
Hive has seen tremendous growth since the previous hardware changes (minor, major) of techcoderx.com API node, but that also means significant increase in system requirements to run them. Hence, it's time for another hardware update.
Running v1.27
Since my previous post, Hive went through two hardforks. All my nodes as of now are up-to-date with the latest versions of their respective softwares, mainly hived v1.27 (26f38cd2), hivemind v1.26.1, haf (dd4e984e) and hafah (0bfcf91f).
For the record, these are my first HF26 and HF27 blocks respectively.
API node upgrades
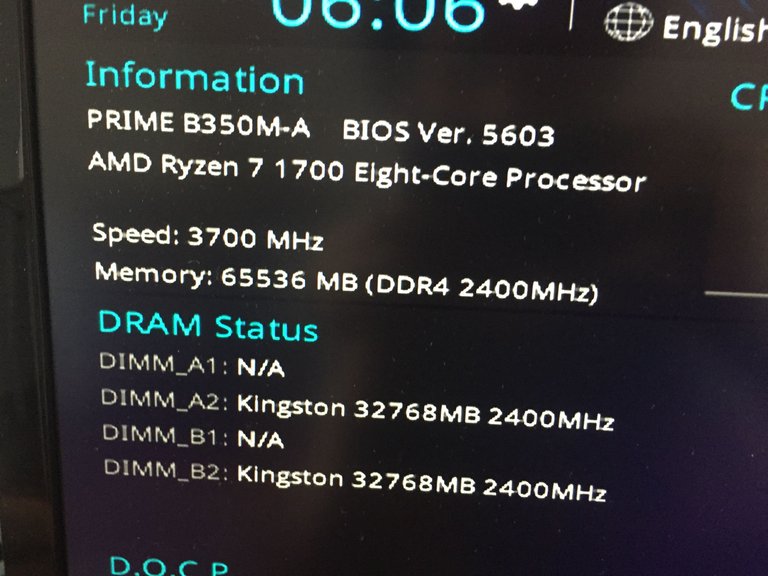
For $189, I have replaced both the 2x8GB and 2x16GB RAM kits that were previously in the server with two 32GB Kingston Fury DDR4-3200 C16 modules, totalling 64GB. These 32GB modules aren't officially supported by the CPU nor the motherboard at all, however it managed to boot and run well with XMP enabled.
With this, the experience of using the API node on frontends such as PeakD is so much better as PostgreSQL will actually make better use of the indexes for many queries.
In theory, it means I could add another 2 identical modules for a total of 128GB RAM if I have the budget to do so.
 |  |
|---|
Hive API database storage have grown a lot especially with the introduction of HAF, it also means an increase in NVMe storage required to run one.
I have added a PNY CS3040 2TB drive to the now RAID 0 ZFS pool containing the PostgreSQL database, which cost me $180. The boot drive is now the 2TB Crucial MX500 which also stores the compressed block_log file.
 |  |
|---|
The new 4TB ZFS pool is expected to fill up in approximately 4 years at current blockchain growth.
Witness node changes
I have moved the block producing node from Privex to an Intel NUC (pictured below) with the following specs:
Barebones Intel NUC11TNHi5 mini PC
Intel Core i5-1135G7 4C8T CPU
64GB (2x32GB) Kingston DDR4-3200 C22 RAM (KVR32S22D8/32)
PNY CS3040 2TB NVMe SSD
 |  |  |
|---|
This node runs on a VPN provider that is different from the API node. Basically they have two different public IP addresses, similar to multiple Hive nodes running in a single datacenter LAN (looking at Hive node operators who use Hetzner 👀) but at a much smaller scale. I'm doing this for 3 main reasons:
1. Cost
Instead of paying a monthly fee to rent a server or a colocation which only makes sense for higher-ranked witnesses, there's the initial hardware purchase ($820 total for this NUC) and the power costs to run it (no more than 20W).
The cost savings is greater if you already have an unmetered network connection as there are no additional costs on that front.
2. Actually getting to choose and own my hardware
Colocation aside, I actually own my hardware that I run my Hive nodes on. Not only there are no significant monthly fees, I get to repurpose it when it is time to do so (i.e. when shared_memory.bin exceeds 64GB max allowed memory).
On top of that, I get to pick the hardware rather than be constrained to what the providers offer, which could mean better hardware.
3. Decentralization
This is the biggest one. Being located in SE Asia where node count is very low if there is even one, the block time offsets are noticeably higher than nodes in US/EU (although it has improved since HF26). This should help the geographical diversity of Hive nodes for both API and seed nodes without the high monthly cost of colocation.
Due to potentially lower uptime (>99% instead of >99.9% on datacenters), I can only recommend this for lower ranked witnesses (below active rank 50) and/or non-producing seed/backup/broadcast nodes.
Witness performance
Current rank: 75th (active rank 71th)
Votes: 7,749 MVests
Voter count: 282
Producer rewards (7 days): 1.264 HP (yes, only one block in HF27 so far)
Producer rewards (30 days): 230.642 HP
Missed blocks (all-time): 29
Server resource statistics
hived (v1.27, 26f38cd2, all plugins)
block_log file size (compressed): 348 GB
block_log.artifacts file size: 1.6 GB
shared_memory.bin file size: 21 GB
HAF db
Output of SELECT pg_size_pretty( pg_database_size('block_log') );
Database size: 3,123 GB
hivemind (v1.26.1, 28f86d5a)
Output of SELECT pg_size_pretty( pg_database_size('hive') );
Database size: 544 GB
Overall Postgres database
RAM usage: 20.9 GB
Compressed disk usage: 1.5 TB

Great post and great work. You should be higher ranked.
I was thinking of running my witness node on a NUC.
Congratulations @techcoderx! You received a personal badge!
You can view your badges on your board and compare yourself to others in the Ranking
Check out the last post from @hivebuzz:
Support the HiveBuzz project. Vote for our proposal!