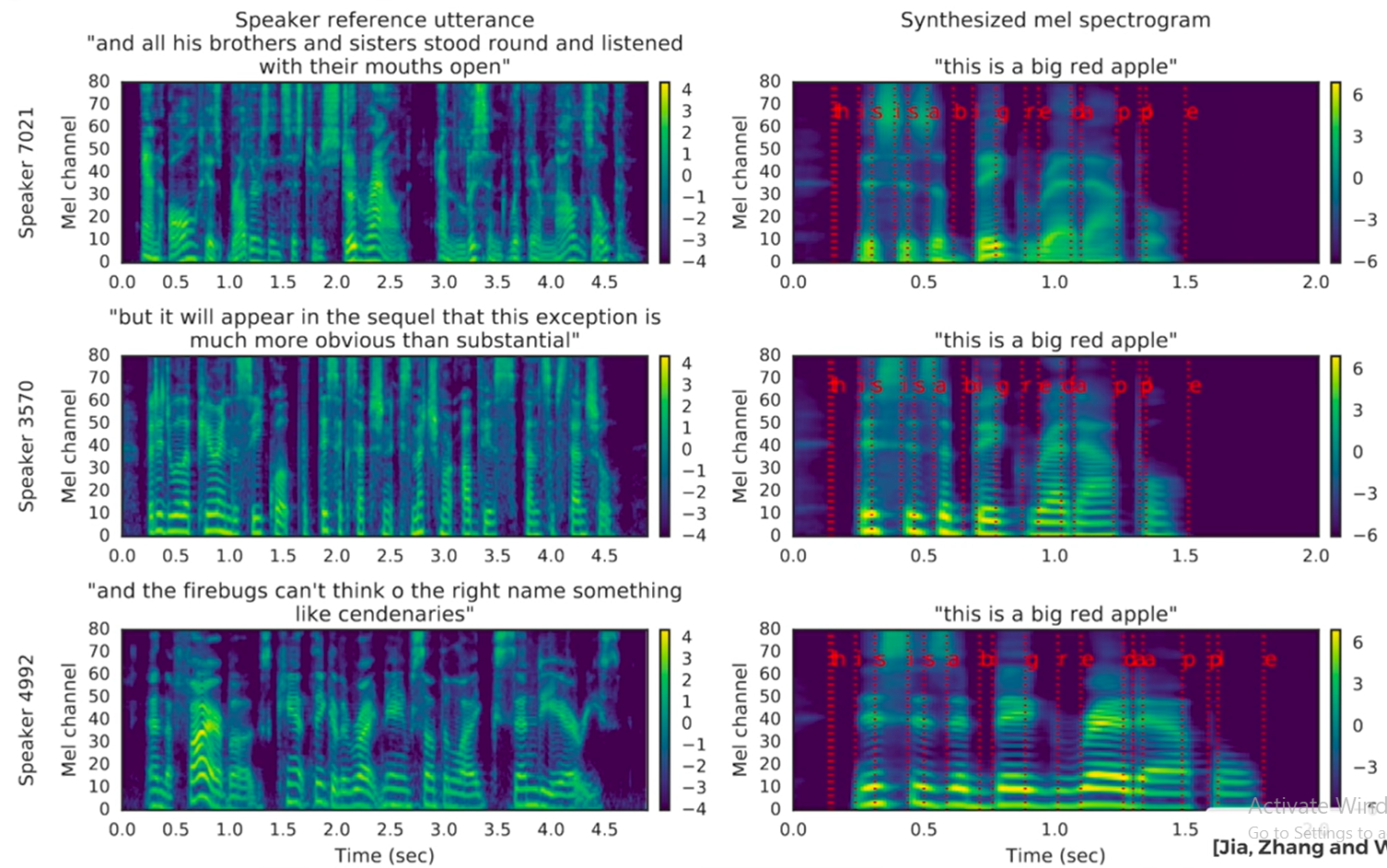
Two, we have a synthesizer that takes text as an input, this is what we would like our test subject to say, and it gives us a Mel Spectrogram, which is a concise representation of someone’s voice and intonation. The implementation of this module is based on DeepMind’s Tacotron 2 technique, and here you can see an example of this Mel spectrogram built for a male and two female speakers. On the left, we have the spectrograms of the reference recordings, the voice samples if you will, and on the right, we specify a piece of text that we would like the learning algorithm to utter, and it produces these corresponding synthesized spectrograms.
But, eventually, we would like to listen to something, and for that, we need a waveform as an output. So, the third element is thus a neural vocoder that does exactly that, and this component is implemented by DeepMind’s WaveNet technique.
This is the architecture that led to these amazing examples. So how do we measure exactly how amazing it is? When we have a solution, evaluating it is also anything but trivial.
In principle, we are looking for a result that is both close to the recording that we have of the target person, but says something completely different, and all this in a natural manner. This naturalness and similarity can be measured, but we’re not nearly done yet, because the problem gets even more difficult.
For instance, it matters how we fit the three puzzle pieces together, and then, what data we train on, of course, also matters a great deal.
The paper contains a very detailed evaluation section that explains how to deal with these difficulties. The mean opinion score is measured in this section, which is a number that describes how well a sound sample would pass as genuine human speech. And I haven’t even talked about the speaker verification part, so make sure to have a look at the paper. So, indeed, we can clone each other’s voice by using a sample of only 5 seconds.
Thanks for Reading and for your generous.