In my last post I showed how to configure the HTTP API of XMRIG and query it with curl, now I will use my Raspberry Pi 2 Model B to query my rigs and store the retrieved data in an InfluxDB.
Install InfluxDB
InfluxDB is an time series database develeped by InfluxData. It is written in Go and glorified for being a single binary and optimized for fast, high-availability storage and retrieval of time series data from different source like IoT devices, application metrics or network operation monitoring. It provides a SQL like querie language and differnt accees like API calls or CLI.
Add the InfluxDB repository to the rpi
Dependening on the version of Debian is running on your Raspberry Pi different Urls are necessary to be added to the respository of the paket manager. The following code will add Url according to the used Debian version.
wget -qO- https://repos.influxdata.com/influxdb.key | sudo apt-key add -
source /etc/os-release
test $VERSION_ID = "7" && echo "deb https://repos.influxdata.com/debian wheezy stable" | sudo tee /etc/apt/sources.list.d/influxdb.list
test $VERSION_ID = "8" && echo "deb https://repos.influxdata.com/debian jessie stable" | sudo tee /etc/apt/sources.list.d/influxdb.list
test $VERSION_ID = "9" && echo "deb https://repos.influxdata.com/debian stretch stable" | sudo tee /etc/apt/sources.list.d/influxdb.list
test $VERSION_ID = "10" && echo "deb https://repos.influxdata.com/debian buster stable" | sudo tee /etc/apt/sources.list.d/influxdb.list
sudo apt-get update
Install InfluxDB
sudo apt-get install influxdb
Start service provided from the installation package
sudo service influxdb start
Configure InfluxDB
InfluxDB come with multiple configuration options and default configuration can beviewed with influxd config. The service use the configuration file stored in /etc/influxdb/influxdb.conf, but most of the options are commented out. InfluxDB uses for uncommented options the defaults settings.
In order to enable HTTP requests with configuration of the service needs to be changed. For this remove the # for options enabled, bind-address and auth-enabled in configuration file.
To change the configuration of the service open it with a text:
sudo nano /etc/influxdb/influxdb.conf
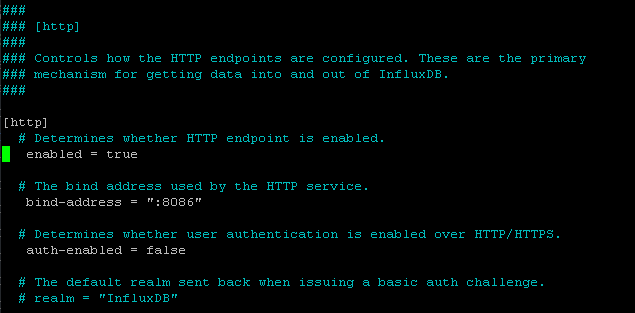
After that restart the service so the change can be take effect.
sudo service influxdb restart
Connect to InfluxDB instance
The backend is now setup now for access the data managed by the service an additional package is necessary. For access the databases in CLI install influxdb-client.
sudo apt-get install influxdb

Access the databases
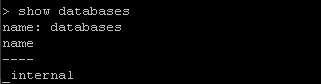
The managed databases by InfluxDB are accessable by
show databases
Create database for the metrics
The metrics of the rigs shall be stored in their own database called rigs. Databases are created with CREATE DATABASE rigs.

Test database
Before you can insert or select data, you have to select on databases with use rigs.
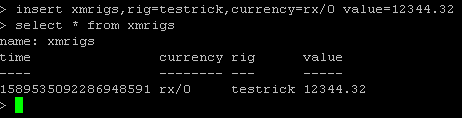
InfluxDB provides a SQL like language and INSERT statement like this:
insert xmrigs,rig=testrick,currency=rx/0 value=12344.32
This statement will create table called xmrigs with attributes rig, currency and the measure value 12344.32. The time stamp will be automatically added by the database.
The data can queried by:
select * from xmrigs
Collect metrics from XMRIG rigs
The data will be collected by a script for each rig, which queries the rig HTTP API, parse HTTP result and store the date in database. The data will be queried periodcally by cronjobs.
Query rigs API
First I created the script with collecting the data from the XMRIG HTTP API, parse the resulting JSON, and extract with jq the fields I need. XMRIG offers diffrent endpoints, I will use /1/summary. From this endpoint I will collect the worker-id, algo and first entry the hashrate table.
#collect data from API
json=$(curl -X GET -H "Content-Type: application/json" -H "Authorization: Bearer wWhearsgoL4w6zPT" http://x.x.x.x:9971/1/summary)
#extract hashrate, worker_id, currency
hashrate=$(echo $json | jq -r '.hashrate.total[0]')
workerid=$(echo $json | jq -r '.worker_id')
currency=$(echo $json | jq -r '.algo')
Store Data in InfluxDB
After that I extended that script with a call to the HTTP API of InfluxDB. For writing data, the endpoint /write is used. It is uses as query option the database you want to write to and takes as binary data the data to write.
curl -i -XPOST 'http://localhost:8086/write?db=rigs' --data-binary "xmrigs,rig=$workerid,currency=$currency value=$hashrate"
Create cronjobs for data retrieval
The periodacal execution of the retrieval script, I will do with cronjobs. The metrics shall be queried every minute, which 5 * for each script call. To open the crontab call crontab -e.

After some time the database should be filled with some entries from different rigs.
Now the database is setup and filled with data on timely manner. Installing Grafana and creating a dashboard for the data I will do in another post.
Please up vote, comment and resteem my post. If you like this please donate to 42D2sPUubqCCqK3MD8BnDDSyjgNqbrLH6HcHXrZWaqYZfUqyoDcRsfTQNp345N1NSDLr8qBJ5QqjQ4V95nix6qH9Je8BX2U
Thank you so much in advance.
Great work.
Yay!
Your post has been boosted with ESTM. Keep up the good work!
Dear reader, Install Android: https://android.esteem.app, iOS: https://ios.esteem.app mobile app or desktop app for Windows, Mac, Linux: https://desktop.esteem.appLearn more: https://esteem.app Join our discord: https://discord.me/esteem
Congratulations @master-lamps! You have completed the following achievement on the Hive blockchain and have been rewarded with new badge(s) :
You can view your badges on your board And compare to others on the Ranking
If you no longer want to receive notifications, reply to this comment with the word
STOPDo not miss the last post from @hivebuzz:
Support the HiveBuzz project. Vote for our proposal!